

Are you the author? Sign in to claim
Claude Code skill: Multi-agent adversarial review panel — 4-6 AI reviewers debate your code/plans, then a supreme judge


![]()
4–6 AI reviewers independently evaluate your code, plan, or docs, debate each other's findings, then a judge resolves disagreements. A Claude Code plugin that orchestrates structured multi-stance review. Each run costs roughly $3–$20 in Opus tokens and takes 6–15 minutes — built for high-stakes reviews, not routine code review.

▶️ Play the interactive version — pause, replay, jump to any stage. Your code/plan journeys Gather → Review → Debate → Verify → Adjudicate → Report. (static pipeline diagram)
Runs only on Claude Code surfaces (CLI, IDE extension, Desktop "Code" tab) and the Claude Agent SDK. Does not work on claude.ai web chat or the raw Anthropic API — see Surfaces & Requirements.
claude plugin marketplace add wan-huiyan/agent-review-panel
claude plugin install roundtable@agent-review-panel
Restart your Claude Code session — skills load at session start.
/plugin marketplace add wan-huiyan/agent-review-panel
/plugin install roundtable@agent-review-panel
Same effect. Shell form (claude plugin …) from the terminal; REPL form (/plugin …) from inside Claude Code.
Verify it loaded. In a fresh Claude Code session, type /roundtable:agent-review-panel with no arguments. The skill should introduce itself and ask what to review. If you get unknown command, see Troubleshooting. Migrating from an older install handle? See MIGRATION.md.
⚡ Recommended — add VoltAgent specialists. Reviews get noticeably sharper when VoltAgent specialist agents are installed: the panel auto-upgrades each reviewer to a real domain specialist (e.g. Security Auditor → voltagent-qa-sec:security-auditor) instead of a generic persona. Not installed? It falls back gracefully — nothing breaks.
claude plugin marketplace add VoltAgent/awesome-claude-code-subagents
claude plugin install voltagent-qa-sec@voltagent-subagents # backs the core code-review personas
Add voltagent-lang, voltagent-data-ai, voltagent-infra, … as you need them (10 families, 130+ agents; the /plugin … REPL form works too — takes effect next session). Why it's worth it → Sharper reviews with VoltAgent. (VoltAgent installs through Claude Code's plugin system.)
Use:
> Review this implementation plan from multiple perspectives: docs/my_plan.md
> /roundtable:agent-review-panel
Natural-language invocation also works ("red team this", "stress-test this design", "get a panel review of …").
What you get — three files written to your current working directory:
review_panel_report.md — executive summary, consensus, judge-resolved disagreements, action itemsreview_panel_process.md — verbatim "director's cut" of every reviewer's outputreview_panel_report.html — interactive dashboard with expandable issue cards, charts, and a panel gallerySee Sample output below for what a real report looks like.
Use a panel for: high-stakes plans you'd want a second/third/fourth opinion on; security-sensitive code; architecture decisions that are expensive to reverse; docs that have to be right; "I'm too close to this — stress-test it."
Don't use a panel for (use a single review or /review instead): a quick look before pushing; type-error fixes; routine code review; addressing existing PR comments; "what does this code do?"; deployments; writing tests or docs from scratch.
The key signal is multiple independent perspectives — if one opinion would do, you're paying 4–6× more for nothing.
Ask one reviewer "review this" and you get one perspective. It won't argue with itself, catch its own blind spots, or volunteer "I'm not sure about this."
The panel forces the same model to take multiple passes from assigned, divergent stances — Correctness Hawk, Security Auditor, Devil's Advocate, etc. — before they see each other's output. Then they debate, then a separate judge step resolves disputes against verified evidence. You get a deliberation, not a list:
Feasibility Analyst: "The
data_available_throughhardcoding is minor — it's documented."Risk Assessor: "Disagree. If stale, the lookforward extends past actual data — model trains on incomplete outcomes — silent false-negative bias."
Feasibility Analyst (Round 2): "Valid point. I upgrade this to IMPORTANT."
Honest caveat: all reviewers are Claude instances running the same base model. This is structured self-critique, not independent verification — unanimous agreement may reflect shared model bias rather than ground truth. The architecture includes anti-groupthink safeguards (blind final scoring, sycophancy detection, correlated-bias warnings) but cannot eliminate the structural limitation. The value is the forced multi-stance discipline plus verification against actual source, not the appearance of disagreement.
The panel was run against this very README on 2026-05-14. The interactive HTML dashboard:
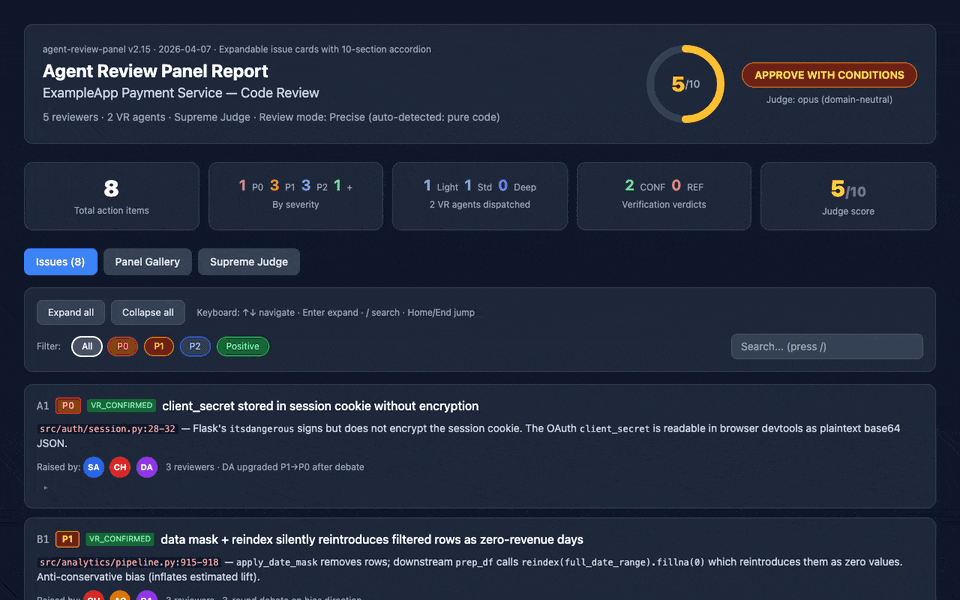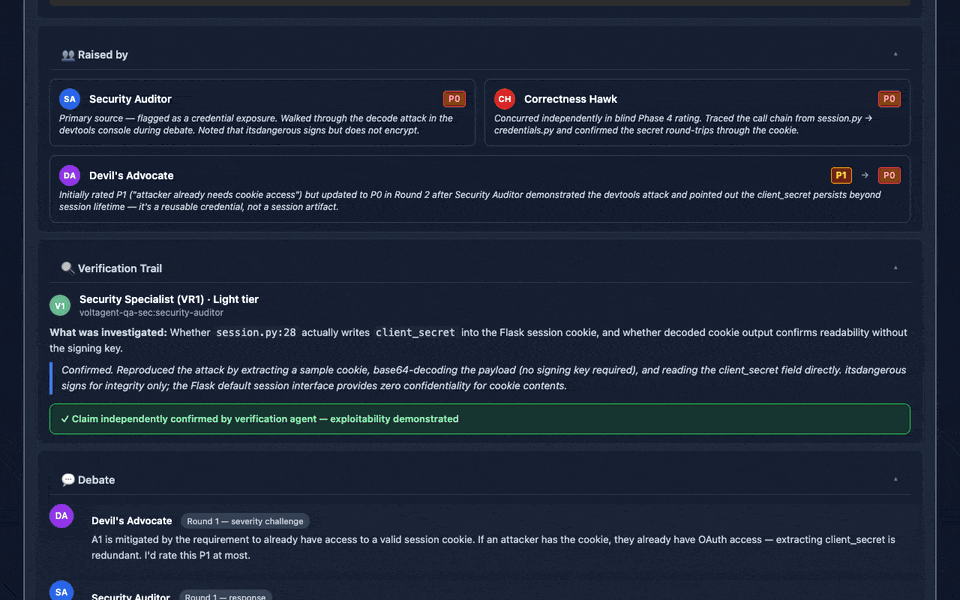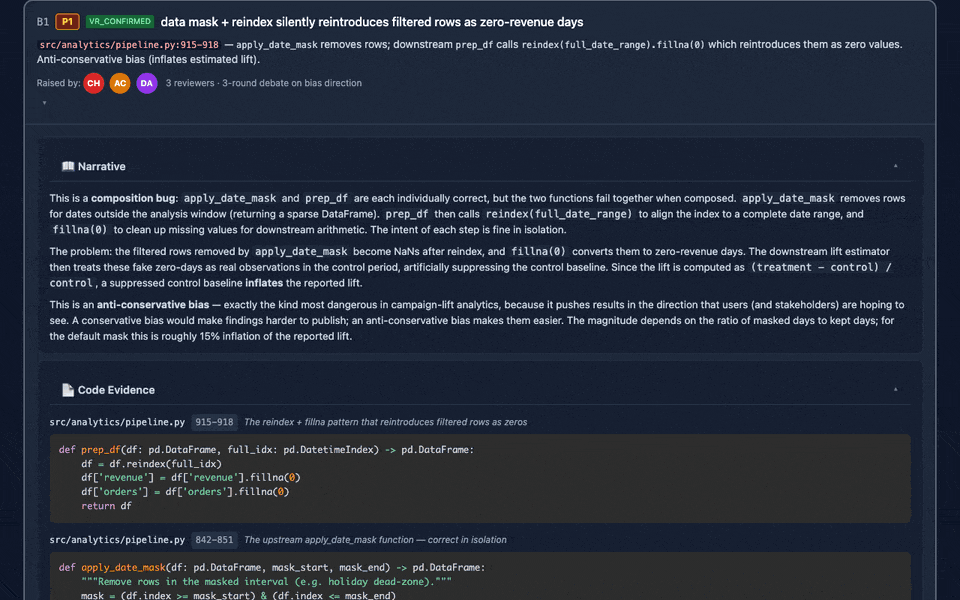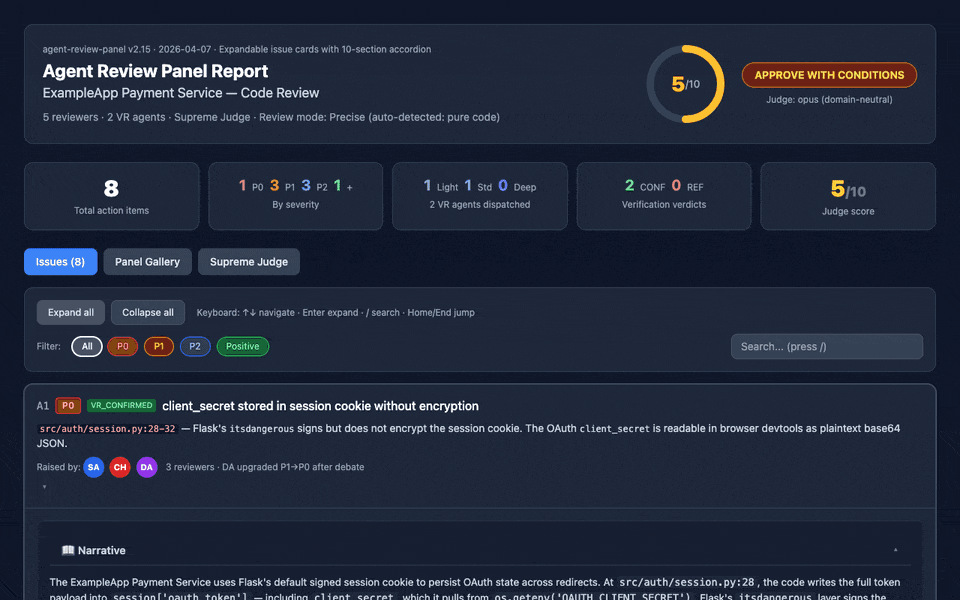
Expandable 10-section issue cards (narrative, code evidence with Prism.js syntax highlighting, debate transcripts, judge rulings, fix recommendations, cross-references), deep-linkable, keyboard-navigable, print-friendly. The GIF above links to the actual generated report for this README.
Excerpt from the matching review_panel_report.md:
# Review Panel Report — README.md
**Verdict:** REVISE — substantial edit needed | **Confidence:** Medium-High
**Score:** 5/10 | **Mode:** Exhaustive (pure documentation)
## Executive Summary
The README is factually careful where it counts — install commands, marketplace
handles, slash commands, the test-count claim, and spot-checked anchors all verify
cleanly against the repo. But three problems pull the score to 5/10: the
version/release story is incoherent and actively misleads every current
user, the document is roughly a third too long, and it never shows what a
review actually produces.
## Consensus Points (judge-confirmed)
- Version/release story is broken — all four reviewers, independently.
package.json declares 3.3.0; the only git tags are up to v3.1.0. The
"Updating" section tells users to verify against "the latest GitHub
release" — which resolves to v3.1.0, so every correctly-installed
v3.3.0 user concludes their install is wrong. [VERIFIED][CONSENSUS]
## Action Items
| # | Severity | Action |
|---|----------|--------------------------------------------------------------|
| 1 | P1 [VERIFIED][CONSENSUS] | Fix the version/release story. |
| 3 | P1 [CONSENSUS] | Cut ~⅓ length; split audiences. |
| 4 | P1 [VERIFIED] | Add a text sample of a real report. |
You're reading the rewrite that lands those findings. The full artifacts live at:
docs/reviews/2026-05-14-readme/review_panel_report.md — the full markdown report (13 action items)docs/reviews/2026-05-14-readme/review_panel_report.html — the interactive HTML dashboarddocs/reviews/2026-05-14-readme/review_panel_process.md — verbatim process log with all four reviewers' raw outputBy default every reviewer is a generic Claude agent wearing a persona prompt ("act as a Security Auditor"). That works — but if you install VoltAgent's specialist agents, the panel upgrades each persona to a matching domain specialist whose expertise is built into its own system prompt: a real Security Auditor, Database Optimizer, or SRE instead of a generalist asked to role-play one.
voltagent-* agents and routes personas to them. No specialist installed for a given role? That reviewer falls back to a generic persona — nothing to configure, nothing breaks.qa-sec (code review, security, performance, chaos), lang (20+ language experts), data-ai, infra, core-dev, and more. Content signals auto-add the right one: SQL → a database optimizer, Terraform → an IaC engineer, React → a frontend specialist. v3.4 added 30 such signal→specialist mappings, roughly doubling coverage.voltagent-qa-sec backs the core code-review personas; add voltagent-lang / voltagent-data-ai / voltagent-infra for language-, ML-, or infra-heavy work. Commands are in Quick Start.VoltAgent specialists install through Claude Code's plugin system — the same Claude Code surfaces the panel itself runs on (CLI / IDE / Desktop "Code" tab / Agent SDK). Codex isn't a supported surface for the panel: it needs Claude Code's
Agenttool to spawn reviewers in parallel — see Surfaces & Requirements.
This plugin needs the Claude Code Agent tool for parallel subagent spawning, local-filesystem access for output files, and a plugin loader.
Works ✅
claude in your terminaloptions.plugins: [{ type: "local", path: "./agent-review-panel" }] (docs)Does not work ❌
/plugin marketplace; Agent Skills there can't spawn parallel subagents or write the output filesPrerequisites in one place:
npm test or developing locally)Don't have Claude Code yet? Install it from claude.ai/code, then come back to Quick Start.
Install commands are in Quick Start. The marketplace install handles caching, version tracking, and trigger-phrase activation in one step.
Command format:
@<marketplace-name>, not@<repo-name>. The marketplace name isagent-review-panel(defined in.claude-plugin/marketplace.json); the plugin install name inside it isroundtable. Henceroundtable@agent-review-panel. If you installed under an older marketplace name, see MIGRATION.md.
Why the marketplace path? The repo ships .claude-plugin/marketplace.json + .claude-plugin/plugin.json manifests that Claude Code reads to register the plugin. The marketplace install reads those manifests and wires everything up in one step. Manual clone works but bypasses the manifests.
For local development, forking, or air-gapped environments. Do NOT clone into ~/.claude/skills/ — that path shadows marketplace installs.
git clone https://github.com/wan-huiyan/agent-review-panel.git ~/projects/agent-review-panel-dev
claude --plugin-dir ~/projects/agent-review-panel-dev
Per-project rule:
mkdir -p .cursor/rules
# Create .cursor/rules/agent-review-panel.mdc with the content of SKILL.md
# Add frontmatter: alwaysApply: true
Manual global install:
git clone https://github.com/wan-huiyan/agent-review-panel.git ~/.cursor/skills/agent-review-panel
The core pattern is straightforward — one subagent per reviewer in Phase 3, collect results, debate in Phase 5, verification and judge after. PRs welcome.
A run executes 16 top-level phases (plus two verification gates — 13.5 and 14.5 — and an optional multi-run merge at Phase 16). The numbered phase table:
| Stage | Phase | Action |
|---|---|---|
| Gather | 1 | Setup — scan sibling dirs, trace references, discover safeguards, detect signals, select personas |
| 2 | Data Flow Trace (code only) — trace critical path(s), document schemas at each function boundary, flag composition/seam bugs | |
| Review | 3 | Independent Review — 4–6 reviewers evaluate in parallel (no cross-talk) |
| 4 | Private Reflection — each reviewer re-reads and rates own confidence | |
| Debate | 5 | Adversarial Debate (1–3 rounds) — reviewers engage + find new issues |
| 6 | Round Summarization — distill resolved/unresolved points between rounds | |
| 7 | Blind Final — each reviewer gives final score independently | |
| Verify | 8 | Completeness Audit — dedicated agent scans for what the panel missed |
| 9 | Verify Commands — run reviewer grep/read commands for P0/P1 findings (advisory) | |
| 10 | Claim Verification — verify all line-number citations against source | |
| 11 | Severity Verification — read actual code for every P0/P1; downgrade if overstated; web-verify external domain claims | |
| 12 | Tier Assignment — confidence-based draft → judge-advised refinement per dispute | |
| 13 | Targeted Verification — persona-matched agents investigate each dispute point | |
| 13.5 | Pre-Judge Verification Gate — orchestrator confirms all phase outputs exist on disk before launching the judge | |
| Adjudicate | 14 | Supreme Judge — Opus arbitrates everything including verification-round evidence |
| 14.5 | Post-Judge Verification Gate — re-verifies judge-introduced P0/P1 against ground truth (catches judge hallucinations) | |
| Output | 15 | Triple output: Primary Report (.md) + Process History (.md) + Expandable-card Dashboard (.html) |
| Merge | 16 | Multi-Run Merge (optional) — deduplicate findings across runs, score stability, resolve judge divergence |
Phase 15 has three sequential sub-steps (15.1 → 15.2 → 15.3) so the HTML agent can read the already-written markdown and process files from disk.
This skill is the full adversarial panel — its defining feature is the Phase 5–7 debate, where reviewers cross-examine each other before a judge rules. Debate is expensive (sequential cross-talk) and only pays off when reviewers would genuinely change each other's verdicts. Pick deliberately:
| You want | Use | Debate? |
|---|---|---|
| Fast eyes on a tiny PR | /code-review, single-persona review | no |
| Independent parallel lenses on small / autonomous multi-PR work | streamlined panel (no-debate) | no, by design |
| Adversarial tradeoff, high-stakes gating, a verdict debate would change (security vs perf, "is this P0 real", merge go/no-go) | this skill (full panel) — invoke as a skill, not a workflow | yes |
Debate lives in the skill's Agent-tool orchestration. Running a review as a Workflow / ultracode task routes it through a parallel fan-out engine (agents never see each other) whose canonical shape is "find → verify → judge" — structurally debate-less. If a run produces no debate, the report now stamps a loud [NO-DEBATE] banner and caps confidence at Medium, so a debate-less review is never silent. To get the panel's depth under a Workflow, author an explicit Debate phase (see the debate-in-Workflow recipe in SKILL.md).
Review process
Verification layer
[WEB-VERIFIED], [WEB-CONTRADICTED], or [WEB-INCONCLUSIVE][EXISTING_DEFECT] or [PLAN_RISK] — P0 requires existing defect evidencedescribe-class output. Tagged [LIVE-VERIFIED] or [STATIC-INFERENCE] — the latter is capped at P1model: "opus" explicitly to eliminate cross-run reasoning varianceAnti-groupthink safeguards
⚠️ HUMAN REVIEW RECOMMENDEDOutputs (three files per review)
review_panel_report.md): executive summary, consensus, disagreements (with judge rulings), prioritized action items with epistemic labels — see Reading the Report.review_panel_process.md): verbatim "director's cut" log of every agent's output, with persona profiles embedded.review_panel_report.html) with expandable 10-section issue cards — each card opens a nested accordion: 📖 Narrative, 📄 Code Evidence (Prism.js-highlighted), 👥 Raised by, 🔍 Verification Trail, 💬 Debate, ⚖️ Judge Ruling, 🛠️ Fix Recommendation, 🔗 Cross-references, 🏷️ Epistemic Tags, 📊 Prior Runs. Deep-linkable (report.html#issue-A1), keyboard-navigable, print-friendly. Tailwind + Chart.js + Prism.js via CDN.Advanced
--runs N or "run 3 times and merge" to execute the panel N times with rotated persona compositions. Phase 16 merges findings by location + bug class, scores stability as [K/N RUNS], resolves judge divergence. Mitigates the ~30% single-run blind spot observed in early consistency analyses> Review this implementation plan from multiple perspectives: docs/my_plan.md
> /roundtable:agent-review-panel
> Get a panel review of the authentication module — I want to stress-test the design
> Red team this deployment strategy
> Have agents debate whether this refactor is worth the complexity
> /roundtable:agent-review-panel deep # adds web research for domain best practices
> Do a deep review of this ML pipeline
After a panel review of a plan document, integrate findings back into the plan with traceability:
> /roundtable:plan-review-integrator review_panel_report.md docs/my_plan.md
The integrator classifies each finding (apply / defer / reject), edits the plan in place, and produces a per-finding traceability summary.
All modes are LLM-interpreted phrases — the skill's description matches them at invocation. There are no shell flags.
| Mode | Invoke with | Effect |
|---|---|---|
| Default panel | /roundtable:agent-review-panel (or any "review panel" phrasing) | 4-reviewer panel; auto-personas; auto Precise/Exhaustive |
| Deep research | /roundtable:agent-review-panel deep or "do a deep review of …" | Adds opt-in web research for domain best practices |
| Multi-run union | --runs 3 or "run 3 times and merge" | Runs the panel N times with rotated personas; deduplicates findings; scores stability [K/N RUNS] |
| Trace tier | "use Thorough trace" / "use Exhaustive trace" | Data Flow Trace tier (Standard default / Thorough top-3 paths / Exhaustive all paths) |
| Custom personas | "include a Security Auditor and a Cost Modeler" | Overrides auto-persona detection; panel size still 4–6 |
| Content type | Duration | Tokens | Approx $ at current Opus pricing |
|---|---|---|---|
| Docs / README review | ~6 min | ~150k | ~$3 |
| Plan document (small) | ~6–8 min | ~180k | ~$5 |
| Code (4-reviewer, auto Precise) | ~8–10 min | ~250k | ~$10 |
| Code + Exhaustive Data Flow Trace | ~12–15 min | ~350k | ~$20 |
--runs 3 multi-run union | 3× base | 3× base | 3× base |
Cost is driven by: reviewer count (4–6 auto-scales by signal density), content size, debate rounds, deep mode (adds web research), and --runs N (linear multiplier). Pricing assumes Anthropic's published Opus rate at time of run; check Anthropic pricing for current numbers.
review_panel_* files there. Filenames are not configurable. Run one panel at a time per directory.The panel produces three files per run; here's how to read them.
Vocabulary. This README uses these words consistently:
| Term | Means |
|---|---|
| plugin | The marketplace package you install (roundtable) |
| skill | A shipped behavior loaded by Claude Code; this plugin bundles two (agent-review-panel, plan-review-integrator) |
| reviewer | One persona in the panel (e.g. Clarity Editor, Devil's Advocate). 4–6 reviewers per run |
| agent / subagent | The Claude Code launch mechanism used to spawn each reviewer in parallel — not a synonym for "reviewer" or "skill" |
| panel | The full set of reviewers participating in a single run |
| judge | The Phase 14 arbiter that ingests all reviewer + verification output and renders the final verdict |
Severity rubric. Every finding is tagged with one severity:
Epistemic labels. Each finding is also tagged with how confident the panel is in the underlying evidence:
| Label | Meaning |
|---|---|
[VERIFIED] | Confirmed against source — line citation matches actual code/text |
[CONSENSUS] | Three or more reviewers raised it independently |
[SINGLE-SOURCE] | One reviewer raised it, no one refuted |
[DISPUTED] | Reviewers split on whether it's a real issue |
[UNVERIFIED] | Stated without a checkable citation; treat with care |
[WEB-VERIFIED] / [WEB-CONTRADICTED] / [WEB-INCONCLUSIVE] | External fact confirmed / contradicted / unconfirmed by an authoritative web source |
[CMD_CONFIRMED] / [CMD_CONTRADICTED] | Reviewer's verification_command (read-only grep/cat/head) was run and the result confirmed/contradicted the claim |
[LIVE-VERIFIED] | Live-infrastructure/runtime-state claim backed by describe-class command output (gcloud describe, bq show, kubectl get, etc.) |
[STATIC-INFERENCE] | Live-state claim inferred from source/config/deploy scripts only — capped at P1 |
[STATIC-INFERENCE-CONSENSUS] | Multiple reviewers agreed off the same artifact lines — counts as one source, not independent verification |
[JUDGE-HALLUCINATED] | The post-judge gate caught a finding the judge introduced that the panel never raised and ground-truth contradicted — heavily discount |
[COMPRESSED] | Suffix on every action item when the pre-judge gate detected unrecoverable phase loss; the run is lower confidence — re-run for a full report |
Defect type. Code/plan reviews additionally label findings as [EXISTING_DEFECT] (bug exists right now) or [PLAN_RISK] (risk only materializes if the plan is implemented as written). P0 severity requires [EXISTING_DEFECT] evidence.
