

Are you the author? Sign in to claim
Source code for our paper: "ARIA: Training Language Agents with Intention-Driven Reward Aggregation".
![]()

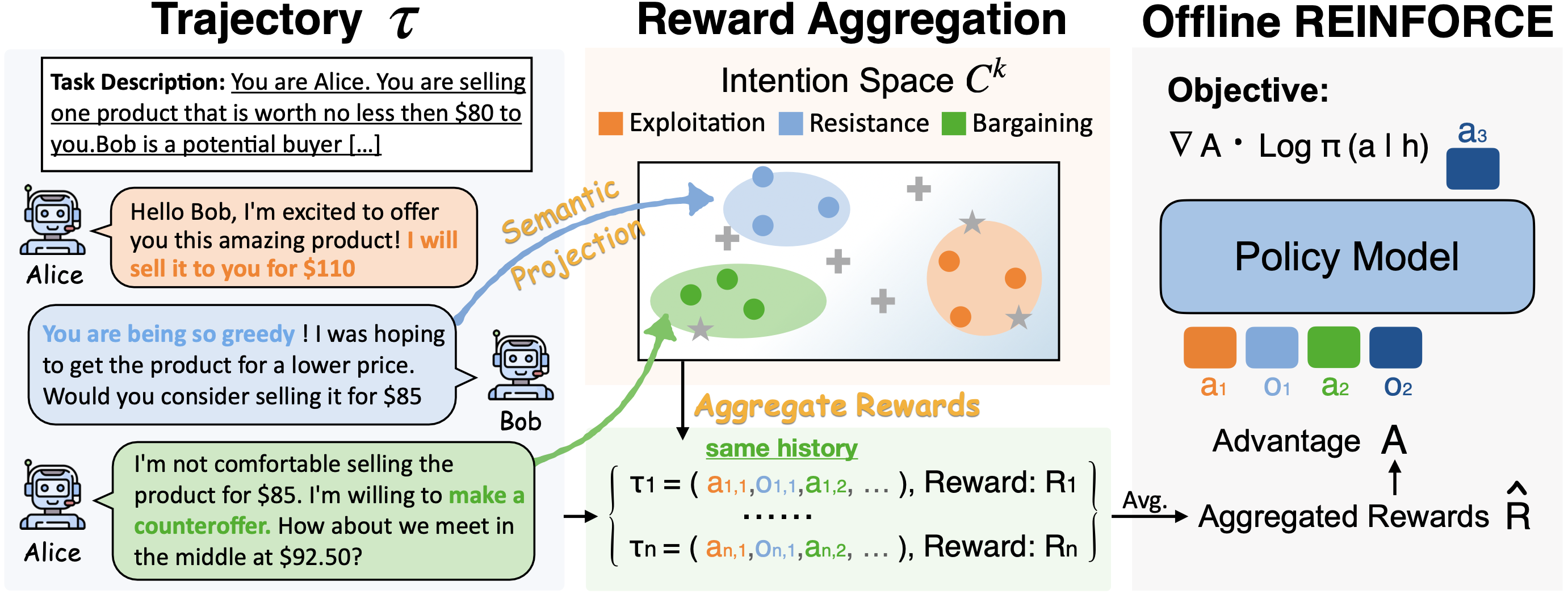
Large language models (LLMs) have enabled agents to perform complex reasoning and decision-making through free-form language interactions. However, in open-ended language action environments (e.g., negotiation or question-asking games), the action space can be formulated as a joint distribution over tokens, resulting in an extremely large and combinatorial action space. Sampling actions in such a space can lead to extreme reward sparsity, which brings large reward variance, hindering effective reinforcement learning.
To address this, we propose ARIA, a method that Aggregates Rewards in Intention space to enable efficient and effective language Agents training. ARIA aims to project natural language actions from the high-dimensional joint token distribution space into a low-dimensional intention space, where semantically similar actions are clustered and assigned shared rewards. This intention-aware reward aggregation reduces reward variance by densifying reward signals, fostering efficient and effective policy optimization.
Extensive experiments demonstrate that ARIA not only significantly reduces gradient variance, but also delivers substantial performance gains of average 9.95% across four downstream tasks (e.g., negotiation and text-based games), consistently outperforming strong offline and online RL baselines.
