

Are you the author? Sign in to claim
AKB — Agent Knowledgebase. Organizational memory for AI agents: vault-scoped docs / tables / files unified by URI graph,
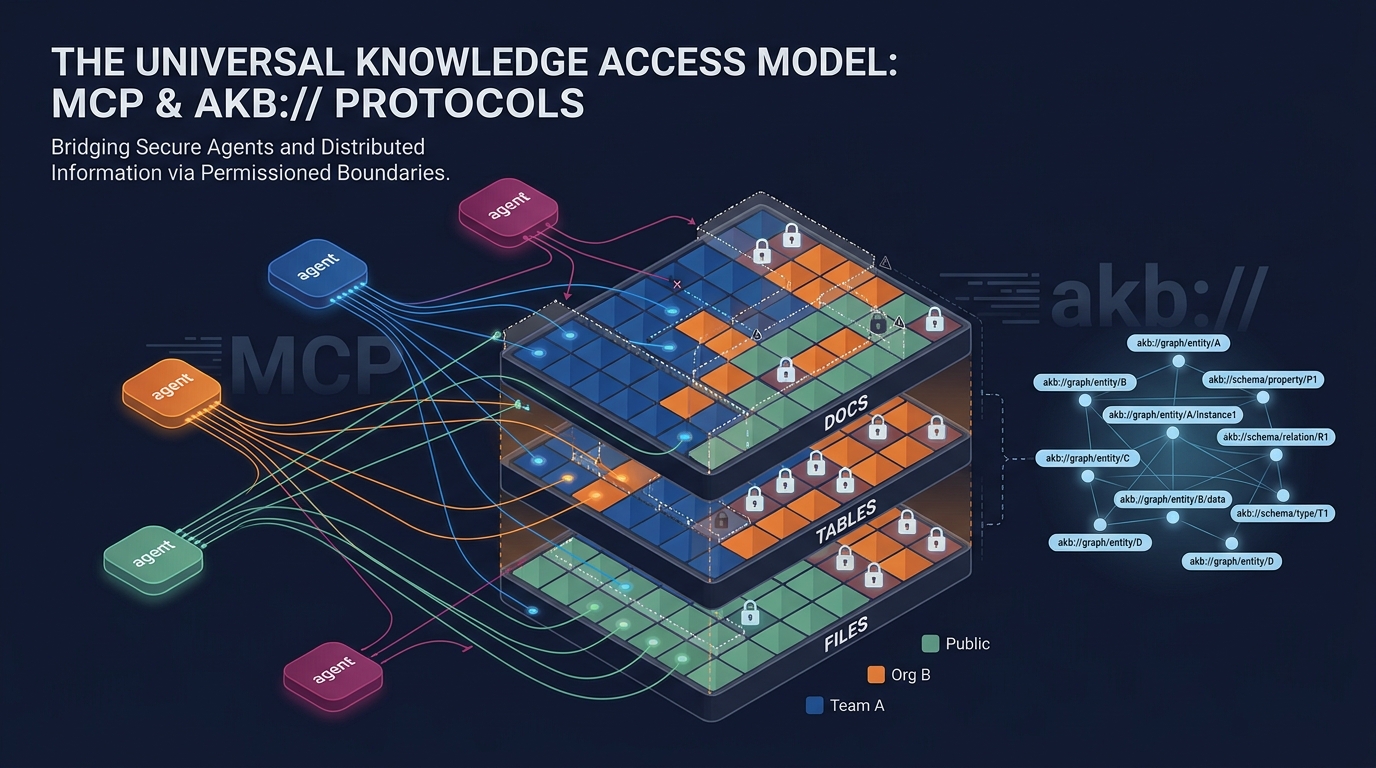
Organizational memory for AI agents. Git-backed knowledge base served over the Model Context Protocol (MCP) — agents read and write directly with hybrid semantic + keyword search, structured tables, files, and a URI graph. Drop-in alternative to Confluence / Notion for Claude Code, Cursor, Windsurf, and any MCP-aware agent.
![]()

![]()
Any agent client that speaks MCP (Streamable HTTP or stdio):
akb-mcp stdio proxyPOST /mcp/ with a Bearer tokenA public demo runs at akb-demo.agent.seahorse.dnotitia.ai.
Browse and search a small fictional-organization knowledge base — product docs,
a company handbook, agent session notes, and an engineering wiki, cross-linked
by the URI graph — right in your browser, no signup. To wire it into your own
agent, sign up with any email (a throwaway address is fine) and point the
akb-mcp proxy at
https://akb-demo.agent.seahorse.dnotitia.ai/mcp/.
⚠️ Throwaway demo. It is public, wiped and re-seeded weekly, and runs on minimal resources with no uptime, privacy, or data guarantees. Don't put anything real or sensitive in it — treat every write as public and ephemeral. For real use, self-host in three containers.
Most knowledge tools are built for humans clicking through a UI. Agents need a
different shape: structured documents, semantic + keyword search in one call,
explicit relations, and full version history. AKB gives agents a single set of
tools (akb_put, akb_search, akb_browse, akb_relations, …) over a
backing store of Git bare repos and a PostgreSQL hybrid index.
Memory is only useful if the right note comes back. AKB's hybrid retrieval (dense + BM25, source-level dedup) was benchmarked on LongMemEval-S — 500 long-context questions, ~50 chat sessions per question. Recall@5 = 98.4%, with no reranker in the loop.
| System | R@5 | n | Reranker | Source |
|---|---|---|---|---|
| AKB hybrid | 98.4% | 500 | no | this repo |
| MemPalace hybrid + rerank | 98.4% | 450 | yes | MemPalace |
| gbrain hybrid | 97.6% | 500 | no | gbrain-evals |
| gbrain vector | 97.4% | 500 | no | gbrain-evals |
Methodology, per-category breakdown, and a one-command reproducible harness
live in eval/longmemeval/. The embedding model differs
across systems (AKB: bge-m3@1024), so read this as a stack-level comparison.
Core stays small; flexibility comes from extension, not built-in
automation. AKB does not ship its own consolidator, summariser, or
"knowledge gardener" — instead every write emits a structured event to a
Redis Stream (akb:events). Operators wire any external consumer
(periodic synthesis bot, doc-rot reaper, weekly-digest agent, audit
trail, …) on top, with no patches to the core. The base contract is a
read/write store; opinions about what to do with the knowledge live
outside.
┌──────────────────────────────────────────────────────────┐
│ Access Layer │
│ MCP Server │ REST API │ Web UI │
├──────────────────────────────────────────────────────────┤
│ Core Services │
│ Document (Put/Get) │ Search (Hybrid: dense+BM25) │
│ Relations (graph) │ Session │ Publications │
├──────────────────────────────────────────────────────────┤
│ Storage Layer │
│ Git bare repos │ PostgreSQL 16 (text + meta SoT)│
│ │ Vector store (driver): │
│ │ pgvector (default, PG)│
│ │ qdrant (optional) │
│ │ seahorse-cloud (managed) │
│ │ seahorse-db (self-hosted)│
│ │ seahorse-db-grpc(experimental)│
└──────────────────────────────────────────────────────────┘
PostgreSQL is the source of truth — chunk text + metadata + BM25 vocab.