How to read in priority order. Start with the Executive Summary, then the Action Items table (sorted P0 → P3). Use the HTML dashboard's filter bar to narrow by severity or epistemic label. Read the process history (review_panel_process.md) only when you need to see why a finding got a particular ruling. For findings that look wrong, scrutinise the epistemic label first — see TROUBLESHOOTING.md → A finding looks wrong.
The roundtable plugin ships two skills in one install:
| Skill | Source | What it does | When to use |
|---|---|---|---|
agent-review-panel | skills/agent-review-panel/ | Multi-agent adversarial review panel | When you need a structured review of code, plans, docs, or configs |
plan-review-integrator | skills/plan-review-integrator/ | Takes review panel output and integrates findings into a plan with traceability | After a panel review of a plan document |
Both are activated by natural language or by /roundtable:agent-review-panel and /roundtable:plan-review-integrator.
roundtable and not agent-review-panel?roundtable is a collective noun for the bundle. It also reads more naturally in slash-command form. plan-review-integrator was previously published as a standalone repo at wan-huiyan/plan-review-integrator — that repo is archived in favor of this bundle.
The test suite (443 tests) uses Node's built-in test runner — zero dependencies, requires Node ≥18:
npm test # run all 443 tests
npm run test:triggers # trigger classification
npm run test:manifest # manifest consistency + phase/opus enforcement
npm run test:eval-suite # eval suite integrity
npm run test:report # report structure validation
npm run test:behavioral # behavioral assertion framework
npm run test:golden # golden-file structural snapshots
Tests enforce key invariants: all 16 top-level phases (plus 13.5 / 14.5) present in SKILL.md; every subagent_type: launch co-occurs with model: "opus"; Phase 15.3 spec documents all 10 expandable-card sections; the canonical SKILL.md lives at skills/agent-review-panel/SKILL.md.
New releases land on main; Claude Code does not auto-pull. From your terminal:
claude plugin marketplace update agent-review-panel
claude plugin update roundtable@agent-review-panel
(REPL form: /plugin marketplace update agent-review-panel then /plugin update roundtable@agent-review-panel.)
Verify the update. The installed version is the directory name under ~/.claude/plugins/cache/agent-review-panel/roundtable/. Compare it against the canonical version in this repo's package.json or the top entry of CHANGELOG.md. Note that GitHub releases may lag main — package.json is the authoritative version source.
If the update appears to work but old behavior persists, a stale local clone may be shadowing the marketplace install — see TROUBLESHOOTING.md → Old version keeps loading.
If you installed before v3.0 or under an older marketplace handle (@wan-huiyan-agent-review-panel, @plugin, or the bare @agent-review-panel), see MIGRATION.md for the uninstall + clean-install recipe and a stale-state cleanup prompt you can paste into Claude Code.
Common problems and their fixes live in TROUBLESHOOTING.md. The most-hit entries:
Bug reports, questions, and feedback: open a GitHub issue. When filing a bug for a failed or weird review, include the content type (code/plan/docs), approximate size, and (if you can) the review_panel_report.md and review_panel_process.md files — they make repro practical.
Contributions welcome. Especially useful:
Dev setup:
git clone https://github.com/wan-huiyan/agent-review-panel.git ~/projects/agent-review-panel-dev
cd ~/projects/agent-review-panel-dev
npm test # requires Node ≥18
bash scripts/release-check.sh # pre-release doc-drift detector
The authoritative skill is skills/agent-review-panel/SKILL.md. Manifest invariants (phase count, force-opus, HTML-card schema, marketplace-name callout marker) are enforced by tests/manifest-consistency.test.mjs and scripts/release-check.sh — both must stay green. See HOW_WE_BUILT_THIS.md for the design journey. Open an issue to discuss before submitting large PRs.
claude plugin uninstall roundtable@agent-review-panel
claude plugin marketplace remove agent-review-panel
(REPL form: /plugin uninstall roundtable@agent-review-panel and /plugin marketplace remove agent-review-panel.)
For a fully clean uninstall that removes cached state and any shadow clones, see MIGRATION.md → Stale-state cleanup. Manual-clone installs: rm -rf ~/.claude/skills/agent-review-panel.
Agent Review Panel is grounded in 9 research papers and projects on multi-agent debate and evaluation quality.
Mechanisms directly mapped to architecture:
tf/ft/tt/ff conformity tracking makes Phase 5 position flips detectable as signal.Verdict Confidence: High|Medium|Low field; low-confidence verdicts get ⚠️ HUMAN REVIEW RECOMMENDED.reasoning_strategy per persona injected into Phase 3 prompts.Papers and projects that informed the design (without 1:1 architecture mapping): AutoGen (multi-agent orchestration patterns — note: AutoGen is a Microsoft research project, not a peer-reviewed paper), Du et al. (ICML 2024), DebateLLM, "Talk Isn't Always Cheap" (ICML 2025) for failure-mode analysis, CONSENSAGENT (ACL 2025) for sycophancy detection.
The cited papers validate multi-agent debate on reasoning benchmarks; this project has not independently benchmarked review quality. The full table with venues, links, and per-paper contributions lives in docs/research-foundations.md. Also inspired by MiroFish for heterogeneous-persona patterns. See ROADMAP.md for the research roadmap.
See CHANGELOG.md for detailed version history and ROADMAP.md for deferred items.
| Version | Highlights |
|---|---|
| v3.4 | VoltAgent catalog expansion — 30 new signal→specialist mappings (130+ agents / 10 families) + drift-detection automation (vendored catalog snapshot, CI gate) |
| v3.3 | Live-State Claim Discipline — cross-cutting rule set for findings asserting facts about live infrastructure or runtime state |
| v3.2 | Post-judge verification gate + Chart.js wrapper-div mandate — Phase 14.5 re-verifies judge-introduced P0/P1 against ground truth |
| v3.1 | Silent-phase-compression fix — file-based subagent state under state/, Phase 13.5 Pre-Judge Verification Gate |
| v3.0 | Single-plugin layout (BREAKING) — one plugin (roundtable) bundling both skills |
| v2.16 | Plugin layout + marketplace bundle |
| v2.15 | Expandable 10-section issue cards in HTML dashboard; Prism.js syntax highlighting; deep-linking |
| v2.14 | Data Flow Trace (3 tiers); Multi-Run Union Protocol + Phase 16 Merge; force-opus on all launches |
| v2.13 | Persona profiles in process history + Panel Gallery in HTML dashboard |
| v2.12 | Triple output: primary + process history + interactive HTML dashboard |
| v2.11 | Verification round: tiered persona-matched agents per dispute |
| v2.10 | Codebase state check — prevents false "missing code" findings in worktrees |
| v2.9 | VoltAgent specialist agent integration |
| v2.8 | Auto Precise/Exhaustive mode, verification commands, tiered knowledge mining |
| v2.7 | Severity verification, defect classification, temporal scope checks |
| v2.5 | Trust layer: claim verification, epistemic labels, scope disclosure |
| v2.0 | Completeness auditor, new discovery requirement |
| v1.0 | Initial release: multi-agent review with debate and judge |
MIT — Huiyan Wan. Reports you generate are yours; the HTML dashboard loads Tailwind, Chart.js, and Prism.js from CDN — all MIT-licensed.
External contributors — thank you!
1000+ skills curated from Anthropic, Vercel, Stripe, and other engineering teams
Design enforcement with memory — keeps your UI consistent across a project
Detects 37 AI writing patterns and rewrites text with human rhythm across 5 voice profiles
WCAG accessibility audit — automated scanning, manual review, remediation