You can install ARIA using the following steps:
# Create and activate conda environment
conda create -n aria python=3.10
conda activate aria
# Install the package
pip install -e .
The complete data processing pipeline transforms raw game data into training-ready datasets through several steps:
Starting with raw game data llama3-8b_{game}_msgs.jsonl, generate clustering labels for different k values (k=2 to k=100):
# For different game environments
cd reward_aggregation/{game}_clustering
python preprocesspy
python clustering.py
python postprocess.py
Supported games:
bargaining (multi-agent)negotiation (multi-agent)guess_my_city (single-agent with actions & observations)twenty_questions (single-agent with special observation processing)Determine the optimal k values for clustering using silhouette analysis:
cd clustering
# For multi-agent games (bargaining, negotiation)
python clustering_multi.py --data_path {game}_clustering
# For single-agent games (guess_my_city, twenty_questions)
python clustering_single.py --data_path {game}_clustering
This will output the optimal k values for each agent/component.
Use the optimal k values to generate the final labeled dataset:
cd clustering
python game_data_processor.py {environment} {input_file} {output_file}
Examples:
# Multi-agent games (bargaining, negotiation)
python game_data_processor.py bargaining \
llama3-8b_bargaining_with_labels_k2_to_k100.jsonl \
llama3-8b_bargaining_with_selected_labels.jsonl \
--alice-k 20 --bob-k 20
python game_data_processor.py negotiation \
llama3-8b_negotiation_with_labels_k2_to_k100.jsonl \
llama3-8b_negotiation_with_selected_labels.jsonl \
--alice-k 16 --bob-k 16
# Single-agent with action/observation clustering
python game_data_processor.py guess_my_city \
llama3-8b_guess_my_city_with_labels_k2_to_k100.jsonl \
llama3-8b_guess_my_city_with_selected_labels.jsonl \
--action-k 28 --observation-k 28
# Single-agent with special observation processing
python game_data_processor.py twenty_questions \
llama3-8b_twenty_questions_with_labels_k2_to_k100.jsonl \
llama3-8b_twenty_questions_with_selected_labels.jsonl \
--k 36
Convert the processed data into the final training format:
cd clustering
python gen_reinforce_multi.py
The final dataset will be saved to /ARIA/dataset/actor_reinforce_llama3-8b_multi.json and is ready for training.
The complete pipeline:
llama3-8b_{game}_msgs.jsonl
↓ (Step 1: preprocess.py clustering.py postprocess.py)
llama3-8b_{game}_with_labels_k2_to_k100.jsonl
↓ (Step 2: clustering_multi/single.py)
optimal k values
↓ (Step 3: game_data_processor.py)
llama3-8b_{game}_with_selected_labels.jsonl
↓ (Step 4: gen_reinforce_multi.py)
actor_reinforce_llama3-8b_multi.json
cd scripts
# Offline training
python run_offline.py --config-name reinforce_llm
accelerate launch --config_file config/accelerate_config/default_config.yaml run_offline.py --config-name reinforce_llm
# Online training
python run_online.py --config-name onlinereinforce_llm
accelerate launch --config_file config/accelerate_config/default_config.yaml run_online.py --config-name onlinereinforce_llm
We train a reward model (RM) using past rollout results from the actor (updated every 50 steps) to ensure accurate advantage estimation for the actor.
cd scripts
bash train_rm.sh
To evaluate your model in single-agent environments (e.g., Twenty Questions, Guess My City), follow these steps:
First, make sure your model is served using vLLM. Here's an example command:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m model_path --port 8036 --tensor-parallel-size 4 --gpu_memory_utilization 0.6
model_path with your actual model module or entry point.http://localhost:8036.Navigate to the evaluation directory and execute the evaluation script:
cd evaluation
bash eval.sh
The script does the following:
twenty_questions and guess_my_city.BASE_URL.llama3-8B (you can change this by editing MODEL_NAME in eval.sh).../results/single_agent/llama3-8B.⚠️ Experimentelle Skill-Sammlung für deutsches Recht (Arbeits-, Gesellschafts-, Insolvenz-, Datenschutz-, Prozessrecht u
Manage multiple Claude Code agents from TUI or Web with tmux and git worktrees
Project management using GitHub Issues + Git worktrees for parallel agent execution
Core skills library for Claude Code with 20+ battle-tested skills including TDD, debugging, and brainstorming