The vector store is a driver-pluggable derived index holding dense
embeddings and corpus-side sparse vectors. Full vector-store loss is
recoverable from PG by setting chunks.vector_indexed_at = NULL and
letting the indexing worker re-populate.
depends_on, related_to, implements in frontmatter form an explicit knowledge graph.akb_sql — Enforced by PostgreSQL ACL. Each
AKB user has a corresponding PG role (akb_user_<uid>) and each
vault has three group roles (akb_vault_<vid>_{reader,writer,admin}).
akb_sql runs the user's SQL inside a transaction with
SET LOCAL ROLE; cross-vault references return PG 42501
directly. No application-side regex inspects user SQL for forbidden
identifiers. See docs/designs/pg-native-rbac/.| Tool | Description |
|---|---|
akb_list_vaults / akb_create_vault | Vault management |
akb_put / akb_get / akb_update / akb_delete | Document CRUD (Git commit + indexing) |
akb_put_file / akb_get_file / akb_delete_file | File attachments — proxy-side (requires local filesystem) |
akb_create_table / akb_alter_table / akb_drop_table / akb_sql | Tabular content — per-doc tables + SQL |
akb_browse | Tree traversal (collection → docs) |
akb_search / akb_grep | Hybrid search (dense + BM25) / literal grep |
akb_drill_down | Section-level retrieval |
akb_relations / akb_link / akb_unlink / akb_graph | Knowledge graph |
akb_edit / akb_diff / akb_history | In-place edit, diff, Git history |
akb_grant / akb_revoke / akb_set_public | Permission boundaries — per-user, per-org, public |
akb_publish / akb_unpublish | Public publication |
Agent memory and session lifecycle are not MCP tools — they live on
the dedicated /api/v1/agent-sessions REST surface, driven by AKB
lifecycle plugins (akb-claude-code, akb-cursor, …) that hook into
the agent's own SessionStart / PreCompact / SessionEnd events. As an
agent, your own memory vault (agent-memory-{username}) is browsable
through the standard akb_search / akb_browse / akb_get tools
exactly like any other vault.
The full tool catalogue is exposed via akb_help() from any MCP client.
Every vault resource has a location-aware AKB URI — the canonical handle used by every tool and stored in relations. As of 0.3.0:
akb://{vault} vault root (browse target)
akb://{vault}/coll/{coll_path} collection (browse target)
akb://{vault}[/coll/{coll_path}]/doc/{filename} document
akb://{vault}[/coll/{coll_path}]/table/{name} table
akb://{vault}[/coll/{coll_path}]/file/{uuid} file
The /coll/{coll_path} segment is omitted for resources at the vault
root. Walking up a URI to its parent collection is a pure string
operation — paste the parent into akb_browse(uri=...) to list
siblings without an extra lookup.
---
title: "Payment API v2 migration plan"
type: plan # note | report | decision | spec | plan | session | task | reference
status: active # draft | active | archived | superseded
tags: [payments, api]
domain: engineering
summary: "REST → gRPC transition plan."
depends_on: ["akb://eng/coll/specs/doc/payment-api-v2.md"]
related_to: ["akb://eng/coll/meetings/doc/2026-05-01-payments.md"]
---
# Payment API v2 migration plan
...
AKB ships as a 3-container stack (PostgreSQL with pgvector + backend +
frontend). For semantic (dense) search you bring an OpenAI-compatible
embedding endpoint (OpenAI, OpenRouter, self-hosted vLLM/TEI, etc.). It is
not strictly required: with no embed endpoint (or during an outage) the
pgvector and Qdrant drivers degrade to BM25-only lexical search rather
than returning nothing — dense is genuinely optional end-to-end (the
seahorse-db driver is the exception; see Vector store below). Prefer
running a separate Qdrant cluster, or pointing at Seahorse? See Vector
store below.
# 1. Configure
cp config/app.yaml.example config/app.yaml
cp config/secret.yaml.example config/secret.yaml
$EDITOR config/secret.yaml # set embed_api_key (and jwt_secret for any non-local deploy)
# 2. Run
docker compose up -d
# 3. Open
open http://localhost:3000
config/app.yaml and config/secret.yaml are the single source of runtime
configuration — no environment variables are read by the backend. Mount the
config/ directory at /etc/akb/ in any deployment.
Hybrid search (dense + BM25 sparse, RRF-fused) runs through a driver interface. Five drivers ship; pick at config time:
pgvector (default) — uses the same Postgres container that holds
application data. The pgvector/pgvector image pre-installs the
extension; the driver creates a separate vector_index schema, so the
main chunks table stays plain PostgreSQL. RRF fusion runs
application-side. No external service to operate.qdrant — runs a separate Qdrant container; native RRF via the
Query API. Useful when you already operate Qdrant or want to scale
the vector store independently of Postgres.seahorse-cloud — points at a managed Seahorse Cloud table
over its BFF management API + per-table data-plane host (Bearer auth).
No infrastructure to run on your side; you provision a table in the
Seahorse console (or let the driver auto-create one) and AKB stores
its chunks there. Native RRF, server-side BM25. See
docs/vector-store-seahorse.md
for the end-to-end setup walkthrough (sign-up → token → schema →
config).seahorse-db — points at a self-hosted SeahorseDB cluster via
its Coral coordinator HTTP API. You run Coral + Writer + Reader(s) +
Redis + Kafka + a sparse-embedding server yourself (the SeahorseDB
monorepo's deploy/docker-compose.yml brings up a minimal single-box
stack). Native dense+sparse hybrid. Unlike the other drivers it does
not support BM25-only fallback when the embed API is down (its
sparse path is server-side and structurally coupled to a live embed
step) — keep an embedding endpoint reachable for this driver.seahorse-db-grpc (experimental) — same Coral coordinator as
seahorse-db, same seahorsedb_* settings, but talks gRPC instead
of REST/JSONL. Coral merges axum + tonic onto a single listener so
the port doesn't change; only the wire format does. Trades the JSON
parsing path (and a class of foot-guns like INT64 sign mismatch and
Arrow JSON decoder edge cases) for typed protobuf messages and an
Arrow IPC streaming result. Prefer the REST driver for production
until the gRPC variant clears its own QPS / recall benchmark. Same
CRUD parity with REST (passes the same 25-scenario hybrid e2e), but
it has not yet had the production-scale exposure the REST driver
has.Switching drivers is a config edit (no schema migration on the main DB):
# Default flow targets pgvector.
docker compose up
# Qdrant:
docker compose -f docker-compose.yaml -f docker-compose.qdrant.yaml up
$EDITOR config/app.yaml # vector_store_driver: qdrant
# vector_url: http://qdrant:6333
# Seahorse Cloud (managed; full guide in docs/vector-store-seahorse.md):
docker compose up # no extra container needed
$EDITOR config/app.yaml # vector_store_driver: seahorse-cloud
# seahorse_cloud_tenant_uuid: <your tenant>
# seahorse_cloud_table_name: <your table>
$EDITOR config/secret.yaml # seahorse_cloud_token: shsk_<...>
# SeahorseDB (self-hosted cluster reached via the Coral coordinator):
docker compose up # run the SeahorseDB stack separately
$EDITOR config/app.yaml # vector_store_driver: seahorse-db
# seahorsedb_coordinator_url: http://localhost:3003
# seahorsedb_table_name: akb_chunks
Embedding model + dimensions are also fully pluggable via
embed_base_url / embed_model / embed_dimensions — the codebase has
no hard-coded model. For pgvector with HNSW, keep embed_dimensions ≤ 2000
(or 4000 with halfvec); larger models fall back to exact scan.
Qdrant / Seahorse (cloud or db) have no such limit (Qdrant up to 65536,
Seahorse up to its table-defined dim).
LLM is only used by the metadata_worker to auto-tag documents imported via
external git mirroring. Core CRUD/search works without it. To enable, set
llm_base_url / llm_model in app.yaml and llm_api_key in secret.yaml.
The PG events outbox is always written. Set redis_url in app.yaml to
have the events_publisher worker drain the outbox to a Redis Stream
(akb:events) so external services can subscribe via XREAD / consumer
groups. Leave blank to disable; events still accumulate in PG and you can
build an SSE endpoint on top of the LISTEN/NOTIFY trigger without Redis.
Off by default. Set audit.enabled: true in app.yaml to emit a structured,
append-only, hash-chained JSON-lines audit log at the MCP dispatch
chokepoint — every read, write, and auth denial, uniformly. AKB is a
producer only: it does not store, query, or retain audit data; your SIEM
(Splunk/QRadar/Elastic) scrapes the stream and owns retention under its own
compliance regime. Each line carries a monotonic seq plus
sha256(prev ‖ line), so the chain can be verified for dropped or altered
lines and re-seeds from disk across restarts. Optionally hand the daily
rolled file off to a WORM object-storage bucket (audit.bucket —
provision with Object Lock and a write-only key for a true immutable trail);
the local buffer is pruned only after a confirmed upload. Capture is
best-effort and never raises into the serving path. See
config/app.yaml.example for the full audit: block.
For Kubernetes, see deploy/k8s/README.md. The
deploy/k8s/ directory contains a generic kustomize base; provide your
own registry, hostname, and TLS issuer via the documented env vars or an
operator-private overlay under deploy/k8s/internal/.
akb/
├── backend/ # Python 3.14 / FastAPI / asyncpg / GitPython
│ ├── app/
│ │ ├── api/routes/ # REST endpoints
│ │ ├── services/ # Business logic + workers
│ │ └── db/ # PostgreSQL schema + migrations
│ ├── mcp_server/ # Streamable HTTP MCP server
│ └── tests/ # E2E shell tests
├── frontend/ # React 19 + TypeScript + Vite + Tailwind
├── packages/
│ └── akb-mcp-client/ # stdio ↔ HTTP MCP proxy (npm: akb-mcp)
├── agents/ # Reference Python agent runtime (think/act loop over MCP)
├── templates/ # Doc templates (ADR, PRD, runbook, …) and vault profiles
├── design-system/ # Frontend design system docs
├── config/
│ ├── app.yaml.example # Non-secret runtime settings
│ └── secret.yaml.example # API keys, passwords (gitignored when not .example)
├── deploy/
│ └── k8s/ # Generic kustomize base for Kubernetes
└── docker-compose.yaml # 3-container local stack (postgres + backend + frontend)
events outbox + Redis Streams fanoutakb-mcp on npm)AKB follows SemVer. The product version lives in
backend/pyproject.toml ([project].version) and is mirrored to
frontend/package.json via scripts/bump-version.sh <x.y.z>. Each
deploy/k8s/deploy.sh run tags the Docker images with both the explicit
version (:${VERSION}) and :latest, so historical builds remain
pullable for rollback.
packages/akb-mcp-client (the akb-mcp npm proxy) follows its own npm
semver lifecycle and is not tied to the product version.
The AKB backend, frontend, and deployment manifests are licensed under the Business Source License 1.1 — source-available, with an Additional Use Grant that permits production use (commercial or non-commercial) up to a seat-count threshold, automatically converting to Apache License 2.0 four years after each version's first public release.
The npm akb-mcp proxy (packages/akb-mcp-client/) is separately
licensed under the MIT License so it can be freely embedded in any
agent client without restriction.
Free production use of the backend — you may deploy AKB in
production, commercial or not, provided your aggregate deployment
serves fewer than 100 Named Seats (distinct human user accounts in
the users table, per deployment; service accounts and
90-day-inactive accounts excluded — see LICENSE for the
precise definition).
Commercial license required for any of:
Trademarks — "AKB", "Dnotitia", and "Seahorse" are trademarks of Dnotitia, Inc. The software license does not grant trademark rights. Forks and derivative works must be distributed under a different name. See TRADEMARKS.md.
For commercial licensing, the rationale behind the BSL transition, or trademark permission requests, see LICENSE-CHANGE.md or contact support@dnotitia.com.
Found a vulnerability? See SECURITY.md — please report privately, not via public issues.
See CONTRIBUTING.md.
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows