

Are you the author? Sign in to claim
ContextLattice is the local-first control plane for long-horizon agent memory and coordination.
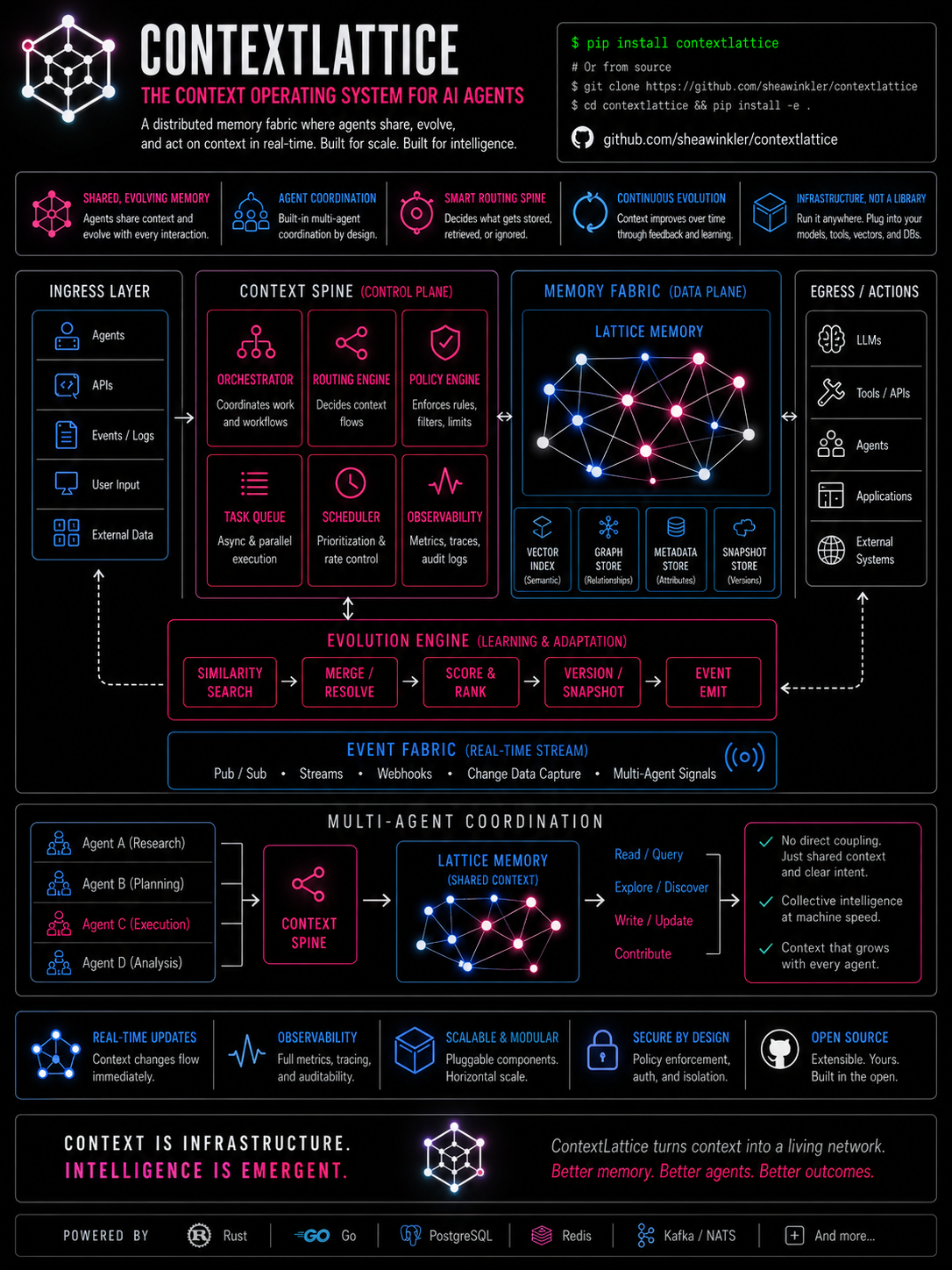
Private-by-default memory and context orchestration for AI agents.

ContextLattice provides a single memory contract for agentic systems:
archive/services/orchestrator_legacy_python for tooling/test compatibility only.v3.4.2 is the public agent runtime contract baseline: universal adapter lifecycle, native agent sessions, objective runtime state, scoped recall, checkpoints, handoffs, completion flow, runtime telemetry, one-command runtime proof, storage-governance hardening, and local session-store diagnostics behind one local contract.
v4 remains the private tuning lane for experiments that still need benchmark, recall, and soak gates before public promotion.
gateway-go.Dockerfile.hf-lite) also run gateway-go (no Python runtime dependency).topic_rollups only.topic_rollups + qdrant; pgvector and memory-bank spike adapters are not started by default.gmake mem-up-lite-advanced.git clone git@github.com:sheawinkler/ContextLattice.git
cd ContextLattice
cp .env.example .env
gmake quickstart
gmake quickstart prompts for runtime profile and then launches the selected stack.
curl -fsS http://127.0.0.1:8075/health | jq
scripts/agent/agent-runtime-proof-pack --pretty
Task inference defaults to ORCH_INFER_PROVIDER=auto. gateway-go detects the host profile and probes local backends before selecting a route.
mlx,vllm-metal,ane_sidecar,llama-cpp,ollama.sglang,vllm,openai-compatible,llama-cpp,lmstudio,ollama.openai-compatible,llama-cpp,lmstudio,ollama.sglang, vllm, vllm-metal, mlx, mtplx (alias for MLX), openai-compatible, lmstudio, llama-cpp, tgi, tensorrt-llm, ane_sidecar, and ollama./v1/inference/runtime-policy returns live provider health plus resource-aware model guidance. If host memory/VRAM is not identifiable, it falls back to generic local advice: start with Q4/IQ4 7B-9B models, benchmark, then scale up.mudler/Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled-APEX-MTP-GGUF for llama.cpp-compatible advanced users. Abliterated variants are private-eval only behind CONTEXTLATTICE_DREAM_ALLOW_PRIVATE_EVAL_MODELS=true (GO_DREAM_ALLOW_UNCENSORED_MODELS=true remains a legacy alias).scripts/inference_mlx_server.sh --model /path/to/mlx/model --template-profile qwen-final-content, then verify with scripts/inference_template_conformance.sh --provider mlx --model /path/to/mlx/model.GO_DREAM_REFLECT_ENABLED=true, GO_DREAM_DEEPEN_ON_WEAK_OUTPUT=true, GO_DREAM_REFLECTION_MIN_SCORE=0.74).CONTEXTLATTICE_SINGLE_ACTIVE_INFER_BACKEND=true).Inspect live routing and benchmark configured backends:
scripts/inference_runtime_policy.sh
scripts/benchmark_inference_backends.sh
scripts/inference_template_conformance.sh --provider mlx --model /path/to/mlx/model
Embedding defaults to the Rust fastembed-rs sidecar. Ollama stays available as an explicit compatibility fallback, not the preferred embedding path.
Useful model runtime knobs:
ORCH_INFER_PROVIDER=auto
ORCH_INFER_PROVIDER_PRIORITY=mlx,vllm-metal,ane_sidecar,sglang,vllm,openai-compatible,llama-cpp,ollama
ORCH_INFER_AUTO_PROBE_ENABLED=true
SGLANG_BASE_URL=http://127.0.0.1:30000
VLLM_BASE_URL=http://127.0.0.1:8000
VLLM_METAL_BASE_URL=http://127.0.0.1:8000
MLX_API_BASE=http://127.0.0.1:18087/v1
LLAMA_CPP_BASE_URL=http://127.0.0.1:8080
Installer and quickstart paths install agent helpers under ~/.contextlattice/bin.
contextlattice_agent_adapter profiles
contextlattice_agent_start --soft --compact
contextlattice_search -h
contextlattice_write -h
contextlattice_checkpoint -h
contextlattice_agent_adapter is the first-class lifecycle helper for bootstrap, context-pack, checkpoint, handoff, event, and completion flows.contextlattice_agent_start runs the lightweight startup guard for agents.contextlattice_checkpoint writes a checkpoint and verifies readback.docs/agent-hooks.md.ContextLattice tracks live agent work as first-class sessions, independent of the runner or model provider.
GET|POST /v1/agents/sessions and GET /v1/agents/sessions/{session_id}.POST /v1/agents/sessions/event or POST /v1/agents/sessions/{session_id}/events.GET /telemetry/agents/runtime.objective_runtime_state.v1 with objective_state, action_executed, evidence, objective_delta, risk_or_blocker, and next_action.scripts/agent/contextlattice-agent-adapter or global contextlattice_agent_adapter as the first-class product path for agent bootstrap, context-pack, checkpoint, handoff, event, and completion flows.scripts/agent/agent-runtime-proof-pack --pretty or global contextlattice_agent_runtime_proof --pretty for a one-command live proof that bootstrap, scoped recall, checkpoint, handoff, completion, status, and runtime telemetry are wired end to end.scripts/agent/contextlattice-session for CLI start/event/complete/fail/status/runtime flows.scripts/agent/contextlattice-session sweep-stale-audits --all-projects --pretty for dry-run-first cleanup of stale objective-runtime audit/preflight sessions; add --confirm only after reviewing matches.scripts/agent/contextlattice-pack, scripts/agent/contextlattice-dream, scripts/agent/writeback, and compaction hooks auto-start or recover a session when CONTEXTLATTICE_SESSION_ID is absent.--session-id or CONTEXTLATTICE_SESSION_ID to force a specific session. Set CONTEXTLATTICE_AUTO_SESSION_DISABLED=1 to disable automatic session creation.Canonical event families include session.started, context_pack.completed, dream.completed, graph.neighbors_returned, graph.edge_touched, decision.made, test.ran, handoff.created, writeback.completed, and session.completed.
https://github.com/sheawinkler/ContextLattice/releases/latest/download/ContextLattice-macOS-universal.dmgbrew tap sheawinkler/contextlattice && brew install --cask contextlatticehttps://github.com/sheawinkler/ContextLattice/releases/latest/download/ContextLattice-windows-x64.msihttps://github.com/sheawinkler/ContextLattice/releases/latest/download/ContextLattice-linux-bootstrap.tar.gz| Profile | CPU | RAM | Storage |
|---|---|---|---|
| Lite core | 2-4 vCPU | 8-12 GB | 25-80 GB |
| Lite advanced | 4-6 vCPU | 12-16 GB | 80-140 GB |
| Full | 6-8 vCPU | 12-20 GB | 100-180 GB |
GET|POST /v1/memory/edges persists explicit typed relationships.POST /v1/memory/edges/backfill audits or applies deterministic retroactive edges and opt-in same-project inferred_related scoring. It is dry-run by default.POST /v1/memory/neighbors returns explicit/inferred edge neighbors merged with semantic/topic neighbors../scripts/agent/memory-edge-backfill
./scripts/agent/memory-edge-backfill --include-inferred --min-confidence 0.90
./scripts/agent/memory-edge-backfill --write
./scripts/agent/memory-edge-inferred-retrofill --all-projects
./scripts/agent/memory-edge-inferred-retrofill --all-projects --profile exploratory
./scripts/agent/memory-edge-inferred-retrofill --all-projects --profile exploratory --write --confirm-retrofill ALL_PROJECTS
./scripts/agent/memory-edge-inferred-retrofill --project hermes-agent-ultra --corpus disk --profile exploratory
https://contextlattice.io/https://contextlattice.io/architecture.htmlhttps://contextlattice.io/local-ai-workspaces.htmlhttps://contextlattice.io/scaling-memory.htmlhttps://contextlattice.io/wiki.htmlhttps://contextlattice.io/installation.htmlhttps://contextlattice.io/integration.htmlhttps://contextlattice.io/troubleshooting.htmlhttps://contextlattice.io/updates.htmldocs/releases/v3.4.2.mddocs/releases/v3.4.1.mdBusiness Source License 1.1 (LICENSE).
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows