

Are you the author? Sign in to claim
Official Implementation for the Paper [AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent](https://ar
Distilling Multi-Agent Intelligence into a Single LLM Agent.
![]()
Yinyi Luo1 · Yiqiao Jin2 · Weichen Yu1 · Mengqi Zhang3 · Srijan Kumar2 · Xiaoxiao Li5 · Weijie Xu4 · Xin Chen4; Jindong Wang3
1Carnegie Mellon University 2Georgia Institute of Technology 3William & Mary 4Amazon 5University of British Columbia
| Metric | Value |
|---|---|
| Avg. accuracy lift over single-agent baseline | +4.8% |
| Total experiments across Qwen3 / Gemma 3 / Llama 3 | 120 |
| Hierarchical distillation strategies | 3 (R-SFT · DA · PAD) |
| Distillation questions / reasoning trajectories | ~342K / ~2M |
While large language model (LLM) multi-agent systems achieve superior reasoning performance through iterative debate, practical deployment is limited by their high computational cost and error propagation. This paper proposes AgentArk, a novel framework to distill multi-agent dynamics into the weights of a single model, effectively transforming explicit test-time interactions into implicit model capabilities. This equips a single agent with the intelligence of multi-agent systems while remaining computationally efficient. Specifically, we investigate three hierarchical distillation strategies across various models, tasks, scaling, and scenarios: reasoning-enhanced fine-tuning; trajectory-based augmentation; and process-aware distillation. By shifting the burden of computation from inference to training, the distilled models preserve the efficiency of one agent while exhibiting strong reasoning and self-correction performance of multiple agents. They further demonstrate enhanced robustness and generalization across diverse reasoning tasks. We hope this work can shed light on future research on efficient and robust multi-agent development.
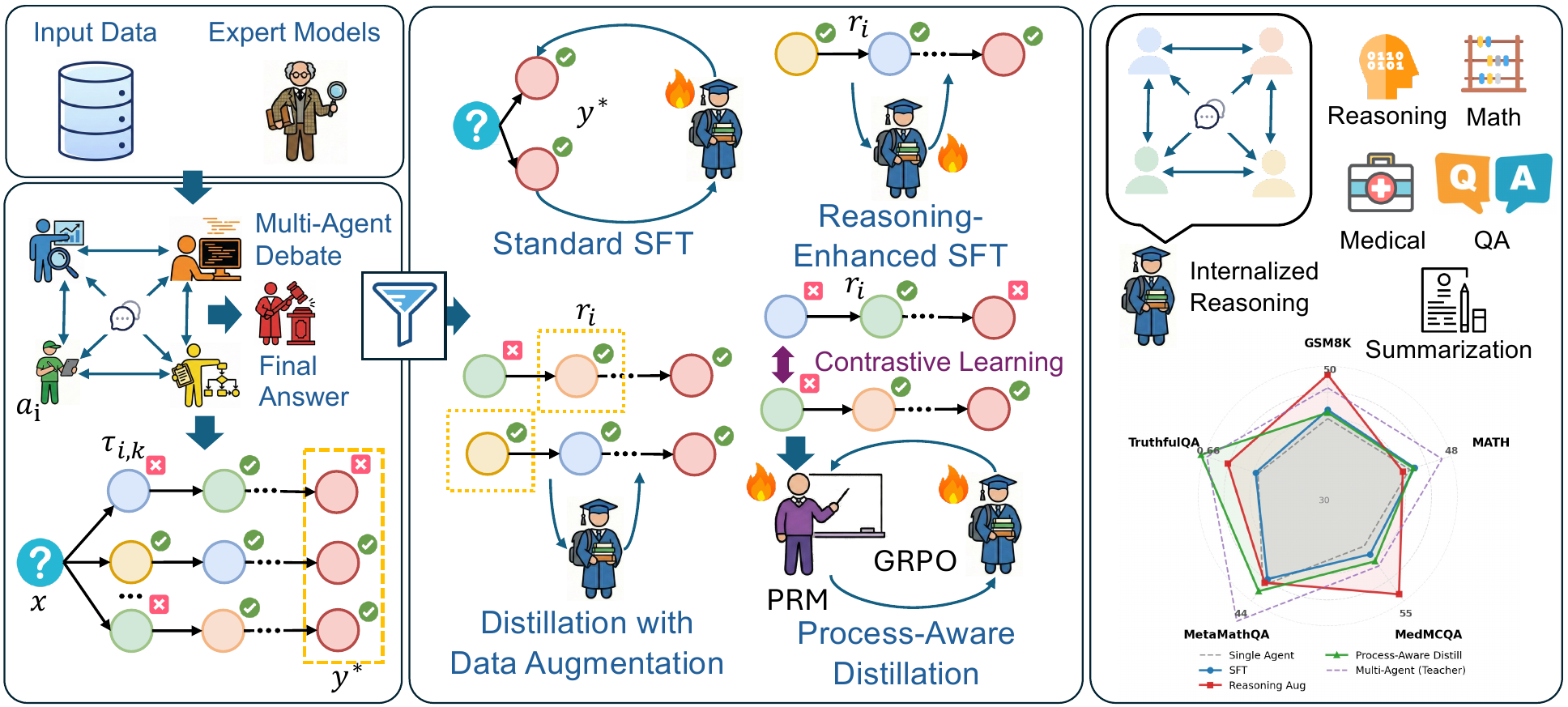
AgentArk distills multi-agent debate into a single model through three hierarchical strategies — Reasoning-Enhanced SFT (R-SFT), Reasoning Trajectory-based Data Augmentation (DA), and Process-Aware Distillation (PAD) — moving the cost of collective reasoning from inference time into training time.
| Python | 3.10+ |
| CUDA | 12.5 |
| GPU memory | 40 GB+ recommended for inference |
# Clone the repository
git clone <repository-url>
cd AgentArk
# Create virtual environment
conda create -n agentark python=3.12
conda activate agentark
# Install dependencies
pip install -r requirements.txt
| Category | Packages |
|---|---|
| LLM Inference | transformers, vllm, flash-attn |
| RL Training | deepspeed, trl, torch |
| Evaluation | rouge_score, bert_score, sympy |
| Utilities | datasets, accelerate, peft, wandb |
# Run inference with LLM Debate on QMSum dataset
python inference.py \
--method_name llm_debate \
--test_dataset_name QMSum \
--model_name Qwen/Qwen3-8B \
--use_vllm \
--tensor_parallel_size 2
# Evaluate results
python -m eval.short_answer_eval \
--input_file results/QMSum/Qwen/Qwen3-8B/llm_debate_infer.jsonl \
--dataset_name QMSum
Each method lives under methods/ with its own YAML config in methods/<name>/configs/.
| Method | Directory | Description |
|---|---|---|
| AgentVerse | methods/agentverse | Collaborative role-play with critic feedback rounds |
| AutoGen | methods/autogen | Conversable multi-agent framework |
| CAMEL | methods/camel | Role-playing communicative agents |
| ChatDev | methods/chatdev | Software-development-oriented multi-agent pipeline |
| CoT | methods/cot | Single-agent chain-of-thought baseline |
| DyLAN | methods/dylan | Dynamic agent network with listwise ranking |
| EvoMAC | methods/evomac | Evolutionary multi-agent collaboration |
| LLM Debate | methods/llm_debate | Iterative debate among peer agents |
| MacNet | methods/macnet | Macro-network of communicating agents |
| MAD | methods/mad | Multi-Agent Debate |
| MapCoder | methods/mapcoder | Code-generation pipeline with planner/coder roles |
| MAS Base | methods/mas_base | Shared base utilities for multi-agent systems |
| MAV | methods/mav | Multi-Agent Verifier |
| Self-Consistency | methods/self_consistency | Parallel sampling with majority vote |
| Dataset | Task type |
|---|---|
| MATH | Mathematical reasoning |
| GSM8K | Grade-school math |
| MetaMathQA | Augmented math |
| MedMCQA | Medical multiple choice |
| QASPER | Long-context scientific QA |
| HotpotQA | Multi-hop QA |
| QMSum | Query-based meeting summarization |
| TruthfulQA | Robustness / truthfulness |
| Family | Models | Typical role |
|---|---|---|
| Qwen 3 | Qwen3-32B, Qwen3-8B, Qwen3-1.7B, Qwen3-0.6B | Teacher (32B) / Students |
| Gemma 3 | Gemma3-27B-it, Gemma3-7B | Teacher / Student |
| Llama 3 | Llama3-8B-Instruct | Student |
| Qwen2.5-VL (multimodal) | Qwen2.5-VL-32B-Instruct, Qwen2.5-VL-3B | Teacher / Student |
Run multi-agent inference on a dataset:
python inference.py \
--method_name <method> \
--test_dataset_name <dataset> \
--model_name <model_path_or_name> \
--use_vllm \
--tensor_parallel_size <num_gpus>
Key Arguments:
| Argument | Description | Default |
|---|---|---|
--method_name | Multi-agent method to use | Required |
--test_dataset_name | Dataset for evaluation | Required |
--model_name | HuggingFace model or local path | Required |
--model_temperature | Sampling temperature | 0.5 |
--model_max_tokens | Maximum tokens per generation | 4096 |
--use_vllm | Enable vLLM for efficient batching | False |
--tensor_parallel_size | Number of GPUs for tensor parallelism | 1 |
--use_modal_batch | Use Modal for cloud deployment | False |
python inference.py \
--method_name dylan \
--test_dataset_name MATH \
--model_name Qwen/Qwen3-32B \
--use_vllm \
--tensor_parallel_size 4 \
--model_temperature 0.7
# First deploy the Modal model
modal deploy modal/launch_modal.py
# Then run inference
python inference.py \
--method_name llm_debate \
--test_dataset_name QMSum \
--use_modal_batch \
--model_name Qwen/Qwen3-8B
Label generated solutions for correctness (required for PRM training):
python label.py \
--input results/QMSum/Qwen/Qwen3-32B/llm_debate_infer.jsonl \
--dataset_name QMSum \
--model Qwen/Qwen2.5-72B-Instruct \
--tensor_parallel_size 4
This produces labeled data with the format:
{
"query": "...",
"gt": "ground truth answer",
"solutions": [
{"id": 1, "text": "solution text", "is_correct": true},
{"id": 2, "text": "solution text", "is_correct": false}
],
"labels": [true, false]
}
Train a PRM to score intermediate reasoning steps:
PYTHONPATH=$PYTHONPATH:$(pwd) python prm/finetune2.py \
--model_name_or_path Qwen/Qwen3-8B \
--train_data_path results/QMSum/labeled.jsonl \
--output_dir outputs/prm_qmsum \
--num_train_epochs 3 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 16 \
--gradient_accumulation_steps 1 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--save_strategy steps \
--save_steps 500 \
--save_total_limit 3 \
--bf16 True \
--gradient_checkpointing True \
--fix_llm True \
--enable_nan_monitoring True
Finetune the policy model using Group Relative Policy Optimization:
python -m openrlhf.cli.train_grpo \
--pretrain Qwen/Qwen3-0.6B \
--reward_pretrain outputs/prm_qmsum \
--save_path outputs/grpo_qmsum \
--temperature 0.5 \
--n_samples_per_prompt 8 \
--advantage_estimator rloo \
--reward_baseline token \
--reward_mode PRMVR \
--verifiable_reward_coef 1.0 \
--micro_rollout_batch_size 4 \
--rollout_batch_size 64 \
--micro_train_batch_size 2 \
--train_batch_size 128 \
--actor_learning_rate 5e-7 \
--init_kl_coef 0.001 \
--max_epochs 1 \
--num_episodes 1 \
--prompt_max_len 40960 \
--generate_max_len 2048 \
--zero_stage 2 \
--bf16 \
--flash_attn \
--gradient_checkpointing \
--save_steps 20 \
--logging_steps 1
GRPO Key Arguments:
| Argument | Description |
|---|---|
--pretrain | Base model to finetune |
--reward_pretrain | Trained PRM checkpoint |
--n_samples_per_prompt | Group size for RLOO baseline (keep >= 4) |
--advantage_estimator | rloo or gae |
--reward_mode | Reward computation mode (PRMVR, ORM, etc.) |
--micro_rollout_batch_size | Prompts per GPU during rollout |
--micro_train_batch_size | Samples per GPU during training |
Memory Optimization Tips:
micro_rollout_batch_size and micro_train_batch_size to save GPU memoryn_samples_per_prompt >= 4 for stable GRPO performancerollout_batch_size x n_samples_per_promptpython -m eval.short_answer_eval \
--model_name_or_path Qwen/Qwen3-8B \
--dataset_name QMSum \
--split validation \
--output_dir outputs \
--temperature 0.7 \
--use_vllm \
--apply_chat_template
for MODEL in Qwen/Qwen3-0.6B Qwen/Qwen3-1.7B Qwen/Qwen3-8B; do
for DATASET in QMSum QASPER HotpotQA; do
python -m eval.short_answer_eval \
--model_name_or_path "$MODEL" \
--dataset_name "$DATASET" \
--split validation \
--output_dir outputs \
--use_vllm
done
done
python -m eval.math_eval \
--input_file results/MATH/Qwen/Qwen3-8B/mav_infer.jsonl \
--dataset_name MATH
Each method has YAML configuration files in methods/<method_name>/configs/.
# methods/dylan/configs/config_main.yaml
random_seed: 0
num_agents: 4 # Number of agents in the network
num_rounds: 3 # Communication rounds
activation: "listwise" # Agent ranking strategy
roles:
- "Assistant"
- "Assistant"
- "Assistant"
- "Assistant"
# methods/agentverse/configs/config_main.yaml
cnt_agents: 2 # Number of collaborative agents
max_turn: 3 # Maximum conversation turns
max_criticizing_rounds: 3 # Critic feedback iterations
# methods/self_consistency/configs/config_main.yaml
parallel_num: 5 # Number of parallel solution paths
# methods/llm_debate/configs/config_main.yaml
num_agents: 3 # Number of debating agents
num_rounds: 2 # Debate rounds
If you find AgentArk useful for your research, please cite:
@article{luo2026agentark,
title={AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent},
author={Luo, Yinyi and Jin, Yiqiao and Yu, Weichen and Zhang, Mengqi and Kumar, Srijan and Li, Xiaoxiao and Xu, Weijie and Chen, Xin and Wang, Jindong},
journal={arXiv preprint arXiv:2602.03955},
year={2026}
}
AgentArk is built on top of excellent open-source work, including OpenRLHF, vLLM, TRL, and HuggingFace Transformers.
This project is released under the Apache License 2.0.
Manage multiple Claude Code agents from TUI or Web with tmux and git worktrees
Kanban-based orchestration for 10+ coding agents with isolated git worktrees per agent
⚠️ Experimentelle Skill-Sammlung für deutsches Recht (Arbeits-, Gesellschafts-, Insolvenz-, Datenschutz-, Prozessrecht u
Project management using GitHub Issues + Git worktrees for parallel agent execution