

Are you the author? Sign in to claim
claude-code-token-optimization
Usage : Paste this prompt directly into a Claude Code session. Claude will run the audit and optimization autonomously, phase by phase. Series : Companion to claude-code-best-practice-playbook — full setup & workflow reference.
Version : Claude Code ≥ 2.1 · Last updated: 2026-03 · Verify with
claude --version
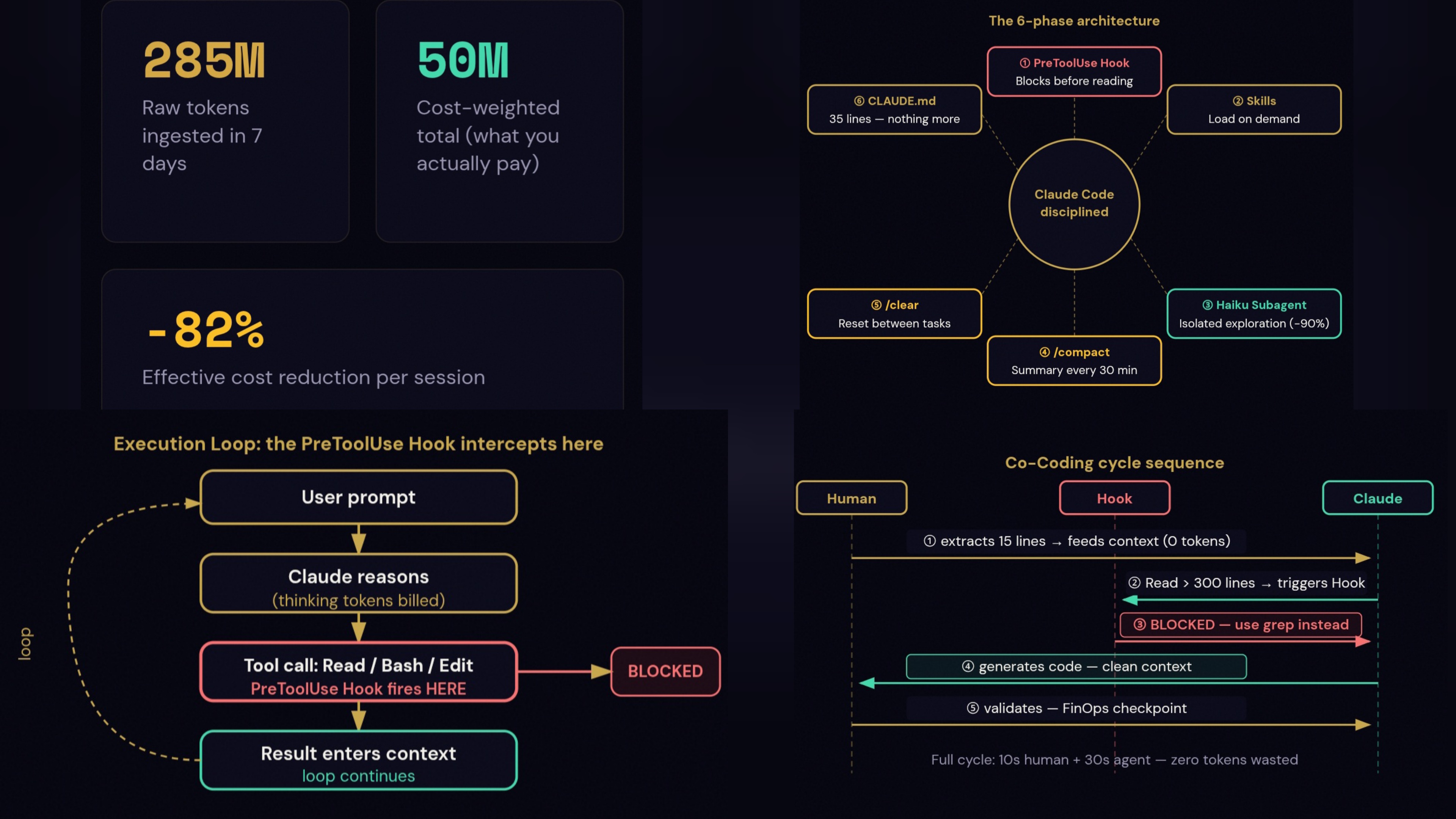
You are tasked with performing a comprehensive self-optimization of this Claude Code environment to minimize startup context cost and per-turn token waste while maintaining full task performance. This is a systematic audit-and-refactor mission.
Work through each phase below in order. Create all files. Report token estimates at each step. Do not ask for confirmation between phases — execute autonomously.
Run the following diagnostics and report results:
# 1a. Estimate current CLAUDE.md token cost
echo "=== Global CLAUDE.md ===" && wc -l ~/.claude/CLAUDE.md 2>/dev/null || echo "No global CLAUDE.md"
echo "=== Project CLAUDE.md ===" && wc -l .claude/CLAUDE.md 2>/dev/null || echo "No project CLAUDE.md"
# 1b. Count all @imported files referenced in CLAUDE.md
grep -h "@" ~/.claude/CLAUDE.md .claude/CLAUDE.md 2>/dev/null | grep -v "^#" | grep -v "<!--"
# 1c. List all skills loaded at startup
echo "=== User skills ===" && ls ~/.claude/skills/ 2>/dev/null || echo "none"
echo "=== Project skills ===" && ls .claude/skills/ 2>/dev/null || echo "none"
# 1d. List all subagents
echo "=== User agents ===" && ls ~/.claude/agents/ 2>/dev/null || echo "none"
echo "=== Project agents ===" && ls .claude/agents/ 2>/dev/null || echo "none"
# 1e. Check model and effort level
cat ~/.claude/settings.json 2>/dev/null | python3 -c "
import json, sys
d = json.load(sys.stdin)
print('model:', d.get('model', 'not set'))
print('effortLevel:', d.get('effortLevel', 'not set'))
print('MAX_THINKING_TOKENS:', d.get('env', {}).get('MAX_THINKING_TOKENS', 'not set'))
" 2>/dev/null || echo "No ~/.claude/settings.json"
# 1f. Check project hooks
cat .claude/settings.json 2>/dev/null | python3 -c "
import json, sys
d = json.load(sys.stdin)
hooks = d.get('hooks', {})
print('Hooks configured:', list(hooks.keys()) if hooks else 'none')
" 2>/dev/null || echo "No .claude/settings.json"
# 1g. Estimate total startup token cost
python3 -c "
import os, glob
def tokens(path):
try:
with open(os.path.expanduser(path)) as f:
return len(f.read()) // 4
except:
return 0
g = tokens('~/.claude/CLAUDE.md')
p = tokens('.claude/CLAUDE.md')
skills_startup = 0 # skills are on-demand
print(f'Startup context cost today: ~{g + p} tokens per session')
print(f' Global CLAUDE.md : ~{g} tokens')
print(f' Project CLAUDE.md: ~{p} tokens')
"
Report the audit summary before proceeding to Phase 2.
Rule : CLAUDE.md must be ≤ 200 lines. Everything workflow-specific goes into on-demand Skills.
In the current CLAUDE.md files, identify and tag each section:
| Category | Action |
|---|---|
| Workflow-specific (PR review, DB migrations, test patterns) | → Move to Skill |
| Verbose explanations (>3 lines for one rule) | → Compress to 1 line |
| Context Claude already knows (basic Python, git, etc.) | → Delete |
| Old/deprecated patterns | → Delete |
HTML comments <!-- notes --> inside CLAUDE.md | → Keep (they are stripped from context automatically) |
~/.claude/CLAUDE.md (global) <> see an example here to CCBPPHard limit : 200 lines. Content to keep:
Always include this compact instruction block at the top:
# Compact instructions
When compacting, preserve: modified file list, test commands, active task state, TODO markers.
Discard: exploration history, failed attempts, verbose tool output logs.
.claude/CLAUDE.md (project)Hard limit : 150 lines. Content to keep:
Do NOT copy global rules — they are already loaded from ~/.claude/CLAUDE.md.
Move all PR / DB / deploy workflows → Skills (Phase 3).
python3 -c "
import os
def tokens(path):
try:
with open(os.path.expanduser(path)) as f:
return len(f.read()) // 4
except:
return 0
print(f'Global CLAUDE.md after: ~{tokens(\"~/.claude/CLAUDE.md\")} tokens')
print(f'Project CLAUDE.md after: ~{tokens(\".claude/CLAUDE.md\")} tokens')
"
Skills load only when invoked. Moving workflow docs from CLAUDE.md to skills = free tokens at startup. Each SKILL.md must be ≤ 80 lines, concise, no padding.
pdf-to-contextPath : .claude/skills/pdf-to-context/SKILL.md
---
name: pdf-to-context
description: Convert PDF or large document to token-efficient markdown before analysis.
Triggers: "read this PDF", "analyze document", "summarize this file", any .pdf or .docx reference.
---
# PDF → Markdown Preprocessing
## ALWAYS do this before reading any PDF or large document into context
### Step 1: Extract text (never read raw PDF binary into context)
```bash
# Method A — pdftotext (fastest)
pdftotext "$FILE" - | head -c 50000
# Method B — pdfplumber (preserves tables)
python3 -c "
import pdfplumber, sys
with pdfplumber.open(sys.argv[1]) as pdf:
text = '\n'.join(p.extract_text() or '' for p in pdf.pages)
print(text[:50000])
" "$FILE"
grep -A5 -B2 "keyword" extracted.md| Task | Max document tokens |
|---|---|
| Simple factual question | 2 000 |
| Analysis / comparison | 10 000 |
| Full summary | Use subagent (isolated context) |
python3 -c "import docx2txt, sys; print(docx2txt.process(sys.argv[1])[:50000])" "$FILE"
tail -100 logfile.log # Last 100 lines
grep -i "error\|warning\|fail" log.txt # Errors only
grep -A3 "FAILED" test_output.txt # Failed tests with context
context-managerPath : .claude/skills/context-manager/SKILL.md
---
name: context-manager
description: Manage context window health during long sessions.
Triggers: "context getting big", "clear context", "start fresh", "compact session",
long debugging sessions >30 min, Claude repeating mistakes.
---
# Context Window Management
## When to act
| Signal | Action |
|--------|--------|
| Session > 30 min active work | `/compact` |
| Switching to unrelated task | `/clear` (use `/rename` first) |
| Claude repeating mistakes / forgetting | `/compact` mandatory |
| Quick one-off question | `/btw [question]` — never enters context |
## Optimal /compact command
/compact Focus on: modified files list, current task state, failing test names, key decisions.
Discard: exploration history, verbose tool outputs, failed attempts.
For ANY research/exploration task, use this pattern:
"Use a subagent to investigate [TOPIC] and return a 200-word summary: key findings, relevant file paths, recommended approach."
Subagents run in separate context windows → your main context stays clean.
/clear between unrelated tasks/compact every ~30 min on long sessionscat large files — always grep/head/tail firstmodel-selectorPath : .claude/skills/model-selector/SKILL.md
---
name: model-selector
description: Choose the right model and effort level per task to minimize cost.
Triggers: "which model", "save tokens", "quick task", "simple fix", "complex architecture".
---
# Model & Effort Selection Matrix
| Task type | Model | Effort | Cost vs default |
|-----------|-------|--------|----------------|
| Typo fix, rename variable | haiku | low | ~10x cheaper |
| Write function, add test | sonnet | low | baseline |
| Debug complex bug | sonnet | medium | +30% |
| Architecture / design decision | sonnet high or opus | high | +3-5x, justified |
| Multi-file refactor | sonnet | medium | baseline |
| Subagent exploration tasks | haiku | low | ~10x cheaper |
## Session commands
```bash
/model # Open model picker
/effort low # Fast, cheap — routine tasks
/effort medium # Default balanced (recommended)
/effort high # Deep reasoning — justify the cost
---
model: haiku
effort: low
---
MAX_THINKING_TOKENS=8000 caps runaway thinking cost on simple tasksfetch-not-readPath : .claude/skills/fetch-not-read/SKILL.md
---
name: fetch-not-read
description: Use targeted Bash commands instead of full file reads to minimize context tokens.
Triggers: before reading any file >100 lines, "show me the code", "read this file",
"what does X do".
---
# Fetch-not-read Pattern
## Core principle
`Read(large_file.py)` dumps EVERYTHING into context.
Bash commands let you extract **exactly** what you need.
## Replacement patterns
### Structure overview (instead of reading whole file)
```bash
grep -n "^def \|^class " file.py # All functions/classes with line numbers
grep -n "^export\|^const\|^function" file.ts
sed -n '/^def target_function/,/^def /p' file.py | head -60
head -30 file.py
grep -n -A10 "keyword" file.py
grep -rn "function_name" --include="*.py" | head -20
grep -E "FAILED|ERROR|passed [0-9]+" pytest_output.txt | tail -30
grep -A5 "FAILED" pytest_output.txt
find . -name "*.py" | head -20
grep -r "function_name" --include="*.py" -l # Files containing it
| File size | Strategy |
|---|---|
| < 50 lines | OK to Read directly |
| 50–200 lines | Read only if full context needed |
| > 200 lines | Use Bash extraction ALWAYS |
| Entire directory | NEVER read all — use grep/find |
~/.claude/settings.json (global defaults + git safety). Find the full example hereRead the current file, then merge these optimizations (do not overwrite — merge).
This step adds three layers of protection :
deny — hard block (git push, rm -rf, curl, edit secrets)ask — Claude asks for your confirmation before executing (git commit, checkout)allow — pre-approved safe commands (git diff, grep, find)python3 << 'EOF'
import json, os
path = os.path.expanduser("~/.claude/settings.json")
try:
with open(path) as f:
settings = json.load(f)
except FileNotFoundError:
settings = {}
# Merge token-saving defaults
settings.setdefault("model", "claude-sonnet-4-6")
settings.setdefault("effortLevel", "medium")
settings.setdefault("env", {})
settings["env"]["MAX_THINKING_TOKENS"] = "8000"
# ── PERMISSIONS ─────────────────────────────────────────────
settings.setdefault("permissions", {})
# Allow: pre-approved safe commands (no confirmation prompt)
settings["permissions"].setdefault("allow", [])
allow_rules = [
"Bash(git diff *)", "Bash(git log *)", "Bash(git status *)",
"Bash(wc *)", "Bash(grep *)", "Bash(find *)",
"Bash(head *)", "Bash(tail *)", "Bash(sed -n *)"
]
for rule in allow_rules:
if rule not in settings["permissions"]["allow"]:
settings["permissions"]["allow"].append(rule)
# Deny: hard block — Claude cannot execute these under any circumstances
settings["permissions"].setdefault("deny", [])
deny_rules = [
# Protect secrets
"Read(./.env)", "Read(./.env.*)",
"Read(./secrets/**)", "Read(./.git/objects/**)",
"Edit(.env)", "Edit(.env.*)",
"Edit(./secrets/**)", "Edit(.git/**)",
# Block destructive git operations
"Bash(git push *)", "Bash(git push)",
"Bash(git push --force *)",
"Bash(git reset --hard *)",
# Block destructive system commands
"Bash(rm -rf *)",
# Block network exfiltration
"Bash(curl *)", "Bash(wget *)"
]
for rule in deny_rules:
if rule not in settings["permissions"]["deny"]:
settings["permissions"]["deny"].append(rule)
# Ask: Claude requests your confirmation before executing
settings["permissions"].setdefault("ask", [])
ask_rules = [
"Bash(git commit *)",
"Bash(git checkout *)",
"Bash(git branch -d *)",
"Bash(git stash *)"
]
for rule in ask_rules:
if rule not in settings["permissions"]["ask"]:
settings["permissions"]["ask"].append(rule)
# ── ATTRIBUTION ─────────────────────────────────────────────
# Remove Co-Authored-By: Claude from git commits and PRs
settings["attribution"] = {"commit": "", "pr": ""}
# ── GITIGNORE ───────────────────────────────────────────────
settings["respectGitignore"] = True
with open(path, "w") as f:
json.dump(settings, f, indent=2)
print("~/.claude/settings.json updated")
print(f" model : {settings['model']}")
print(f" effortLevel : {settings['effortLevel']}")
print(f" MAX_THINKING : {settings['env']['MAX_THINKING_TOKENS']}")
print(f" deny rules : {len(settings['permissions']['deny'])}")
print(f" ask rules : {len(settings['permissions']['ask'])}")
print(f" allow rules : {len(settings['permissions']['allow'])}")
print(f" attribution : commit='{settings['attribution']['commit']}' pr='{settings['attribution']['pr']}'")
print(f" respectGitignore: {settings['respectGitignore']}")
EOF
.claude/hooks/guard-large-read.sh (large file interceptor)This hook blocks accidental reads of files > 300 lines and suggests Bash alternatives. Estimated savings: 50,000+ tokens per long session.
Implementation : External script (not inline JSON) — aligned with the playbook §6. Easier to test independently with
echo '{...}' | bash .claude/hooks/guard-large-read.sh.
mkdir -p .claude/hooks
cat > .claude/hooks/guard-large-read.sh << 'HOOKEOF'
#!/bin/bash
# Block Read tool on files > 300 lines — enforce grep/sed extraction
set -euo pipefail
INPUT=$(cat)
FILE=$(echo "$INPUT" | python3 -c "
import json, sys
print(json.load(sys.stdin).get('tool_input', {}).get('file_path', ''))
" 2>/dev/null || echo "")
# Early exit: no file path or file doesn't exist
if [ -z "$FILE" ] || [ ! -f "$FILE" ]; then
exit 0
fi
LINES=$(wc -l < "$FILE" 2>/dev/null || echo 0)
if [ "$LINES" -gt 300 ]; then
python3 -c "
import json
print(json.dumps({
'decision': 'block',
'reason': (
'$FILE has $LINES lines (~' + str($LINES * 5) + ' tokens). '
'Use targeted extraction: '
'grep -n \\"pattern\\" $FILE | head -20 '
'or: sed -n \\"/^def target/,/^def /p\\" $FILE | head -50'
)
}))
"
exit 0
fi
exit 0
HOOKEOF
chmod +x .claude/hooks/guard-large-read.sh
echo "guard-large-read.sh created and made executable"
.claude/hooks/validate-bash.sh (dangerous command interceptor)This hook is a second line of defense for Bash commands. While deny rules block known patterns, this script catches variants that pattern matching might miss (e.g., command git push, env GIT_SSH=... git push).
cat > .claude/hooks/validate-bash.sh << 'HOOKEOF'
#!/bin/bash
# validate-bash.sh — PreToolUse hook for Bash commands
# Blocks dangerous shell commands before Claude Code executes them.
# Exit code 2 = BLOCK, exit code 0 = ALLOW
set -euo pipefail
INPUT=$(cat)
COMMAND=$(echo "$INPUT" | python3 -c "
import json, sys
data = json.load(sys.stdin)
print(data.get('tool_input', {}).get('command', ''))
" 2>/dev/null || echo "")
if [ -z "$COMMAND" ]; then
exit 0
fi
# git push (any variant)
if echo "$COMMAND" | grep -qE '(^|\s|;|&&|\|\|)git\s+push(\s|$)'; then
echo '{"decision":"block","reason":"git push blocked. Push manually."}' >&2
exit 2
fi
# git reset --hard
if echo "$COMMAND" | grep -qE 'git\s+reset\s+--hard'; then
echo '{"decision":"block","reason":"git reset --hard blocked. Destructive operation."}' >&2
exit 2
fi
# rm -rf (recursive force delete)
if echo "$COMMAND" | grep -qE '(^|\s|;|&&|\|\|)rm\s+-[a-zA-Z]*r[a-zA-Z]*f|rm\s+-[a-zA-Z]*f[a-zA-Z]*r'; then
echo '{"decision":"block","reason":"rm -rf blocked. Dangerous recursive delete."}' >&2
exit 2
fi
# curl / wget (prevent network exfiltration)
if echo "$COMMAND" | grep -qE '(^|\s|;|&&|\|\|)(curl|wget)\s'; then
echo '{"decision":"block","reason":"curl/wget blocked. No unauthorized network requests."}' >&2
exit 2
fi
# chmod 777 (overly permissive)
if echo "$COMMAND" | grep -qE 'chmod\s+777'; then
echo '{"decision":"block","reason":"chmod 777 blocked. Overly permissive."}' >&2
exit 2
fi
# Writing to system directories
if echo "$COMMAND" | grep -qE '(>|>>)\s*/(etc|usr|var|boot|sys)/'; then
echo '{"decision":"block","reason":"Writing to system directory blocked."}' >&2
exit 2
fi
exit 0
HOOKEOF
chmod +x .claude/hooks/validate-bash.sh
echo "validate-bash.sh created and made executable"
.claude/settings.jsonAdd the hooks section to your project or global settings. Both hooks fire on every tool call — guard-large-read on Read, validate-bash on Bash.
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "$CLAUDE_PROJECT_DIR/.claude/hooks/validate-bash.sh"
}
]
},
{
"matcher": "Read",
"hooks": [
{
"type": "command",
"command": "$CLAUDE_PROJECT_DIR/.claude/hooks/guard-large-read.sh"
}
]
}
]
}
}
Create a Haiku-powered research subagent (~10x cheaper than Sonnet) that explores the codebase in an isolated context and returns compact summaries.
Note : The full subagent specification is in the playbook §8. The command below creates the file if it doesn't already exist.
mkdir -p .claude/agents
# Only create if not already present (don't overwrite customized versions)
if [ ! -f .claude/agents/code-explorer.md ]; then
cat > .claude/agents/code-explorer.md << 'AGENTEOF'
---
name: code-explorer
description: >
Explore codebase structure and find relevant files/patterns.
Use for: understanding how a system works, finding where X is implemented,
mapping dependencies, surveying a module before editing it.
Returns compact summary — keeps main context clean.
model: haiku
effort: low
maxTurns: 10
tools: Read, Bash, Glob, Grep
---
You are a fast, efficient code navigator. Explore, then summarize compactly.
## Exploration rules
- Use `grep -n "pattern" file` instead of reading entire files
- Use `grep -rn "symbol" src/ -l` to find files before reading them
- Stop when you have enough to answer — do not explore exhaustively
- Never read files > 200 lines in full without justification
## Response format (ALWAYS)
Return a JSON block:
```json
{
"relevant_files": ["src/auth/middleware.ts:15-45"],
"key_findings": ["JWT validation happens at line 23", "No refresh token logic found"],
"recommended_approach": "Add refresh endpoint in src/auth/ alongside existing middleware",
"files_read": 3,
"grep_calls": 5
}
AGENTEOF echo "code-explorer.md created" else echo "code-explorer.md already exists — skipped" fi
Run the full verification suite and generate the savings report:
python3 << 'EOF'
import os, glob, json
def tokens(path):
try:
with open(os.path.expanduser(path)) as f:
return len(f.read()) // 4
except:
return 0
def lines(path):
try:
with open(os.path.expanduser(path)) as f:
return sum(1 for _ in f)
except:
return 0
print("=" * 60)
print("CLAUDE CODE TOKEN OPTIMIZATION — FINAL REPORT")
print("=" * 60)
# ── CLAUDE.md ─────────────────────────────────────────────
g_tokens = tokens("~/.claude/CLAUDE.md")
p_tokens = tokens(".claude/CLAUDE.md")
g_lines = lines("~/.claude/CLAUDE.md")
p_lines = lines(".claude/CLAUDE.md")
print(f"\nCLAUDE.md files (loaded every session)")
print(f" Global : {g_lines} lines — ~{g_tokens} tokens")
print(f" Project : {p_lines} lines — ~{p_tokens} tokens")
print(f" Total startup context: ~{g_tokens + p_tokens} tokens")
# ── Skills ────────────────────────────────────────────────
skill_files = glob.glob(".claude/skills/*/SKILL.md")
skill_tokens = sum(tokens(f) for f in skill_files)
print(f"\nSkills (on-demand — zero startup cost)")
for f in skill_files:
t = tokens(f)
print(f" {os.path.basename(os.path.dirname(f))}: ~{t} tokens")
print(f" Total skill content: ~{skill_tokens} tokens (loaded only when invoked)")
# ── Subagents ─────────────────────────────────────────────
agent_files = glob.glob(".claude/agents/*.md")
print(f"\nSubagents configured: {len(agent_files)}")
for f in agent_files:
print(f" {os.path.basename(f)}")
# ── Settings & Security ──────────────────────────────────
settings_path = os.path.expanduser("~/.claude/settings.json")
try:
with open(settings_path) as f:
s = json.load(f)
perms = s.get('permissions', {})
attr = s.get('attribution', {})
print(f"\nSettings")
print(f" model : {s.get('model', 'not set')}")
print(f" effortLevel : {s.get('effortLevel', 'not set')}")
print(f" MAX_THINKING : {s.get('env', {}).get('MAX_THINKING_TOKENS', 'not set')}")
print(f" respectGitignore : {s.get('respectGitignore', 'not set')}")
print(f" attribution : commit='{attr.get('commit', 'not set')}' pr='{attr.get('pr', 'not set')}'")
print(f"\nPermissions")
print(f" deny rules : {len(perms.get('deny', []))}")
for r in perms.get('deny', []):
print(f" ✗ {r}")
print(f" ask rules : {len(perms.get('ask', []))}")
for r in perms.get('ask', []):
print(f" ? {r}")
print(f" allow rules : {len(perms.get('allow', []))}")
for r in perms.get('allow', []):
print(f" ✓ {r}")
except:
print("\nCould not read settings.json")
# ── Hooks ─────────────────────────────────────────────────
hook_files = glob.glob(".claude/hooks/*.sh") + glob.glob(os.path.expanduser("~/.claude/hooks/*.sh"))
print(f"\nHooks installed: {len(hook_files)}")
for f in hook_files:
print(f" {f} — {'executable' if os.access(f, os.X_OK) else 'NOT executable [!]'}")
# ── Git safety check ──────────────────────────────────────
git_blocked = any('git push' in r for r in perms.get('deny', []))
rm_blocked = any('rm -rf' in r for r in perms.get('deny', []))
curl_blocked = any('curl' in r for r in perms.get('deny', []))
commit_ask = any('git commit' in r for r in perms.get('ask', []))
print(f"\nSecurity status")
print(f" git push blocked : {'[OK]' if git_blocked else '[FAIL] NOT PROTECTED'}")
print(f" rm -rf blocked : {'[OK]' if rm_blocked else '[FAIL] NOT PROTECTED'}")
print(f" curl/wget blocked : {'[OK]' if curl_blocked else '[FAIL] NOT PROTECTED'}")
print(f" git commit requires confirmation : {'[OK]' if commit_ask else '[WARN] auto-allowed'}")
print(f" attribution suppressed : {'[OK]' if attr.get('commit') == '' else '[WARN] Claude appears in commits'}")
print(f"\n{'=' * 60}")
print(f"OPTIMIZATION COMPLETE")
print(f"{'=' * 60}")
print(f" Startup context : ~{g_tokens + p_tokens} tokens (target ≤ 800)")
print(f" Skills offloaded : ~{skill_tokens} tokens (zero cost until invoked)")
print(f" Large file hook : active (blocks files > 300 lines)")
print(f" Bash safety hook : active (blocks git push, rm -rf, curl)")
print(f" Thinking cap : MAX_THINKING_TOKENS=8000")
print(f" Cheap exploration : haiku subagent at ~10x lower cost")
print(f" Git safety : deny push, ask commit, attribution suppressed")
EOF
Produce a final savings summary. Cross-reference with the full Token Optimization Table in the playbook §14 for the complete list.
| Optimization lever | Mechanism | Estimated savings |
|---|---|---|
| CLAUDE.md < 200 lines | Removed workflow bloat | 2,000-10,000 tokens/session |
| Skills on-demand | Zero cost at startup | 1,000-5,000 tokens/session |
| Large file hook (>300 lines) | PreToolUse external script | 10,000-50,000 tokens/session |
| Bash safety hook | PreToolUse blocks git push, rm -rf, curl | Prevents destructive operations |
permissions.deny git push | Hard block on destructive git | Prevents accidental pushes |
permissions.ask git commit | Human confirmation required | Controlled git history |
attribution: {commit:"",pr:""} | No Co-Authored-By in commits | Clean git log |
MAX_THINKING_TOKENS=8000 | Cap thinking budget | 30-50% thinking token reduction |
effortLevel: medium | No default deep reasoning | Baseline efficiency |
| Haiku subagent exploration | 10x cheaper model for research | 80-90% on exploration calls |
/btw for quick lookups | Never enters conversation history | 500-2,000 tokens/question |
/clear between tasks | Eliminate stale context | Variable, often largest gain |
Papa Sega WADE — AI Research Engineer Bridging software engineering and AI research — building tools, workflows, and systems that make LLM-assisted development practical at scale.
1000+ skills curated from Anthropic, Vercel, Stripe, and other engineering teams
Agent harness performance optimization with skills, instincts, memory, and security
Design enforcement with memory — keeps your UI consistent across a project
Detects 37 AI writing patterns and rewrites text with human rhythm across 5 voice profiles