

Are you the author? Sign in to claim
An open-source AI coding observability layer. Silently tracks vibe coding sessions via MCP and codifies AI deviations in
每一次 Vibe Coding 都在产生大量信号 —— 偏差、模式、质量数据。
但你关掉终端,这些全部消失。下次对话,继续盲写。
AIDA 在每个开发节点采集结构化数据,用看板可视化,再把偏差规律沉淀成规则 —— 让你的 AI 每次运行都写出更符合预期的代码。
一行配置接入,零工作流改变。
{ "mcpServers": { "aida": { "command": "npx", "args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"] } } }




一行接入 · 场景操作指南 · 数据驱动闭环 · 命令速览 · 重复执行与覆盖策略 · 规则去重与冲突判断 · 命令文档 · 文档导航 · English
Vibe Coding 很强。但它是一个黑箱。
你让 Claude 写一个功能,它写了,你 ship 了。但你对过程零可见性:
没有数据,你就无法改进。你只是在一遍又一遍地 vibe —— 带着同样的盲区。
AIDA 让不可见变可见。 它在每次 vibe coding 过程中采集结构化数据,用实时看板渲染,再把偏差模式沉淀成项目规则。你的 AI 不再只是写代码 —— 它学习你的项目。
这是 AIDA 的核心 —— 数据进来,规则出去,代码越来越好。
Vibe Coding 过程
↓
AIDA 静默采集结构化数据
(任务、偏差、Bug、自检、文件变更、时间线)
↓
看板可视化呈现规律
"9 个偏差 → 56% 幻觉, 44% 规则缺失"
↓
发现偏差规律 → AI 建议沉淀规则 → 用户确认 → 写入规则库
.aida/rules.json ← 你的 AI 知识库在成长
↓
AI 下次读取规则 → 同样的错误被消除
↓
循环往复 —— 每一轮,AI 输出都更接近你的预期
来自真实生产项目的数据:
| 运行 | 偏差情况 | 发生了什么 | 沉淀的规则 |
|---|---|---|---|
| 第 1 轮 | 47 个任务产生 23 个偏差 | AI 组件用错、布局写反、API 模式不对 | 沉淀 6 条项目专属规则 |
| 第 2 轮 | 零重复偏差 | AI 读了规则,相同模式的错误归零 | — |
第一步:看清 AI 为什么出错 —— 根因分布一目了然:是 AI 幻觉、规则缺失、还是上下文不足?
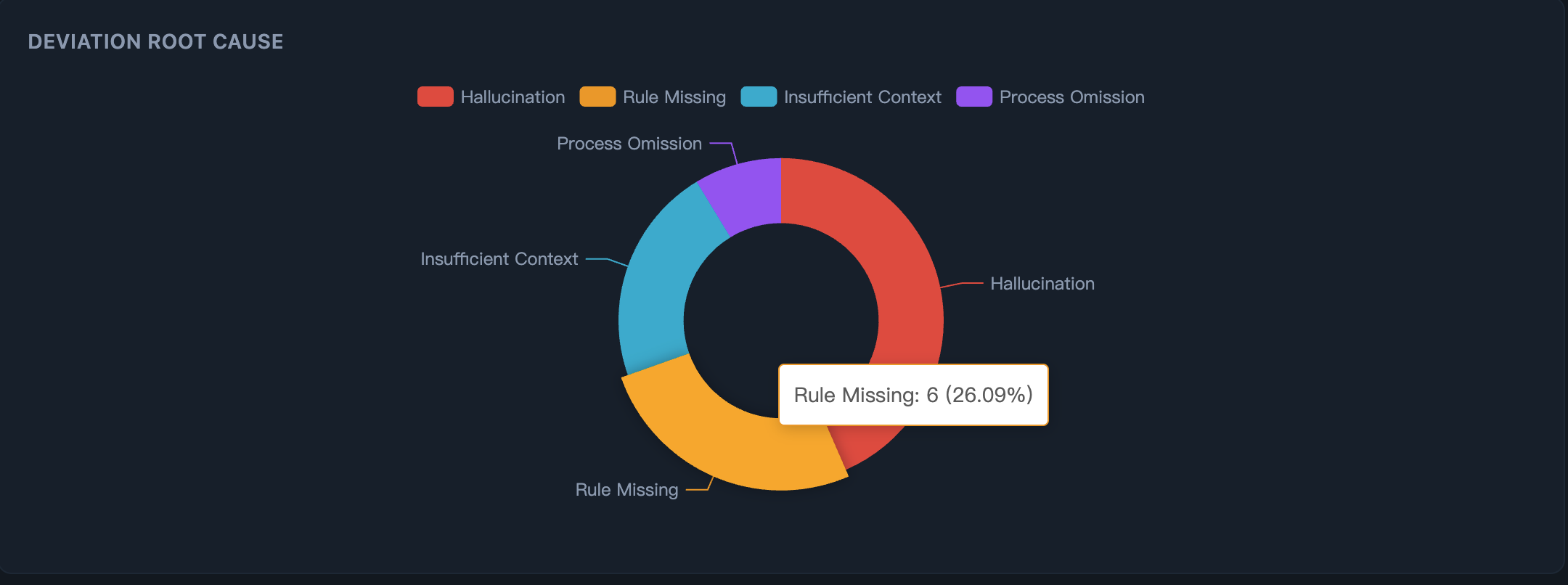
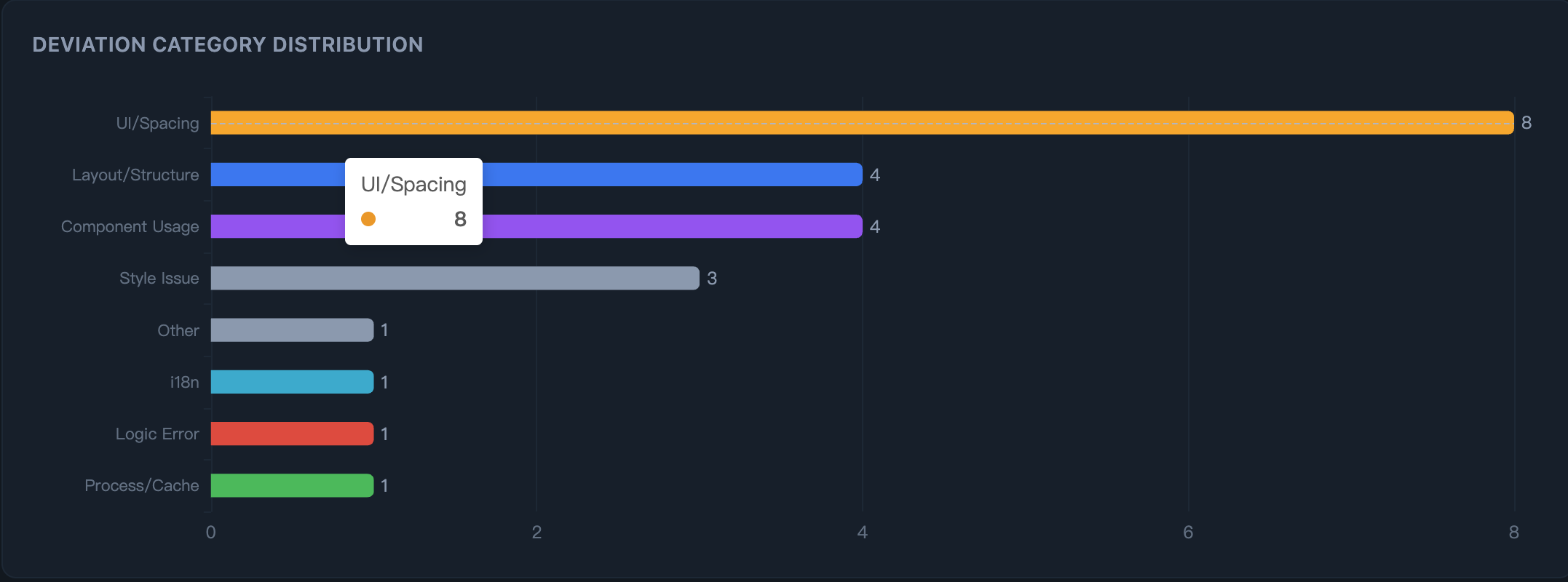
第二步:看清 AI 在哪出错 —— 类别分布精准定位:UI 间距、布局结构、组件使用、API 模式。
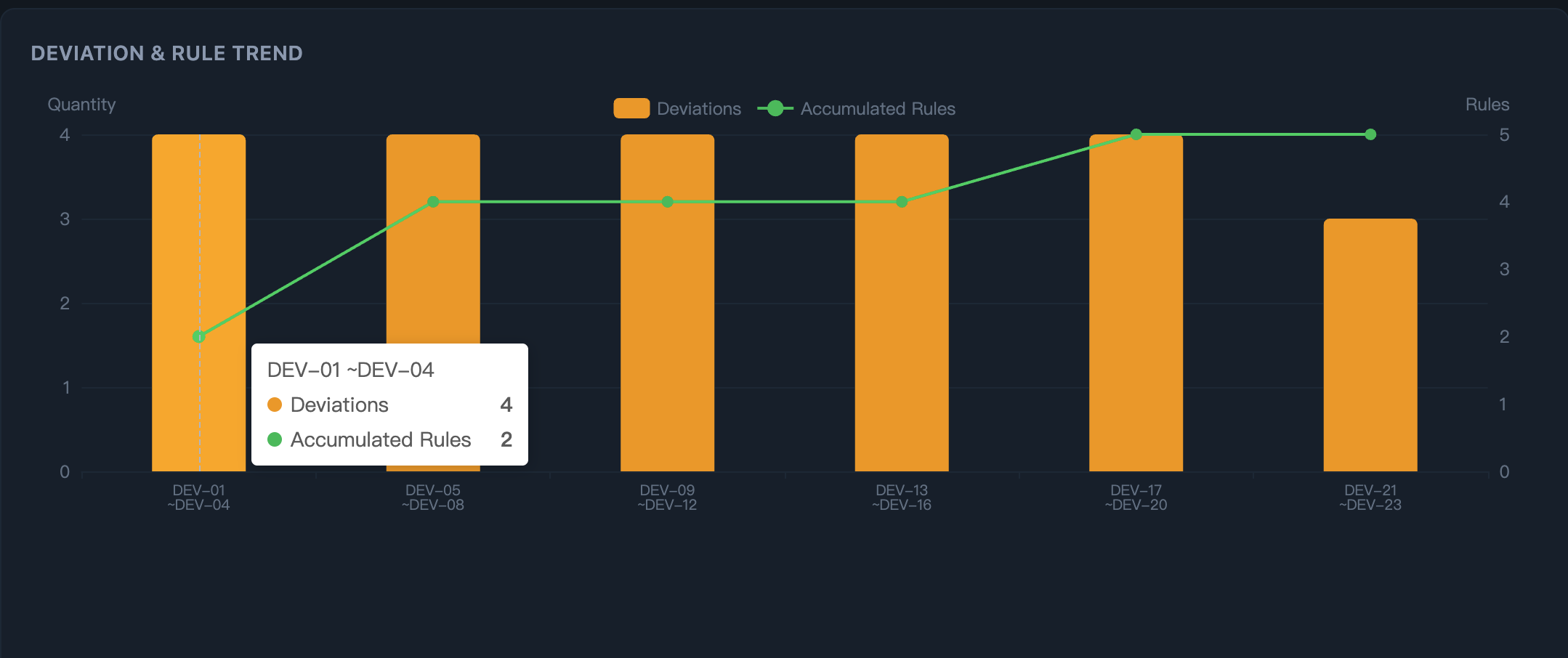
第三步:看规则的复利效应 —— 随着规则积累,重复偏差会逐步下降。
.aida/rules.json 就是你的项目专属 AI 知识库。用 AI 写得越多,它对你的项目就越懂。
你的整个 Vibe Coding 过程 —— 结构化、可视化、可操作。
在线 Demo → 真实脱敏数据,无需安装。
AIDA 全方位采集 AI 辅助开发的每个维度,转化为交互式图表:
| 你能看到什么 | 为什么重要 |
|---|---|
| 偏差根因分布 | 知道 AI 为什么出错 —— 规则缺失?幻觉?上下文不足? |
| 偏差类别分布 | 知道 AI 在哪出错 —— 布局?组件?API? |
| 偏差 & 规则趋势图 | 看着偏差随规则积累而下降 |
| Bug 严重度分布 | 追踪质量 —— 哪个阶段产出严重 Bug? |
| 自检通过率趋势 | AI 代码质量是在变好还是变差? |
| 各阶段任务完成 | 看到完整开发生命周期的进度 |
| 文件修改热点 | 哪些文件反复被改?痛点在哪? |
| 规则溯源表 | 每条规则都关联到产生它的偏差 |
| 完整开发时间线 | 每个任务、Bug、审查、偏差 —— 按时间排列 |
| 项目总览(团队视角) | 跨分支统计、开发者对比、需求状态 |
运行 npx ai-dev-analytics dashboard,几秒钟看到你自己项目的数据。
AIDA 只往项目里的 .aida/ 目录写 JSON 文件。整个代码库不包含任何外部 HTTP 请求 —— 不发遥测、不上传云端、不请求分析服务、不做任何追踪。你的代码和数据不会离开你的电脑。
.mcp.json 里加一行{ "mcpServers": { "aida": { "command": "npx", "args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"] } } }
不需要 SDK,不需要包装器,不需要改代码。把这行加到项目根目录的 .mcp.json,AI 下次写代码时 AIDA 就开始采集数据。
如果
npx较慢,可以先全局安装:npm install -g ai-dev-analytics,然后把 command 改成"aida"。全局安装后也可以直接使用aida命令。
Cursor .cursor/mcp.json:
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}
VS Code Copilot .vscode/mcp.json:
{
"servers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}
Windsurf ~/.codeium/windsurf/mcp_config.json:
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}
Lingma(通义灵码) .lingma/mcp.json:
{
"mcpServers": {
"aida": {
"command": "npx",
"args": ["--registry=https://registry.npmjs.org/", "-y", "ai-dev-analytics", "mcp"]
}
}
}
npx ai-dev-analytics dashboard
打开 http://localhost:2375,即可查看本地数据看板。
下面这些是最常见的落地场景。想看详细行为、重复执行语义和边界说明,直接跳到 COMMANDS.md。
详细步骤见:COMMANDS.md / 场景 1:新项目初始化
适用场景:
.aida操作:
aida init
你会在交互里选择:
collect 或 full 模式初始化后建议立即检查:
aida build
aida status
详细步骤见:COMMANDS.md / 场景 2:老项目迁移
适用场景:
.aidevos最省事的方式:
aida migrate-legacy
如果你想显式指定 baseline tool:
aida migrate-legacy cursor
aida migrate-legacy codex
如果你想拆开执行:
aida migrate-dir
aida import cursor
aida migrate
aida memory rebuild
aida build
详细步骤见:COMMANDS.md / 场景 3:项目已初始化,但想补齐缺失产物
适用场景:
AGENTS.md / CLAUDE.md / .codex/config.toml 被删了操作:
aida init
然后在交互里选:
Repair missing generated files或者直接跑:
aida build
aida migrate-legacy
其中:
aida build 适合“真源没问题,只想重建产物”aida migrate-legacy 适合“历史项目想顺手补齐 memory / import / build 全链路”.aida/*.json详细步骤见:COMMANDS.md / 场景 4:import 和 build 怎么配合
适用场景:
.cursor/、.claude/、.codex/ 本地规则.aida/rules.json / .aida/skills.json操作:
aida import
aida import cursor
aida import codex
经验上:
import:适合把当前项目里能发现的资产统一扫回 AIDA回收后建议再跑一次:
aida build
详细步骤见:COMMANDS.md / 场景 5:rules 冲突
适用场景:
git pull / git merge 后 .aida/rules.json 出现 conflict marker操作:
aida rules merge
如果你想顺手把 skills.json 也一起处理:
aida merge
然后建议检查:
aida rules dedupe
aida build
详细步骤见:COMMANDS.md / 场景 6:skills 冲突
适用场景:
.aida/skills.json 出现 conflict marker操作:
aida merge
或者只处理 skills:
aida skills merge
处理完建议再跑:
aida build
相关操作见:COMMANDS.md / 场景 5:rules 冲突
适用场景:
操作:
aida rules dedupe
它会:
如果你手工改了 .aida/rules.json,记得再跑:
aida rules build
详细步骤见:COMMANDS.md / 场景 8:发布前自检
如果你准备发包,至少建议在当前项目里跑一遍:
npm run build
npm test
npm pack --dry-run
aida build
aida import codex
aida migrate-legacy codex
aida rules build
aida rules dedupe
如果仓库里还有冲突样本,建议再补:
aida rules merge
aida merge
aida init
aida migrate-dir
aida migrate-legacy
aida init:初始化新项目;如果项目已初始化,会进入“新增工具 / 修复缺失产物 / 退出”的分支。aida migrate-dir:只做 .aidevos -> .aida 目录迁移与路径替换;已经迁过时会安全 no-op。aida migrate-legacy:一键迁移老项目;即使项目已经是 .aida,也可以重跑,用于补建之前缺失的产物。aida build
aida merge
aida rules build
aida rules dedupe
aida build:从 .aida/*.json 真源重建规则视图、技能、工具侧产物、MCP 配置和 memory 视图。aida merge:解决 .aida/rules.json / .aida/skills.json 的 git conflict 内容。aida rules build:只重建规则相关产物。aida rules dedupe:先移除完全重复的规则,再提示近似重复/潜在冲突的规则。详细说明见 COMMANDS.md。
AIDA 用 fingerprint 判断 exact duplicate。生成规则如下:
trimsha256fingerprint这意味着以下内容会被视为同一条规则:
禁止任何形式的臆想,不清楚必须询问禁止任何形式的臆想,不清楚必须询问禁止任何形式的臆想,不清楚必须询问!aida rules dedupe 不只看 fingerprint。对于不同 fingerprint 的规则,它会继续做近似判断:
category 下的规则fingerprint 一致的归一化规则做文本清洗>= 0.4 时,标记为 potential duplicate这类规则不会自动合并,只会提示人工处理。原因很简单:语义相近不代表可以安全替换。
rules add:按 fingerprint 阻止新增完全重复规则merge:按 fingerprint 合并冲突两侧规则build:分发规则视图时会过滤 exact duplicate,避免生成产物里重复出现rules dedupe:会把 rules.json 里已经存在的 exact duplicate 清掉,并继续提示 near duplicate重复执行的目标是补全缺失,不破坏用户手工内容。当前策略如下。
aida init
aida migrate-dir
.aida 时:直接 no-opaida migrate-legacy
AGENTS.md / CLAUDE.md
.mcp.json / .cursor/mcp.json / .lingma/mcp.json
aida MCP server 合进去.codex/config.toml
[mcp_servers.aida] 片段,保留其他配置.gitignore
以下属于 AIDA 受管生成产物,重复执行会按 .aida/*.json 真源重建:
.aida/rules/*.md.aida/memories/modules/*.md.aida/runs/*/context.md.cursor/rules/aida/*.codex/rules/aida/*.claude/rules/aida/*.lingma/rules/*这部分不建议手改。若手改,再次 build / repair / migrate-legacy 时会被覆盖,这是预期行为。
.aida/*.json 真源aida init -> repair 或 aida migrate-legacyAIDA 不只是可视化 —— 它沉淀数据。每次运行都积累结构化数据,时间越长价值越大。
第 1 周:47 个任务、23 个偏差、5 个 Bug、6 条规则、4064 行代码
第 4 周:180+ 任务、偏差率持续下降、15 条规则、完整质量历史
一个季度:完整的开发记录 —— 可导出、可分析、可汇报
所有数据都在 .aida/ 里,格式是结构化 JSON。没有厂商锁定,随时可以导出、查询或接入别的报表系统。
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows