

Are you the author? Sign in to claim
Grounded Docs MCP Server: Open-Source Alternative to Context7, Nia, and Ref.Tools
Docs MCP Server solves the problem of AI hallucinations and outdated knowledge by providing a personal, always-current documentation index for your AI coding assistant. It fetches official docs from websites, GitHub, npm, PyPI, and local files, allowing your AI to query the exact version you are using.
The open-source alternative to Context7, Nia, and Ref.Tools.
| Category | Formats |
|---|---|
| Documents | PDF, Word (.docx/.doc), Excel (.xlsx/.xls), PowerPoint (.pptx/.ppt), OpenDocument (.odt/.ods/.odp), RTF, EPUB, FictionBook, Jupyter Notebooks |
| Archives | ZIP, TAR, gzipped TAR (contents are extracted and processed individually) |
| Web | HTML, XHTML |
| Markup | Markdown, MDX, reStructuredText, AsciiDoc, Org Mode, Textile, R Markdown |
| Source Code | TypeScript, JavaScript, Python, Go, Rust, C/C++, Java, Kotlin, Ruby, PHP, Swift, C#, and many more |
| Data | JSON, YAML, TOML, CSV, XML, SQL, GraphQL, Protocol Buffers |
| Config | Dockerfile, Makefile, Terraform/HCL, INI, dotenv, Bazel |
See Supported Formats for the complete reference including MIME types and processing details.
For agents and scripts, the CLI is usually the simplest way to use Grounded Docs.
1. Index documentation (requires Node.js 22+):
npx @arabold/docs-mcp-server@latest scrape react https://react.dev/reference/react
For hash-routed SPA docs sites, enable hash preservation explicitly:
npx @arabold/docs-mcp-server@latest scrape my-spa https://docs.example.com/#/guide --preserve-hashes
2. Query the index:
npx @arabold/docs-mcp-server@latest search react "useEffect cleanup" --output yaml
3. Fetch a single page as Markdown:
npx @arabold/docs-mcp-server@latest fetch-url https://react.dev/reference/react/useEffect
--output json|yaml|toon to pick a structured format.fetch-url keep their text payload on stdout.--quiet to suppress non-error diagnostics or --verbose to enable debug output.The skills/ directory contains Agent Skills that teach AI coding assistants how to use the CLI — covering documentation search, index management, and URL fetching.
If you want a long-running MCP endpoint for Claude, Cline, Copilot, Gemini CLI, or other MCP clients:
1. Start the server:
npx @arabold/docs-mcp-server@latest
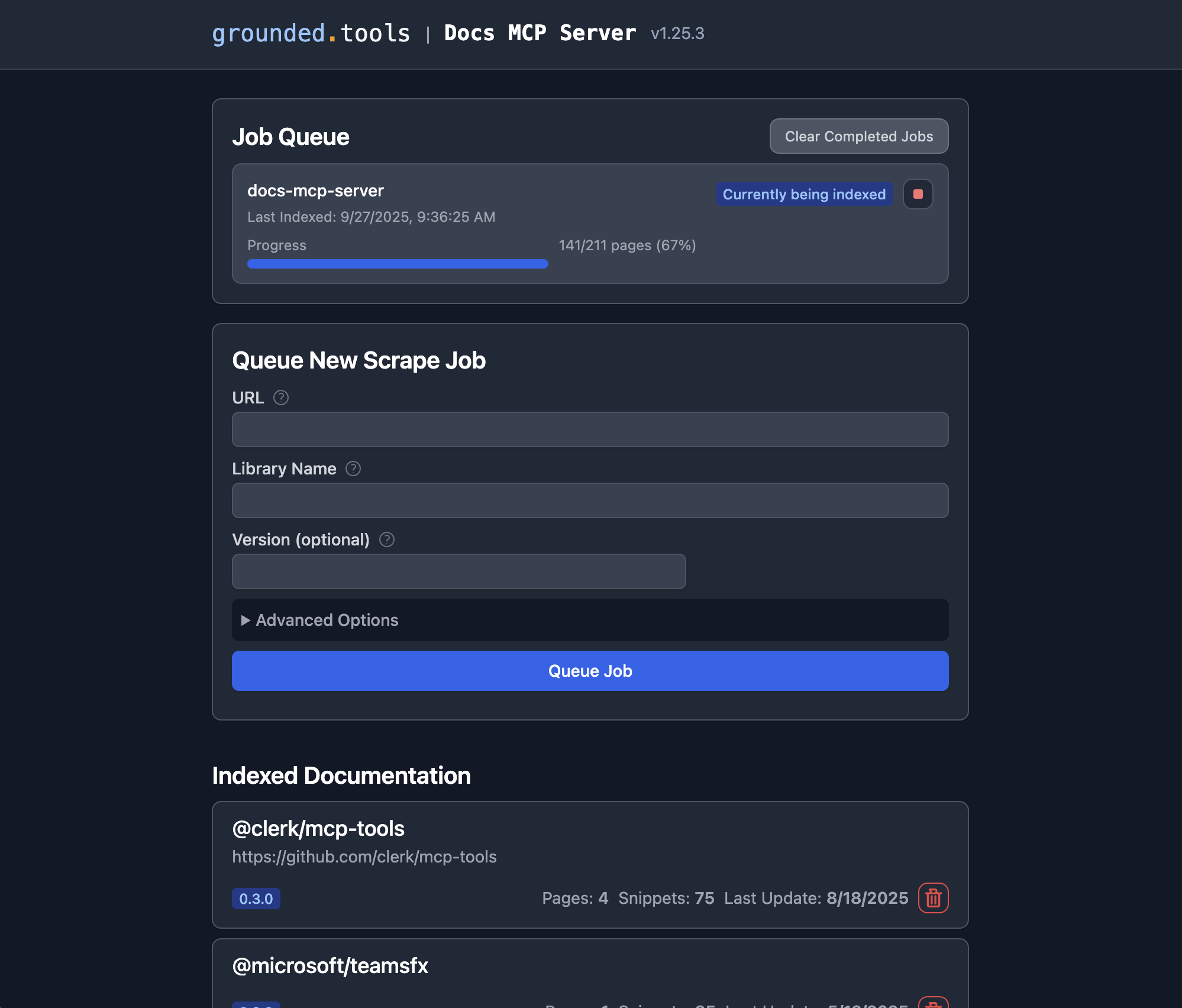
2. Open the Web UI at http://localhost:6280 to add documentation.
3. Connect your AI client by adding this to your MCP settings (e.g., claude_desktop_config.json):
{
"mcpServers": {
"docs-mcp-server": {
"type": "sse",
"url": "http://localhost:6280/sse"
}
}
}
See Connecting Clients for VS Code (Cline, Roo) and other setup options.
scrape_docs also accepts preserveHashes: true for documentation sites that use hash-based client-side routing.
Use it only for hash-routed SPAs; normal sites typically use hash fragments for in-page anchors.
docker run --rm \
-v docs-mcp-data:/data \
-v docs-mcp-config:/config \
-p 6280:6280 \
ghcr.io/arabold/docs-mcp-server:latest \
--protocol http --host 0.0.0.0 --port 6280
Using an embedding model is optional but dramatically improves search quality by enabling semantic vector search.
Example: Enable OpenAI Embeddings
OPENAI_API_KEY="sk-proj-..." npx @arabold/docs-mcp-server@latest
See Embedding Models for configuring Ollama, Gemini, Azure, and others.
--preserve-hashes, MCP preserveHashes, or the Web UI "Preserve Hash Routes" checkbox only for docs sites that route with URLs like #/guide.scrapeMode=fetch, the scraper automatically upgrades the job to Playwright because plain fetch cannot evaluate client-side hash routes.preserveHashes setting by default, and CLI/Web refresh entrypoints can override it explicitly.llms.txt at the documentation subpath and site root before normal crawling. When found, the curated links become additional crawl seeds, and pages discovered this way prefer .md URL variants such as /guide/index.html.md or /page.html.md before falling back to the original page.Accept: text/markdown, text/html;q=0.9, */*;q=0.8 by default. Servers that support Markdown content negotiation, including Cloudflare Markdown for Agents, can return Markdown directly so the scraper bypasses HTML-to-Markdown conversion for cleaner output.Accept headers are preserved when provided.We welcome contributions! Please see CONTRIBUTING.md for development guidelines and setup instructions.
This project is licensed under the MIT License. See LICENSE for details.
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows