

Are you the author? Sign in to claim
Python, LlamaIndex, LangChain, Docker Compose: 15 Property Graph, 4 RDF , 10 Vector, OpenSearch, Elasticsearch, Alfresco
New 5/6/26: 15 property graph databases total: 8 supported on both LlamaIndex and LangChain, 1 LI-only (Google Cloud Spanner Graph), 6 LC-only (ArangoDB, Apache AGE, Azure Cosmos DB for Gremlin, Apache HugeGraph, SurrealDB, TigerGraph). AWS Neptune RDF/SPARQL added. All 10 vector databases, all 3 search engines, and all LLM/embedding providers work with both LlamaIndex and LangChain. Every pipeline stage (chunking, KG extraction, graph write, vector write, search write, and retrieval fusion) can be configured independently. (Data source reading is LlamaIndex only; RDF stores use framework-independent adapters with LangChain Text-to-SPARQL retrieval.)
New: Flexible GraphRAG now supports RDF-based ontologies for both property graph databases and RDF triple store databases (Graphwise Ontotext GraphDB, Fuseki, and Oxigraph). Document ingestion with KG extraction, auto incremental data source change detection, and UI search (hybrid search, AI query, and AI chat) are all supported with both database types.
New: Flexible GraphRAG supports automatic incremental updates (Optional) from most data sources, keeping your Vector, Search and Graph databases synchronized in real-time or near real-time.
New: KG Spaces Integration of Flexible GraphRAG in Alfresco ACA Client




![]()
Flexible GraphRAG is an open source AI context platform supporting a document processing pipeline (Docling or LlamaParse), knowledge graph auto-building, ontologies, schemas, many LLM providers, GraphRAG and RAG, hybrid semantic search (fulltext, vector, property graph, RDF/SPARQL), AI query, and AI chat. The backend is Python with LlamaIndex and LangChain as peer frameworks. LlamaIndex is the default for each pipeline stage; LangChain can be selected per stage in environment configuration. The API is a REST FastAPI service. Angular, React, and Vue TypeScript frontends and an MCP server are included. The stack supports 13 data sources (9 with incremental auto-sync), 15 property graph databases, 4 RDF triple stores (Apache Jena Fuseki, Ontotext GraphDB, Oxigraph, Amazon Neptune RDF), 10 vector databases, OpenSearch / Elasticsearch / BM25 search, and Alfresco. Services and dashboards can be enabled with the provided Docker Compose layout.
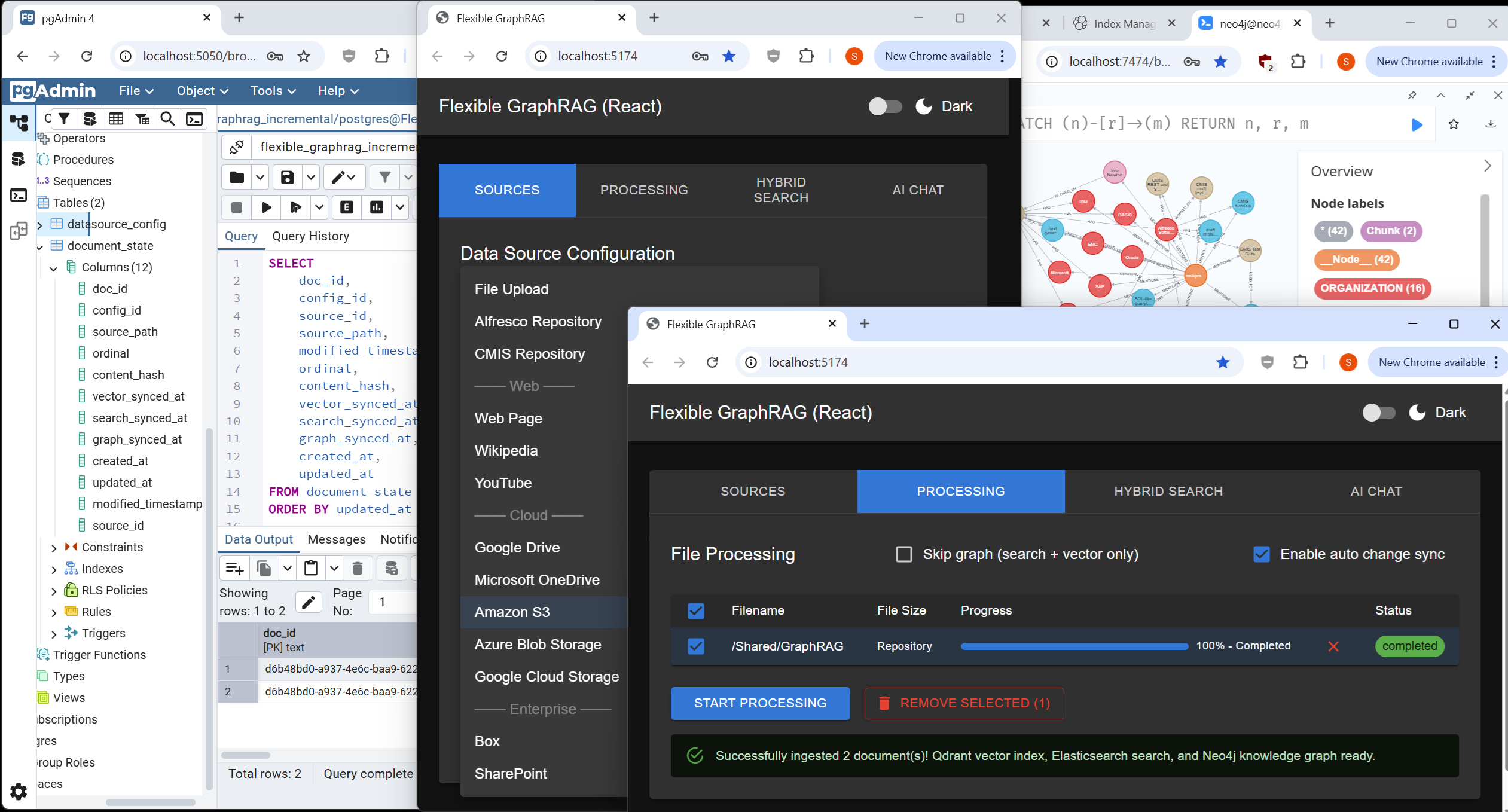
Flexible GraphRAG data sources, processing tab, auto-sync document states in Postgres, Neo4j
Version 0.6.0 broadens framework and database choice: LangChain is a full peer to LlamaIndex (per-stage env pickers for chunking, vector, search, property graph, KG extraction, fusion). 15 property graph backends: 8 on both frameworks, Google Cloud Spanner (LlamaIndex-only), 6 LangChain-only (ArangoDB, Apache AGE, Azure Cosmos DB for Gremlin, HugeGraph, SurrealDB, TigerGraph). RDF includes Apache Jena Fuseki, Ontotext GraphDB, Oxigraph, and Amazon Neptune RDF. Incremental delete, LangChain adapters, and cleanup paths were extended across stores (see CHANGELOG.md).
openai_like), OpenRouter, LiteLLM proxy, and vLLM — configurable via LLM_PROVIDER; see Supported LLM ProvidersEMBEDDING_KIND=openai_like), and LiteLLM — see LLM Configuration| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
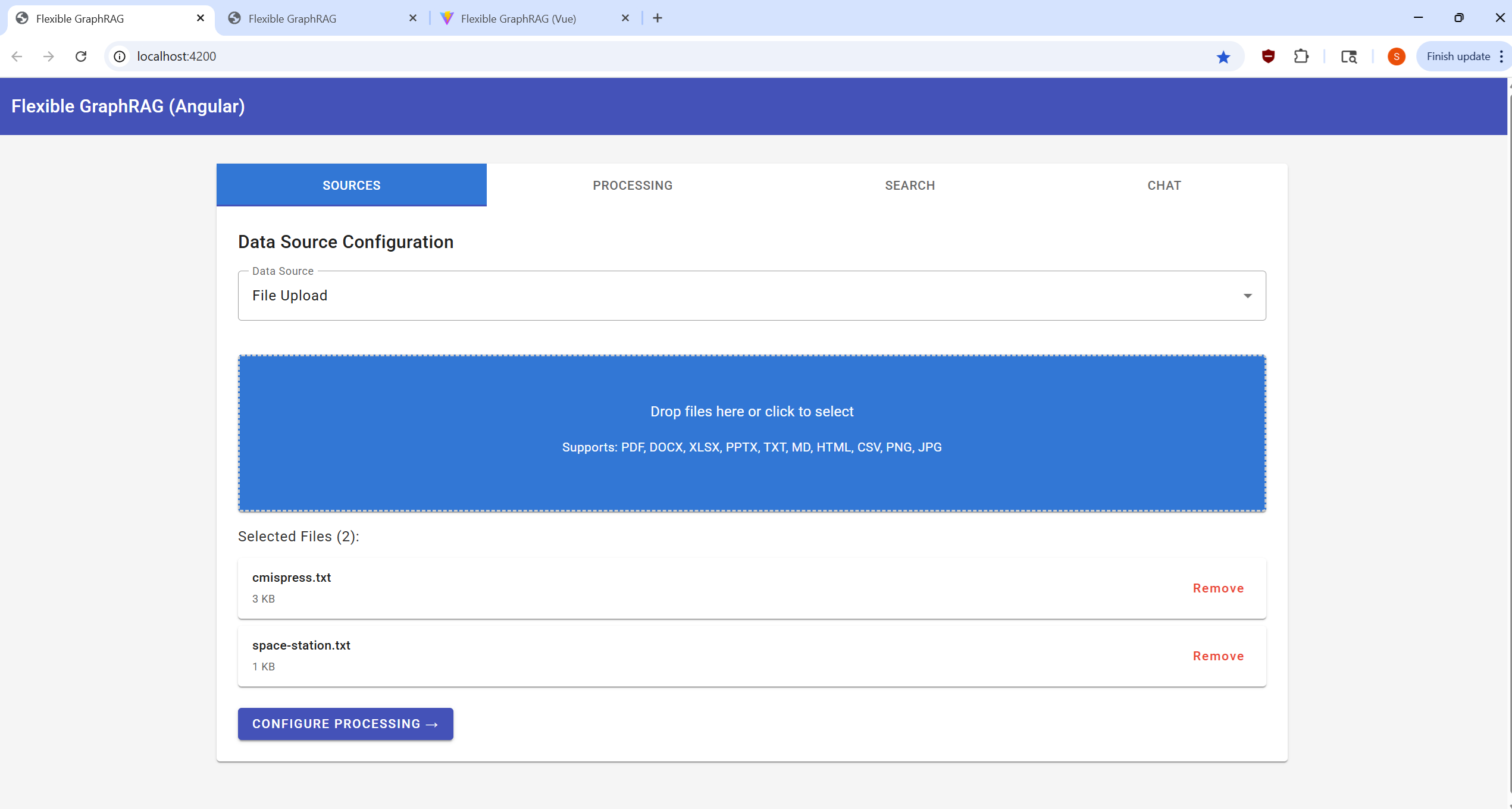 | 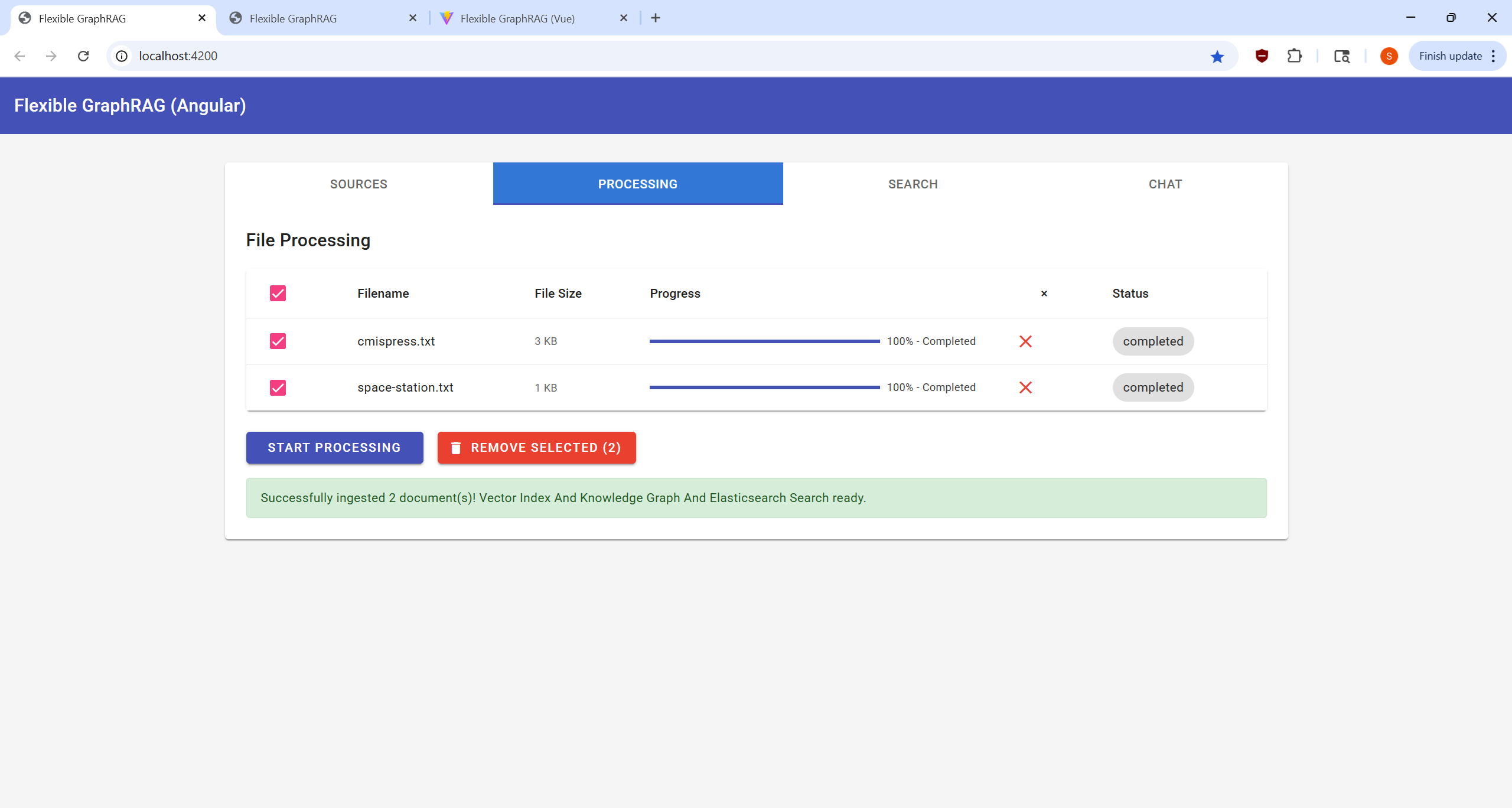 | 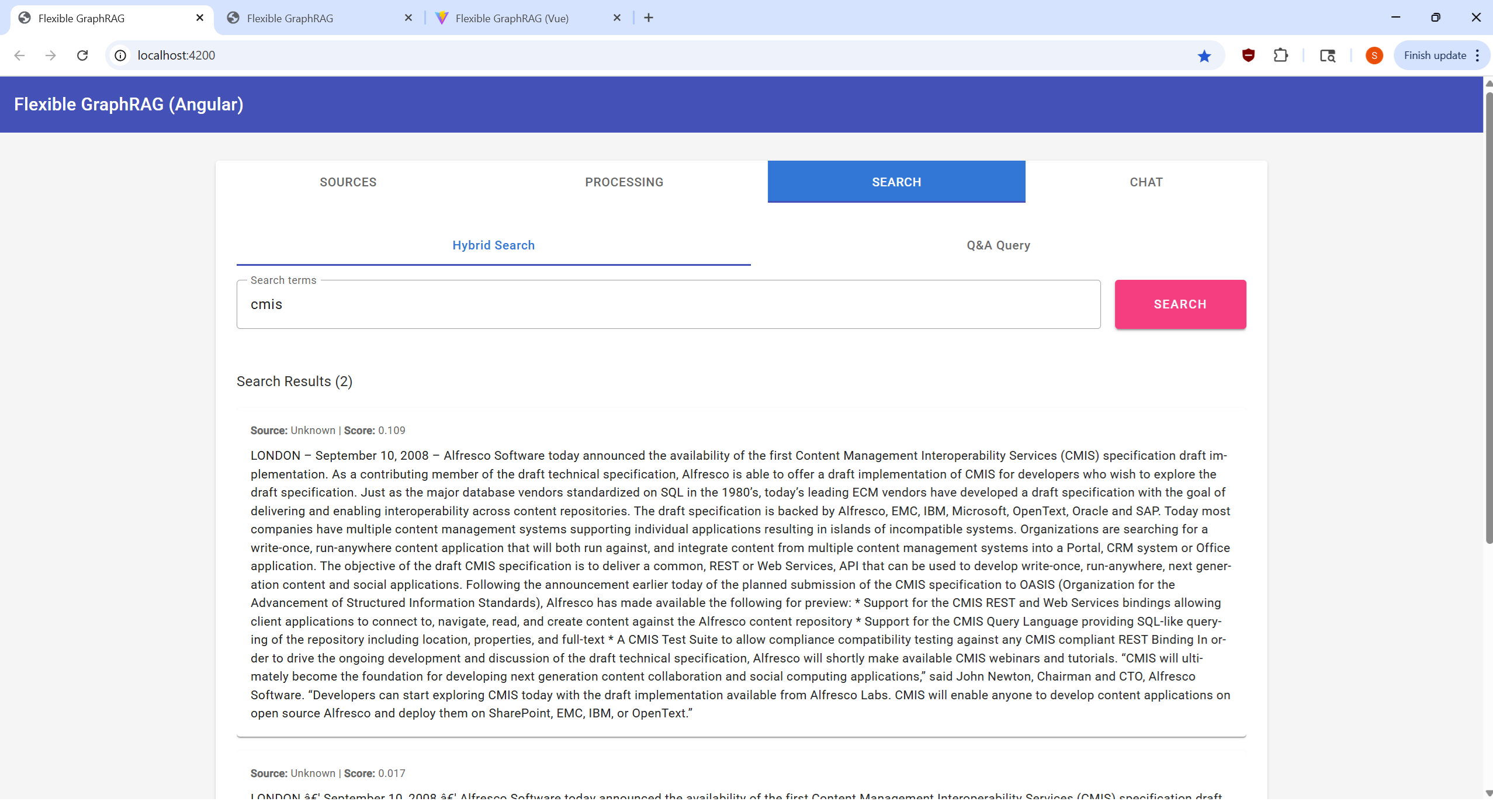 | 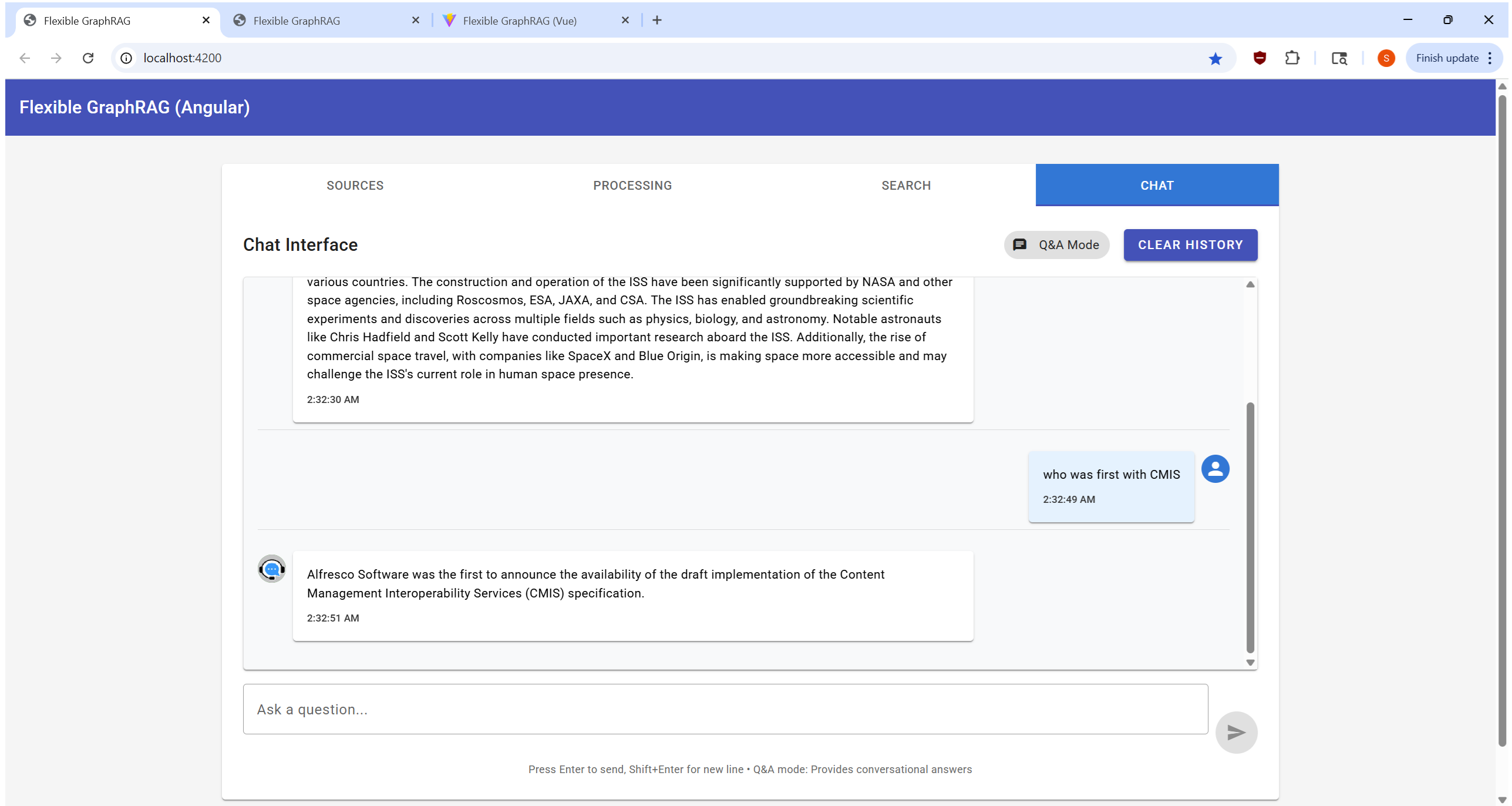 |
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
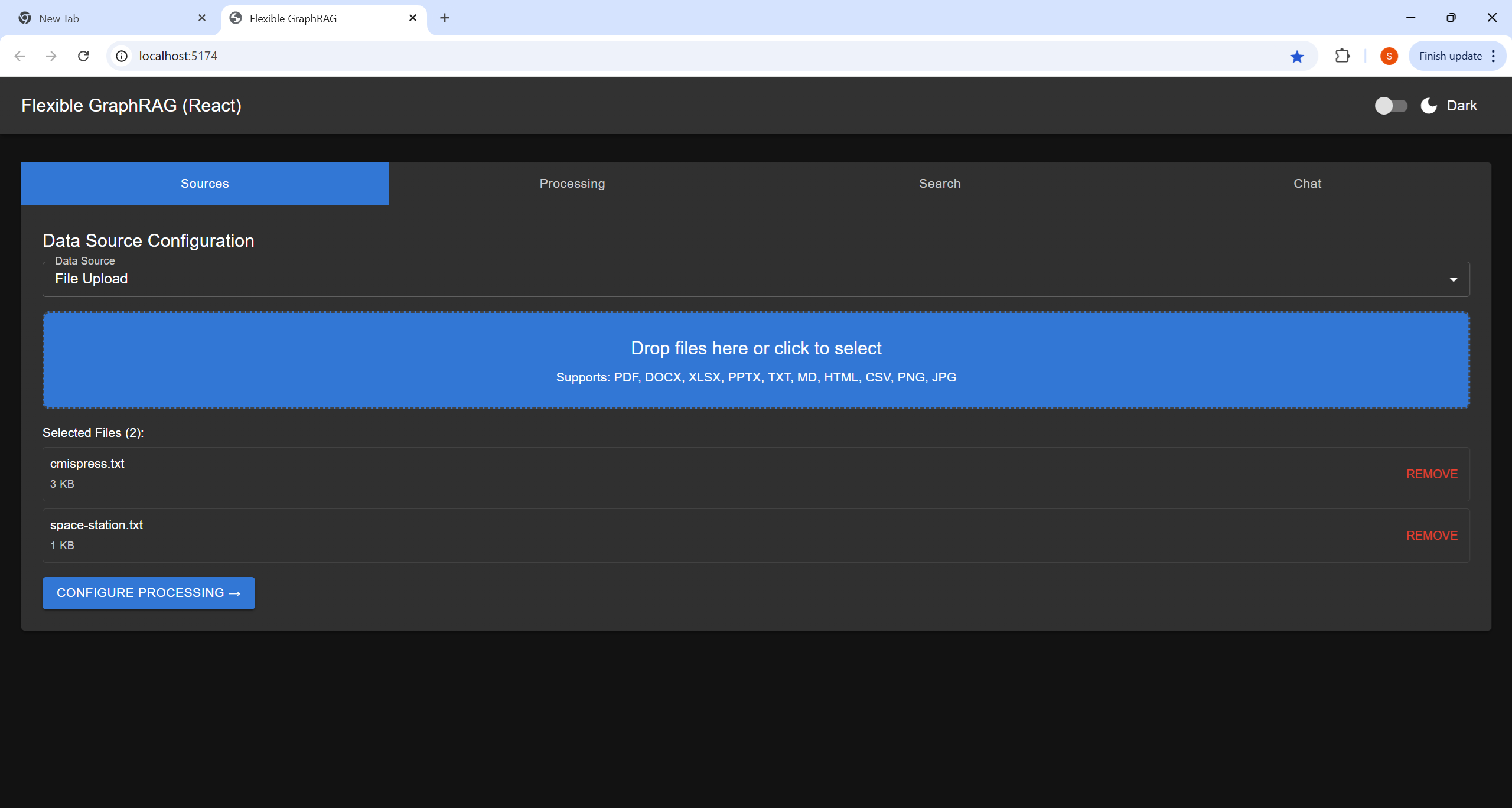 | 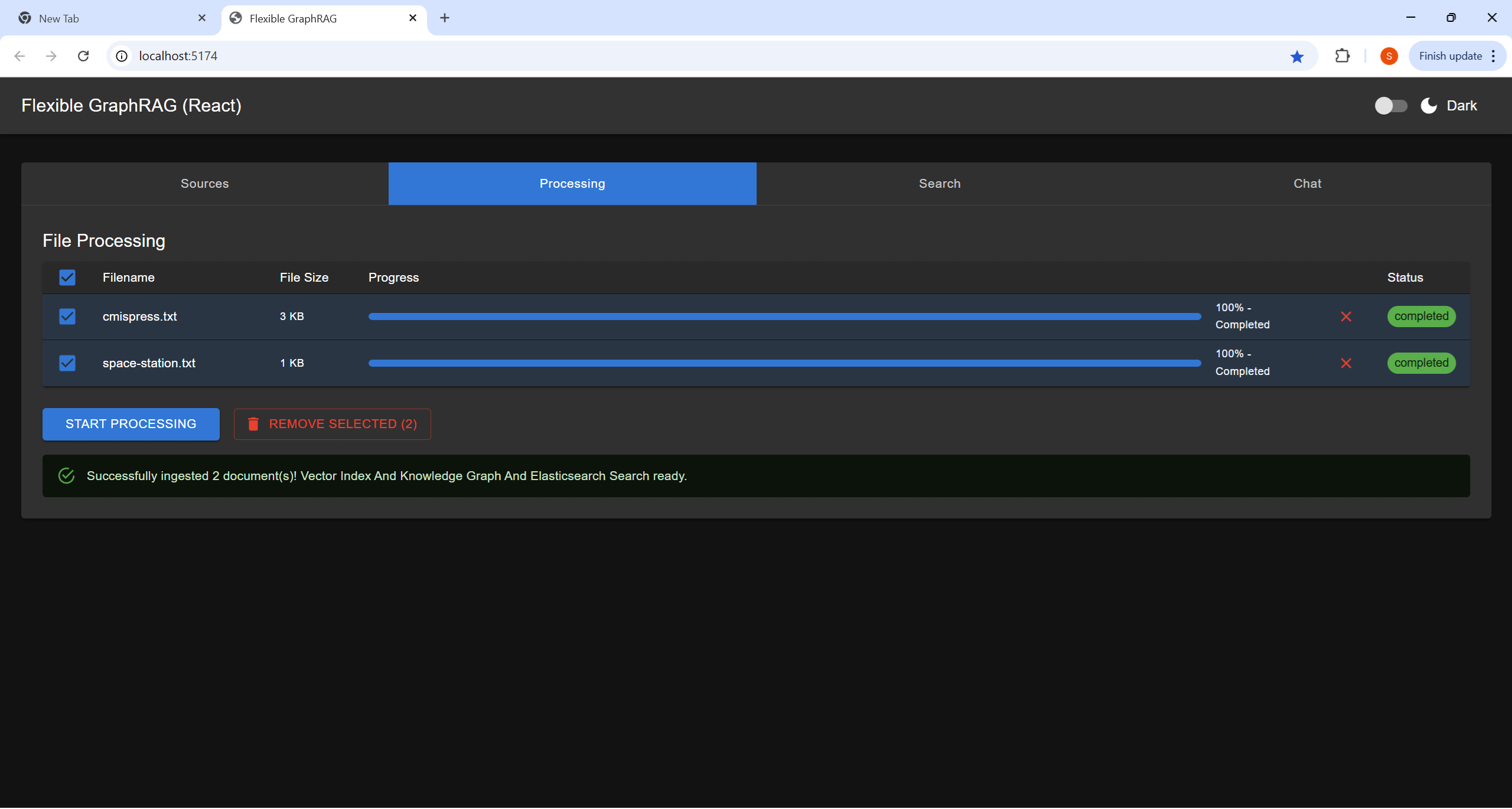 | 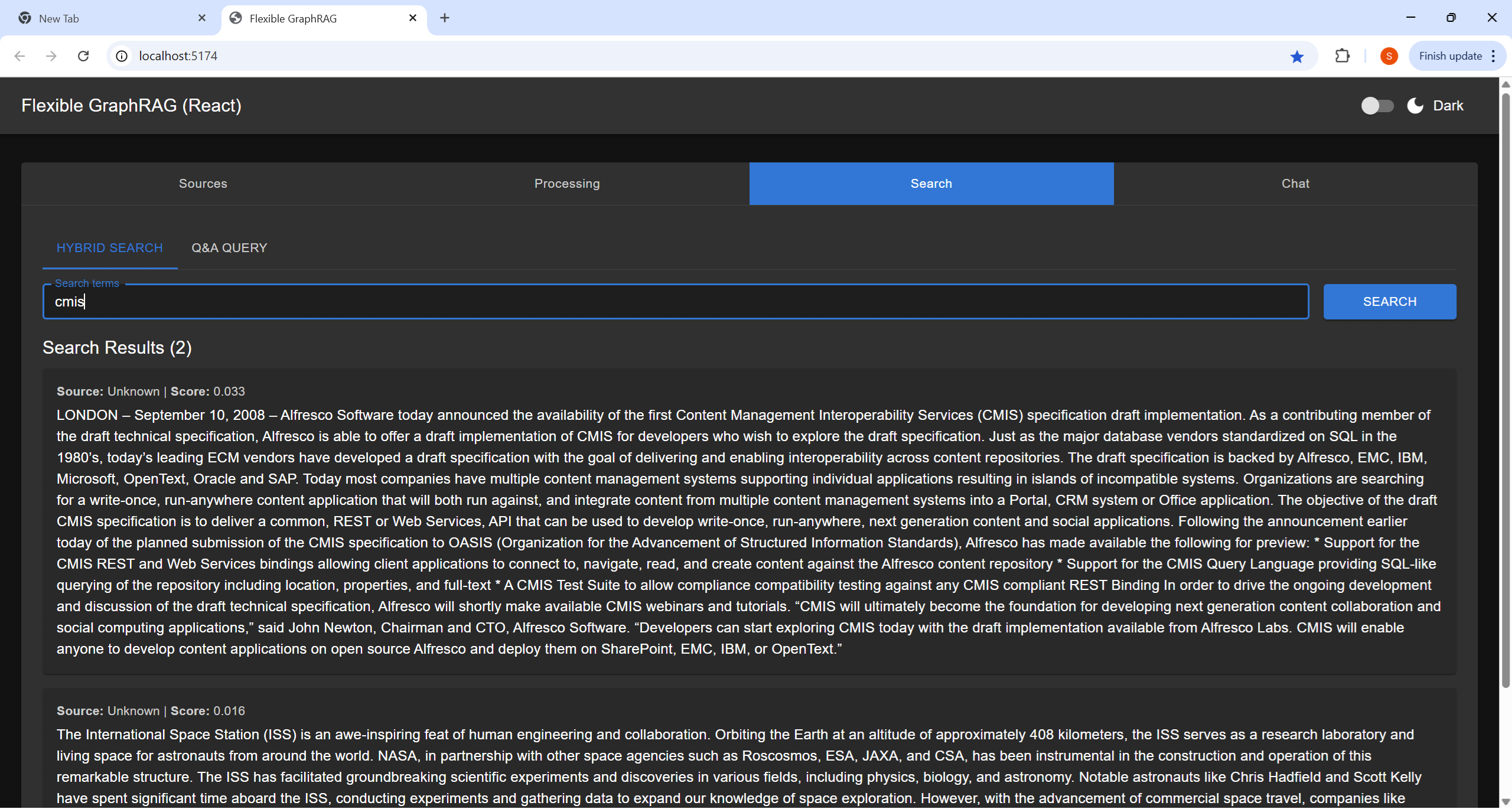 |  |
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
 |  |  | 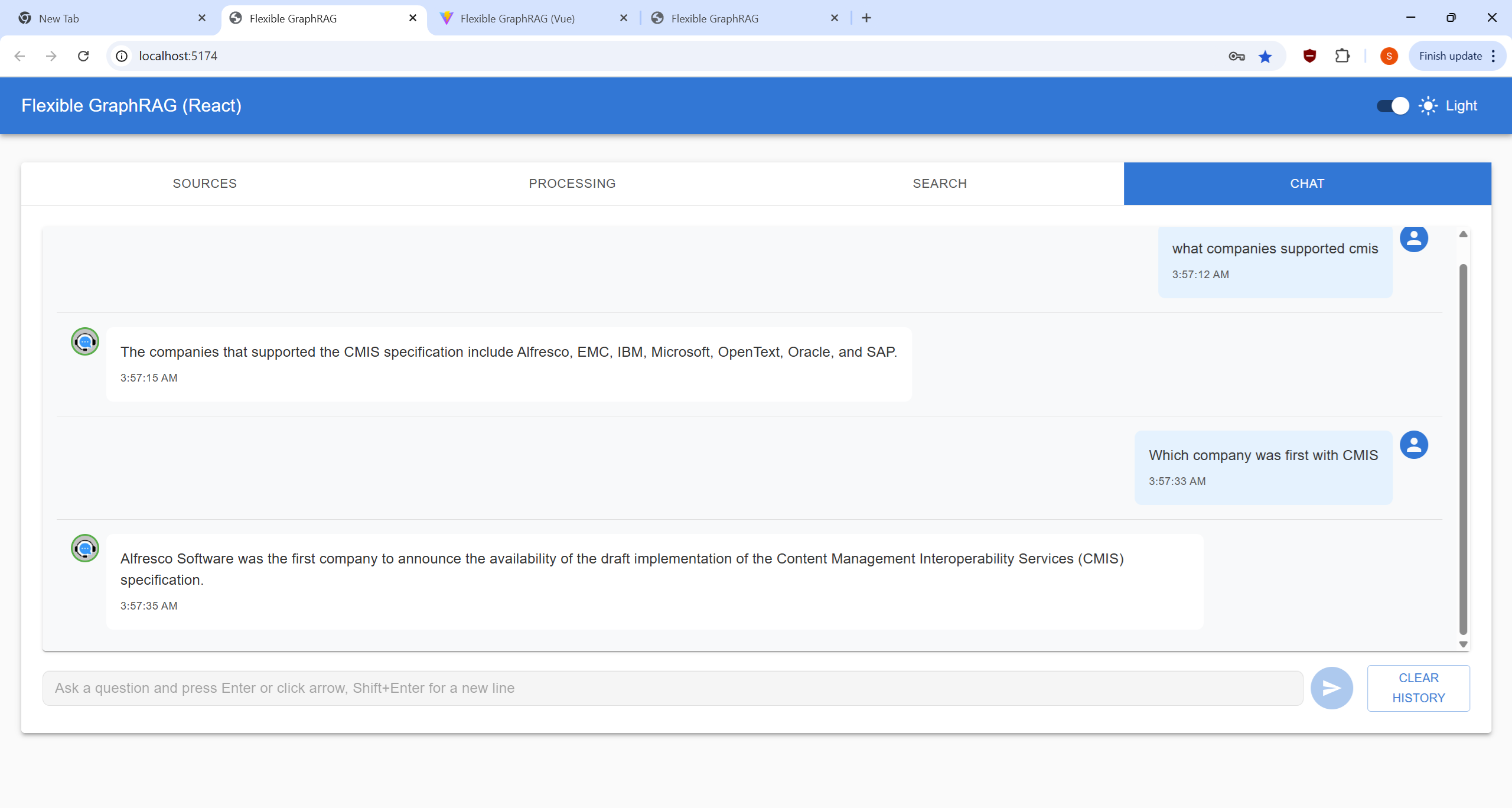 |
| Sources Tab | Processing Tab | Search Tab | Chat Tab |
|---|---|---|---|
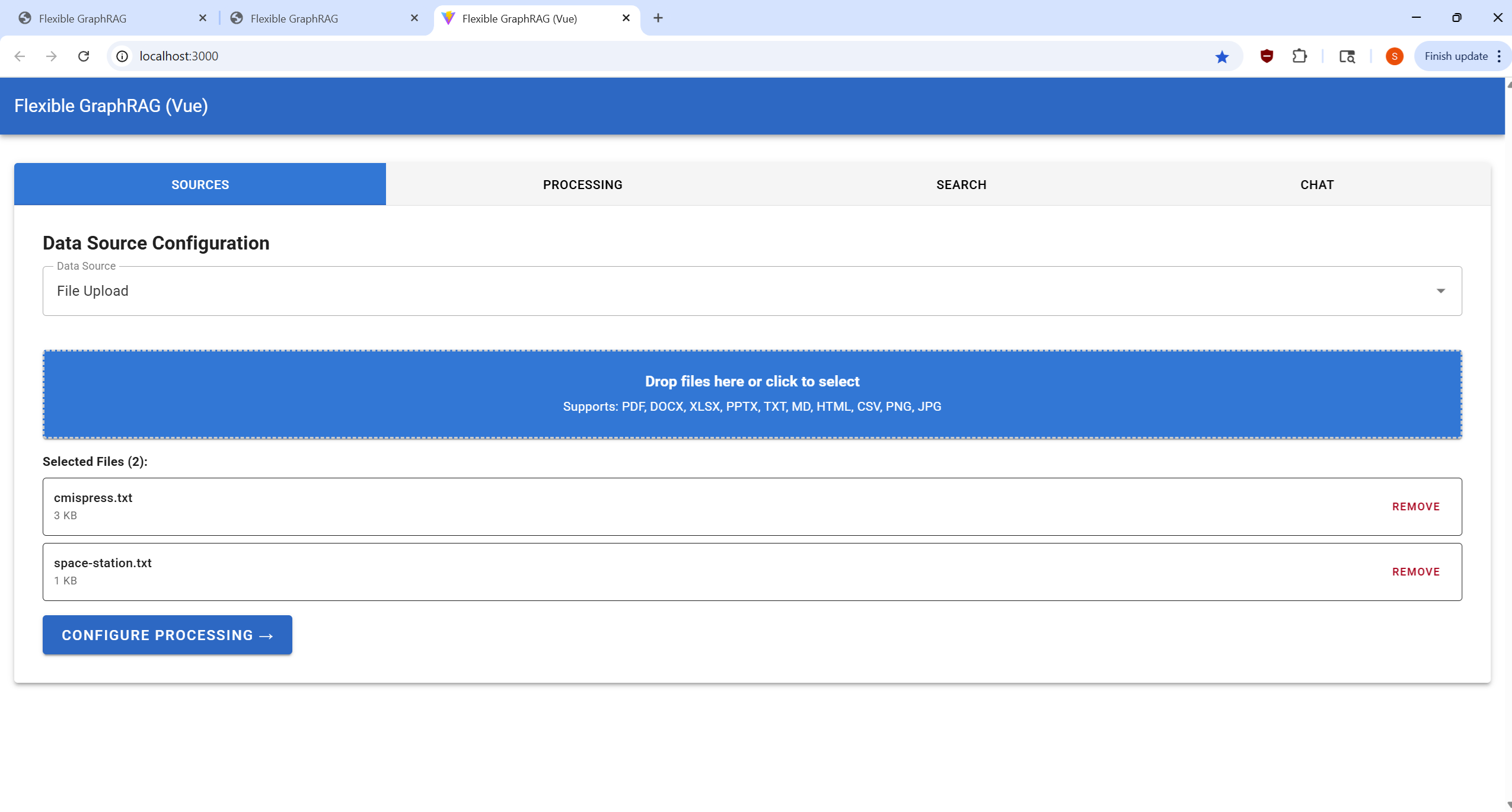 | 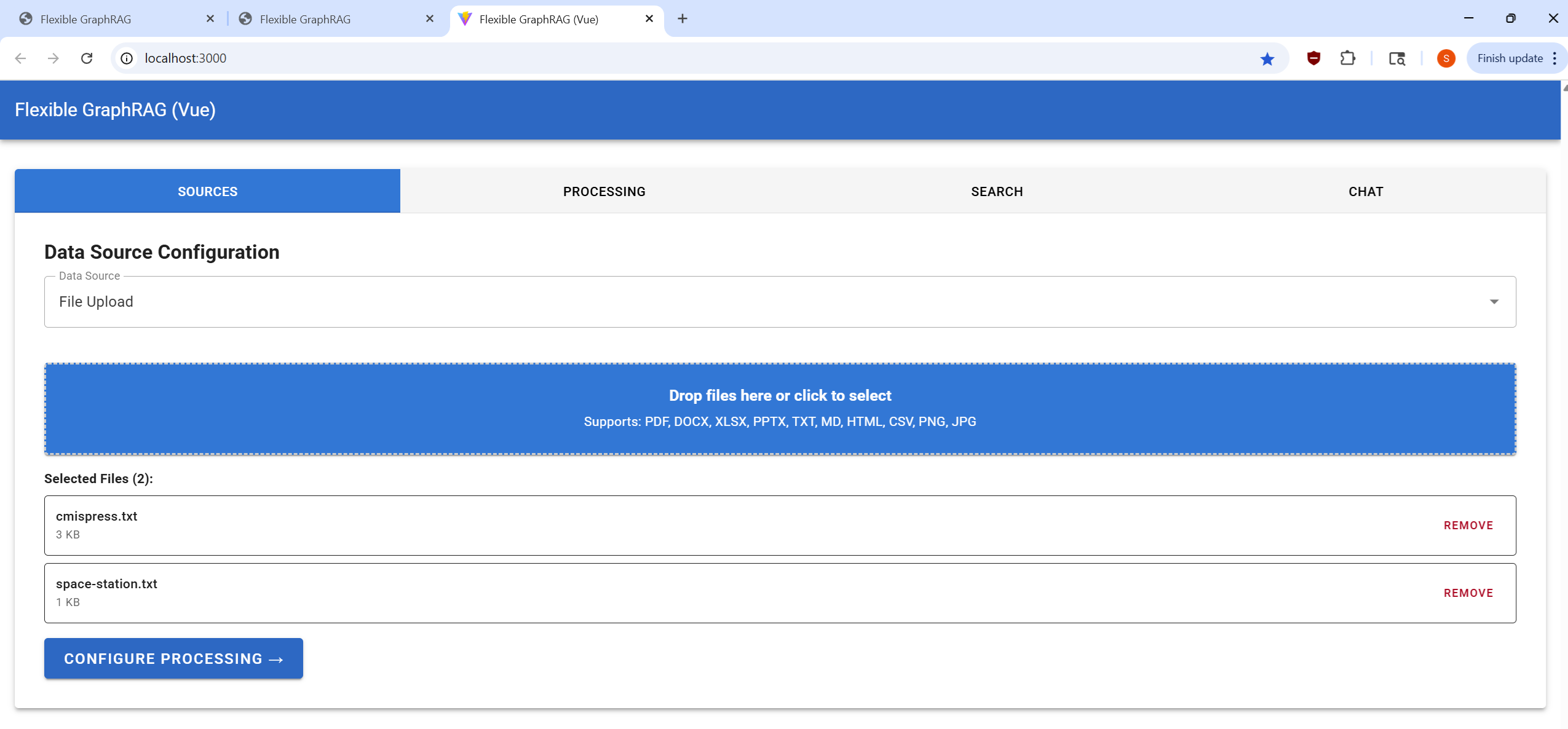 | 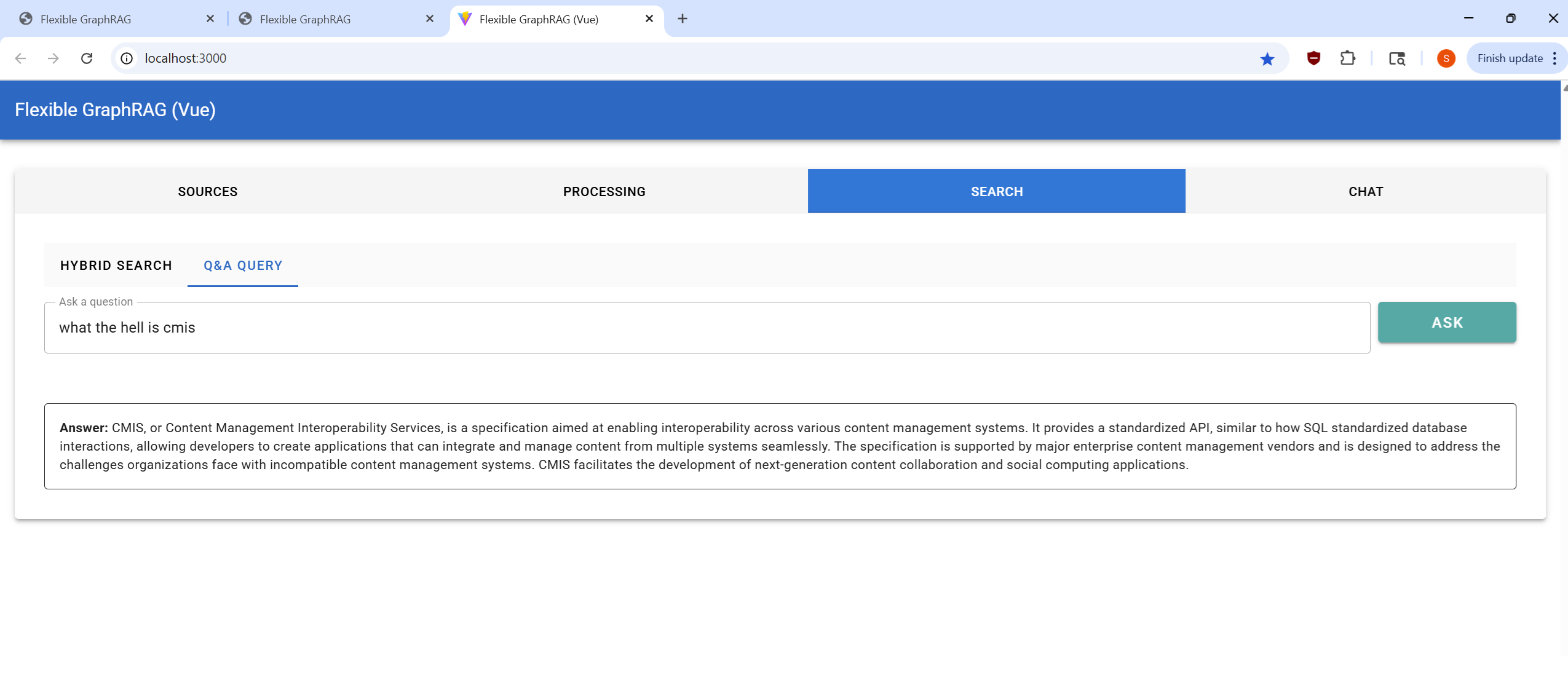 | 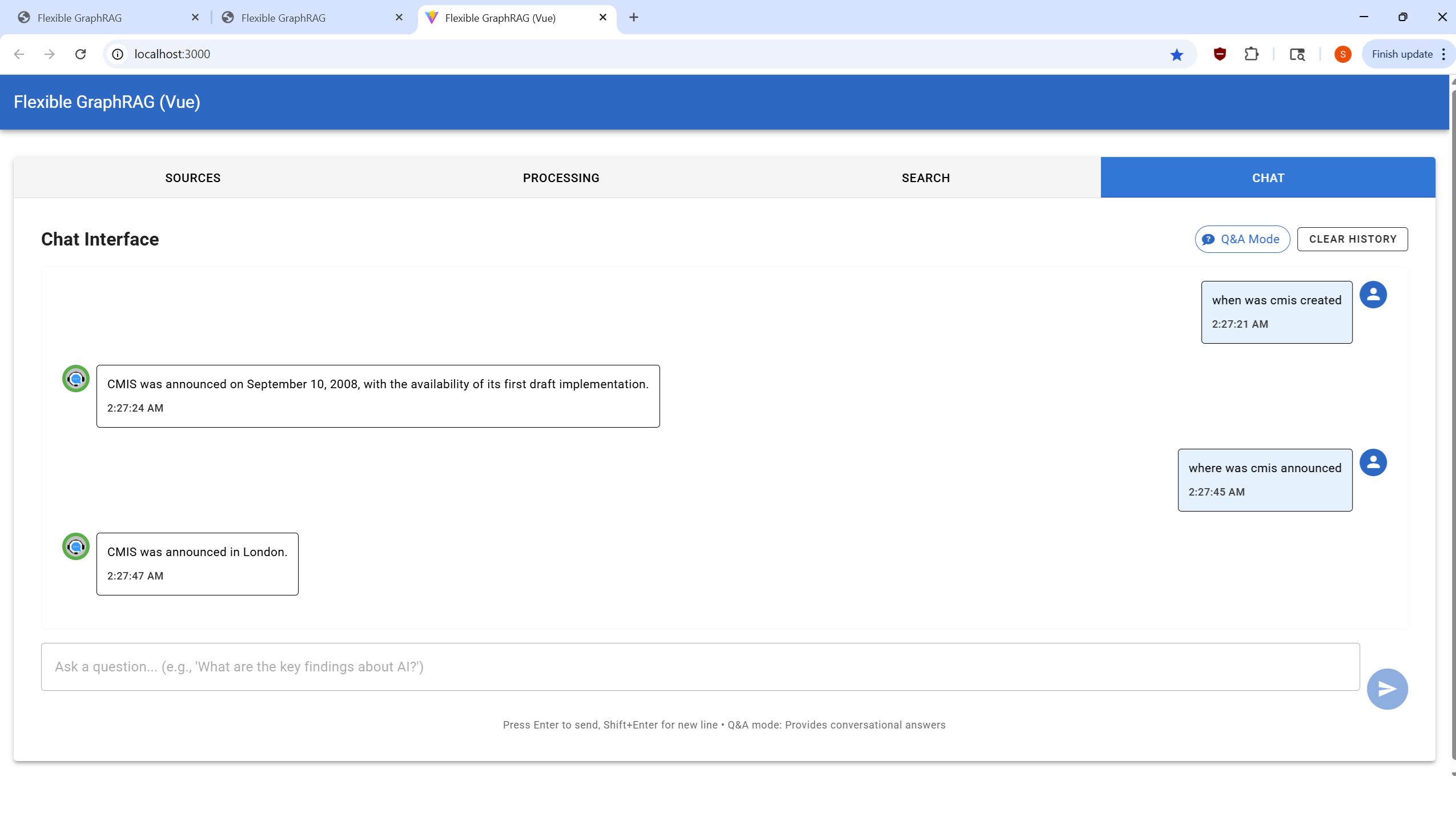 |
/flexible-graphrag)/flexible-graphrag-mcp)ingest_documents() support all 13 data sources with source-specific configs: filesystem, repositories (Alfresco, SharePoint, Box, CMIS), cloud storage, web; skip_graph flag for all data sources; paths parameter for filesystem/Alfresco/CMIS; Alfresco also supports nodeDetails list (multi-select for KG Spaces)search_documents(), query_documents(), ingest_text(), system diagnostics, and health checks/flexible-graphrag-ui)/docker)docker/includes/ladybug-explorer.yaml).Flexible GraphRAG supports 13 different data sources for ingesting documents into your knowledge base:
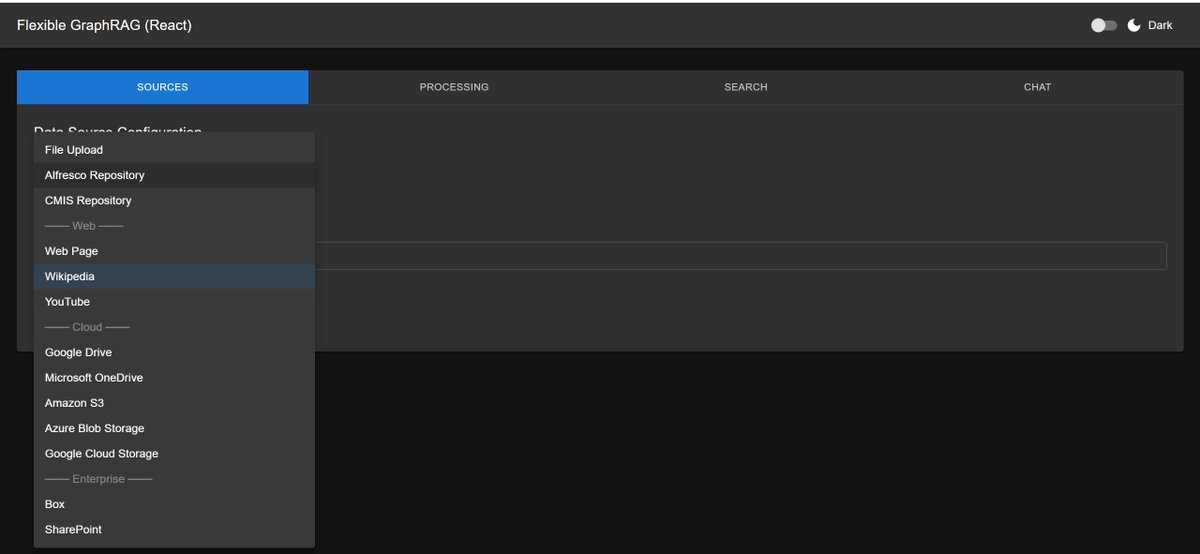
Each data source includes:
NEW! Flexible GraphRAG supports automatic incremental updates (Optional) from most data sources, keeping your Vector, Search and Graph databases synchronized in real-time or near real-time:
| Data Source | Auto-Sync Support | Detection Method | Status | Notes |
|---|---|---|---|---|
| Alfresco | ✅ Real-time | Community ActiveMQ | Ready | Enterprise Event Gateway planned |
| Amazon S3 | ✅ Real-time | SQS event notifications | Ready | |
| Azure Blob Storage | ✅ Real-time | Change feed | Ready | |
| Google Cloud Storage | ✅ Real-time | Pub/Sub notifications | Ready | |
| Google Drive | ✅ Near real-time | Changes API (polling) | Ready | |
| OneDrive | ✅ Near real-time | Polling | Ready | Delta query support planned |
| SharePoint | ✅ Near real-time | Polling | Ready | Delta query support planned |
| Box | ✅ Near real-time | Events API (polling) | Ready | |
| Local Filesystem | ✅ Real-time | OS events (watchdog) | Ready | REST API and MCP Server only |
| File Upload UI, CMIS, Web Pages, Wikipedia, YouTube | ➖ Not supported | - | - | No support for incremental updates |
Features:
Setup Requirements:
Enable incremental updates in your .env file:
ENABLE_INCREMENTAL_UPDATES=true
# PostgreSQL database for state management
# By default, uses the pgvector database from docker-compose.yaml
POSTGRES_INCREMENTAL_URL=postgresql://postgres:password@localhost:5433/postgres
Note: The incremental updates system uses PostgreSQL to track document state. The docker-compose.yaml includes a pgvector container that can be used both as a vector database option and for incremental updates state management. The database connection creates the necessary tables automatically on first use.
Usage:
PostgreSQL for State Management:
The docker/includes/postgres-pgvector.yaml sets up two databases automatically on first start: flexible_graphrag (for optional pgvector vector storage) and flexible_graphrag_incremental (for incremental update state management, with its schema created automatically). pgAdmin is also configured at http://localhost:5050 with both databases pre-registered — just enter the master password admin when prompted, then use password for the server connection and save it. See docs/DATABASES/POSTGRES-SETUP.md for details.
Documentation:
docs/DATA-SOURCES/INCREMENTAL-UPDATE-AUTO-SYNC/README.mddocs/DATA-SOURCES/INCREMENTAL-UPDATE-AUTO-SYNC/QUICKSTART.mddocs/DATA-SOURCES/INCREMENTAL-UPDATE-AUTO-SYNC/SETUP-GUIDE.mddocs/DATA-SOURCES/INCREMENTAL-UPDATE-AUTO-SYNC/API-REFERENCE.mddocs/DATABASES/POSTGRES-SETUP.mdScripts:
scripts/incremental/sync-now.sh|.ps1|.bat - Trigger immediate synchronizationscripts/incremental/set-refresh-interval.sh|.ps1|.bat - Configure polling intervalscripts/incremental/TIMING-CONFIGURATION.md - Timing configuration detailsscripts/incremental/README.md - Script usage documentationAll data sources support two document parser options:
Docling (Default):
DOCLING_OCR=true + DOCLING_OCR_ENGINE=auto|rapidocr|easyocr|tesseract_cli|tesserocr|ocrmacDOCUMENT_PARSER=doclingDOCLING_DEVICE=auto|cpu|cuda|mps — control GPU vs CPU processingSAVE_PARSING_OUTPUT=true — save intermediate parsing results for inspection (works for both parsers)PARSER_FORMAT_FOR_EXTRACTION=auto|markdown|plaintext — control format used for knowledge graph extractionLlamaParse:
parse_page_without_llm - 1 credit/pageparse_page_with_llm - 3 credits/page (default)parse_page_with_agent - 10-90 credits/pageDOCUMENT_PARSER=llamaparse + LLAMAPARSE_API_KEYSAVE_PARSING_OUTPUT=true - Save parsed output and metadata for inspectionPARSER_FORMAT_FOR_EXTRACTION=auto|markdown|plaintext - Control format used for knowledge graph extraction.pdf
.docx, .xlsx, .pptx and legacy formats (.doc, .xls, .ppt)
.html, .htm, .xhtml
.csv, .tsv, .json, .xml
.md, .markdown, .asciidoc, .adoc, .rtf, .txt, .epub
.png, .jpg, .jpeg, .gif, .bmp, .webp, .tiff, .tif
.wav, .mp3, .mp4, .m4a
PARSER_FORMAT_FOR_EXTRACTIONFlexible GraphRAG uses three types of databases for its hybrid search capabilities. Each can be configured independently via environment variables.
Set SEARCH_DB to select the store and SEARCH_BACKEND=llamaindex or langchain for the framework.
BM25 (Built-in): Local in-memory BM25 full-text search with TF-IDF ranking
SEARCH_DB=bm25
BM25_SEARCH_DB_CONFIG={"persist_dir": "./bm25_index"}
Elasticsearch: Enterprise search engine with advanced analyzers, faceted search, and real-time analytics
SEARCH_DB=elasticsearch
ELASTICSEARCH_SEARCH_DB_CONFIG={"hosts": ["http://localhost:9200"], "index_name": "hybrid_search"}
OpenSearch: AWS-led open-source fork with native hybrid scoring (vector + BM25) and k-NN algorithms
SEARCH_DB=opensearch
OPENSEARCH_SEARCH_DB_CONFIG={"hosts": ["http://localhost:9201"], "index_name": "hybrid_search"}
None: Disable full-text search (vector search only)
SEARCH_DB=none
Set VECTOR_DB to select the store and VECTOR_BACKEND=llamaindex or langchain for the framework.
When switching embedding models, delete existing vector indexes — dimensions differ by provider. See docs/DATABASES/VECTOR-DATABASES/VECTOR-DIMENSIONS.md for cleanup instructions.
Neo4j: Can be used as vector database with separate vector configuration
VECTOR_DB=neo4j
NEO4J_VECTOR_DB_CONFIG={"uri": "bolt://localhost:7687", "username": "neo4j", "password": "your_password", "index_name": "hybrid_search_vector"}
Qdrant: Dedicated vector database with advanced filtering
VECTOR_DB=qdrant
QDRANT_VECTOR_DB_CONFIG={"host": "localhost", "port": 6333, "collection_name": "hybrid_search"}
Elasticsearch: Can be used as vector database with separate vector configuration
VECTOR_DB=elasticsearch
ELASTICSEARCH_VECTOR_DB_CONFIG={"hosts": ["http://localhost:9200"], "index_name": "hybrid_search_vectors"}
OpenSearch: Can be used as vector database with separate vector configuration
VECTOR_DB=opensearch
OPENSEARCH_VECTOR_DB_CONFIG={"hosts": ["http://localhost:9201"], "index_name": "hybrid_search_vectors"}
Chroma: Open-source vector database with dual deployment modes
VECTOR_DB=chroma
CHROMA_VECTOR_DB_CONFIG={"persist_directory": "./chroma_db", "collection_name": "hybrid_search"}
VECTOR_DB=chroma
CHROMA_VECTOR_DB_CONFIG={"host": "localhost", "port": 8001, "collection_name": "hybrid_search"}
Milvus: Cloud-native, scalable vector database for similarity search
VECTOR_DB=milvus
MILVUS_VECTOR_DB_CONFIG={"host": "localhost", "port": 19530, "collection_name": "hybrid_search"}
Weaviate: Vector search engine with semantic capabilities and data enrichment
VECTOR_DB=weaviate
WEAVIATE_VECTOR_DB_CONFIG={"url": "http://localhost:8081", "index_name": "HybridSearch"}
Pinecone: Managed vector database service optimized for real-time applications
VECTOR_DB=pinecone
PINECONE_VECTOR_DB_CONFIG={"api_key": "your_api_key", "region": "us-east-1", "cloud": "aws", "index_name": "hybrid-search"}
PostgreSQL: Traditional database with pgvector extension for vector similarity search
VECTOR_DB=postgres
POSTGRES_VECTOR_DB_CONFIG={"host": "localhost", "port": 5433, "database": "postgres", "username": "postgres", "password": "your_password"}
LanceDB: Modern, lightweight vector database designed for high-performance ML applications
VECTOR_DB=lancedb
LANCEDB_VECTOR_DB_CONFIG={"uri": "./lancedb", "table_name": "hybrid_search"}
For faster document ingest processing (no graph extraction), and hybrid search with only full text + vector, configure:
VECTOR_DB=qdrant # Any vector store
SEARCH_DB=elasticsearch # Any search engine
PG_GRAPH_DB=none
Set PG_GRAPH_DB to select the store and GRAPH_BACKEND=llamaindex or langchain for the framework where both are supported. LangChain-only stores (ArangoDB, Apache AGE, HugeGraph, SurrealDB, TigerGraph, Cosmos Gremlin) route property-graph ingestion and retrieval through LangChain adapters regardless of other env defaults. LlamaIndex-only stores (Spanner): when PG_GRAPH_DB=spanner, startup forces GRAPH_BACKEND=llamaindex and ignores GRAPH_BACKEND=langchain.
Neo4j Property Graph: Primary knowledge graph storage with Cypher querying
PG_GRAPH_DB=neo4j
NEO4J_GRAPH_DB_CONFIG={"uri": "bolt://localhost:7687", "username": "neo4j", "password": "your_password"}
ArcadeDB: Multi-model database supporting graph, document, key-value, and search with SQL and Cypher
PG_GRAPH_DB=arcadedb
ARCADEDB_GRAPH_DB_CONFIG={"host": "localhost", "port": 2480, "username": "root", "password": "password", "database": "flexible_graphrag", "query_language": "sql"}
FalkorDB: High-performance graph database using GraphBLAS; purpose-built for LLM / GraphRAG
PG_GRAPH_DB=falkordb
FALKORDB_GRAPH_DB_CONFIG={"url": "falkor://localhost:6379", "database": "falkor"}
Ladybug: Embedded property graph database (Cypher, single .lbug file) with optional structured schema and HNSW vector index on chunks; Explorer UI via Docker (port 7003)
PG_GRAPH_DB=ladybug
LADYBUG_GRAPH_DB_CONFIG={"db_dir": "./ladybug", "db_file": "database.lbug", "use_vector_index": true, "has_structured_schema": false, "strict_schema": false}
MemGraph: Real-time graph database with streaming support and advanced graph algorithms
PG_GRAPH_DB=memgraph
MEMGRAPH_GRAPH_DB_CONFIG={"url": "bolt://localhost:7687", "username": "", "password": ""}
NebulaGraph: Distributed graph database for large-scale data with horizontal scalability
PG_GRAPH_DB=nebula
NEBULA_GRAPH_DB_CONFIG={"space": "flexible_graphrag", "host": "localhost", "port": 9669, "username": "root", "password": "nebula"}
Amazon Neptune: Fully managed graph database service supporting property graph and RDF models
PG_GRAPH_DB=neptune
NEPTUNE_GRAPH_DB_CONFIG={"host": "your-cluster.region.neptune.amazonaws.com", "port": 8182}
Amazon Neptune Analytics: Serverless graph analytics with openCypher support
PG_GRAPH_DB=neptune_analytics
NEPTUNE_ANALYTICS_GRAPH_DB_CONFIG={"graph_identifier": "g-xxxxx", "region": "us-east-1"}
Google Cloud Spanner Graph (LlamaIndex only): Managed relational + property graph (GQL). Uses llama-index-spanner — install with uv pip install -e ".[spanner-extras]" then uv pip uninstall llama-index (see Optional under Prerequisites). LangChain is not supported for this store (langchain-google-spanner pins incompatible langchain-core).
PG_GRAPH_DB=spanner
# GRAPH_BACKEND=llamaindex is forced for Spanner (LlamaIndex-only); langchain is ignored
SPANNER_GRAPH_DB_CONFIG={"project_id": "my-gcp-project", "instance_id": "my-spanner-instance", "database_id": "my-database", "graph_name": "knowledge_graph", "credentials_file": "./gcs.json"}
ArangoDB (LangChain only): Multi-model database with AQL graph queries
PG_GRAPH_DB=arangodb
ARANGODB_GRAPH_DB_CONFIG={"url": "http://localhost:8529", "database": "flexible_graphrag", "username": "root", "password": "password"}
Apache AGE (LangChain only): PostgreSQL extension for graph data via Cypher
PG_GRAPH_DB=apache_age
APACHE_AGE_GRAPH_DB_CONFIG={"host": "localhost", "port": 5434, "database": "flexible_graphrag_age", "username": "postgres", "password": "password", "graph_name": "knowledge_graph"}
HugeGraph (LangChain only): Distributed graph database with Gremlin and openCypher
PG_GRAPH_DB=hugegraph
HUGEGRAPH_GRAPH_DB_CONFIG={"host": "localhost", "port": 8082, "database": "hugegraph"}
SurrealDB (LangChain only): Multi-model database with SurrealQL graph queries
PG_GRAPH_DB=surrealdb
SURREALDB_GRAPH_DB_CONFIG={"url": "ws://localhost:8010/rpc", "namespace": "test", "database": "flexible_graphrag", "username": "root", "password": "root"}
TigerGraph (LangChain only): Distributed graph database with GSQL
PG_GRAPH_DB=tigergraph
TIGERGRAPH_GRAPH_DB_CONFIG={"host": "http://localhost", "port": 14240, "restpp_port": 9002, "database": "MyGraph", "username": "tigergraph", "password": "tigergraph"}
Cosmos Gremlin (LangChain only): Azure Cosmos DB for Gremlin API
PG_GRAPH_DB=cosmos_gremlin
COSMOS_GREMLIN_GRAPH_DB_CONFIG={"url": "ws://localhost:8182/gremlin"}
None: Disable knowledge graph extraction for RAG-only mode
PG_GRAPH_DB=none
Flexible GraphRAG supports RDF/RDFS/OWL ontologies to guide knowledge graph extraction, with optional RDF graph store backends. Ontology-guided extraction works with any configured store — property graph, RDF graph store, or both.
owl:Class, owl:ObjectProperty, owl:DatatypeProperty, rdfs:domain, rdfs:range) to constrain entity/relation extraction; OWL is supported but not required{| |} syntax); XSD-typed literals from OWL DatatypeProperty rangesRDF Graph Store Configuration — set RDF_GRAPH_DB to select the store (all four support RDF 1.2 triple terms; Neptune is AWS-managed—no local compose include):
Apache Jena Fuseki — SPARQL 1.1 server; dashboard: http://localhost:3030
RDF_GRAPH_DB=fuseki
FUSEKI_BASE_URL=http://localhost:3030
FUSEKI_DATASET=flexible-graphrag
Ontotext GraphDB — enterprise RDF store with OWL reasoning; dashboard: http://localhost:7200
RDF_GRAPH_DB=graphdb
GRAPHDB_BASE_URL=http://localhost:7200
GRAPHDB_REPOSITORY=flexible-graphrag
GRAPHDB_USERNAME=admin
GRAPHDB_PASSWORD=admin
Oxigraph — lightweight local store, native RDF 1.2; dashboard: http://localhost:7878
RDF_GRAPH_DB=oxigraph
OXIGRAPH_URL=http://localhost:7878
Amazon Neptune RDF — managed SPARQL 1.1 on Neptune (same cluster can host property graph and RDF; IAM SigV4 auth). See Neptune RDF setup.
RDF_GRAPH_DB=neptune_rdf
NEPTUNE_RDF_HOST=db-neptune-1.cluster-xxxxxxxxxxxx.us-east-1.neptune.amazonaws.com
NEPTUNE_RDF_PORT=8182
NEPTUNE_RDF_REGION=us-east-1
NEPTUNE_RDF_USE_IAM_AUTH=true
NEPTUNE_RDF_USE_HTTPS=true
# Optional explicit keys (else default AWS credential chain):
# NEPTUNE_RDF_AWS_ACCESS_KEY_ID=
# NEPTUNE_RDF_AWS_SECRET_ACCESS_KEY=
None — disable RDF graph store:
RDF_GRAPH_DB=none
Docker Setup: Uncomment local RDF store includes in docker-compose.yaml (Fuseki, GraphDB, Oxigraph):
includes:
# - includes/jena-fuseki.yaml
# - includes/ontotext-graphdb.yaml
# - includes/oxigraph.yaml
Complete Documentation: docs/DATABASES/RDF/RDF-ONTOLOGY-SUPPORT.md | docs/DATABASES/RDF/RDF-STORE-USER-GUIDE.md
Every pipeline stage can independently run on LlamaIndex or LangChain via env var pickers:
| Variable | Options | Description |
|---|---|---|
GRAPH_BACKEND | llamaindex | langchain | Property graph store and KG retrieval |
VECTOR_BACKEND | llamaindex | langchain | Vector store adapter |
SEARCH_BACKEND | llamaindex | langchain | Full-text search adapter |
CHUNKER_BACKEND | llamaindex | langchain | Document chunking / splitting |
KG_EXTRACTOR_BACKEND | llamaindex | langchain | KG extraction from chunks |
RETRIEVAL_FUSION | llamaindex | langchain | Result fusion across retrievers |
LangChain-only graph stores (ArangoDB, Apache AGE, HugeGraph, SurrealDB, TigerGraph, Cosmos Gremlin) auto-select GRAPH_BACKEND=langchain. LlamaIndex-only Spanner (PG_GRAPH_DB=spanner) forces GRAPH_BACKEND=llamaindex at startup and ignores GRAPH_BACKEND=langchain (no LangChain adapter).
Complete Documentation: docs/ADVANCED/LANGCHAIN/LANGCHAIN-GRAPH-INTEGRATION.md
Set via LLM_PROVIDER and provider-specific environment variables.
openai_like) - Any OpenAI-compatible endpoint (LM Studio, LocalAI, Llamafile, vLLM, etc.)scripts/litellm_config.yamlopenai_like on Windows)See docs/LLM/LLM-EMBEDDING-CONFIG.md for all 13 providers with detailed configuration examples.
OpenAI (recommended):
LLM_PROVIDER=openai
OPENAI_API_KEY=your_api_key
OPENAI_MODEL=gpt-4o-mini
Ollama (local):
LLM_PROVIDER=ollama
OLLAMA_BASE_URL=http://localhost:11434
OLLAMA_MODEL=llama3.2:latest
Azure OpenAI:
LLM_PROVIDER=azure_openai
AZURE_OPENAI_API_KEY=your_key
AZURE_OPENAI_ENDPOINT=https://your-resource.openai.azure.com/
AZURE_OPENAI_ENGINE=gpt-4o-mini
Set EMBEDDING_KIND to choose the embedding provider — independent of the LLM provider. All 13 LLM providers are also supported as embedding providers. See docs/LLM/LLM-EMBEDDING-CONFIG.md for all providers and options.
OpenAI:
EMBEDDING_KIND=openai
OPENAI_EMBEDDING_MODEL=text-embedding-3-small
OPENAI_API_KEY=your_api_key
Ollama (local):
EMBEDDING_KIND=ollama
OLLAMA_EMBEDDING_MODEL=nomic-embed-text
OLLAMA_BASE_URL=http://localhost:11434
Azure OpenAI:
EMBEDDING_KIND=azure_openai
AZURE_EMBEDDING_MODEL=text-embedding-3-small
AZURE_EMBEDDING_DEPLOYMENT=your_deployment_name
AZURE_OPENAI_API_KEY=your_key
AZURE_OPENAI_ENDPOINT=https://your-resource.openai.azure.com/
Common embedding dimensions:
When switching embedding models, delete existing vector indexes. See docs/DATABASES/VECTOR-DATABASES/VECTOR-DIMENSIONS.md for cleanup instructions.
When using Ollama, configure system-wide environment variables before starting the Ollama service:
Key requirements:
.env file)OLLAMA_NUM_PARALLEL=4 for optimal performance (or 1-2 if resource constrained)See docs/LLM/OLLAMA-CONFIGURATION.md for complete setup instructions including platform-specific steps and performance optimization.
pyproject.toml)Note: The docker/docker-compose.yaml file can provide all these databases via Docker containers.
cd flexible-graphrag
uv pip install -e .
langchain>=1.0 and the LangChain 1.x line, not legacy 0.3):
uv pip install -e ".[langchain]" — core LC extras: property graph stores via langchain-community where supported, 10 vector stores, 3 search stores, RDF SPARQL retrieval, native LC LLM/embedding clients for all 13 providers, KG extraction via langchain-experimental, retrieval fusionuv pip install --override extras-overrides.txt -e ".[langchain,langchain-extras]" — adds Neo4j (LC), PostgreSQL pgvector, ArcadeDB, ArangoDB, Cosmos Gremlin, HugeGraph, TigerGraph, and related dependencies (see pyproject.toml group langchain-extras)age-extras group (BAEM1N langchain-age driver):
uv pip install --override extras-overrides.txt -e ".[langchain,langchain-extras,age-extras]"
python scripts/patch_langchain_age.py
patch_langchain_age.py on Python 3.14+ (required); on 3.12/3.13 it is harmless.uv pip install -e ".[spanner-extras]" — adds LI-only Spanner support via llama-index-spanner. Note: llama-index-spanner declares llama-index (the meta-package) as a dependency, which uv will install. Uninstall it immediately after: uv pip uninstall llama-index — having both llama-index and llama-index-core installed simultaneously can cause version conflicts, as the meta-package pins versions of llama-index-* component packages that can clash with the versions already required by this projectuv pip install -e ".[surrealdb-extras]"
uv pip install "surrealdb>=2.0" "langchain-core>=1.3"
uv pip install arcadedb-embedded>=26.3.2) — runs ArcadeDB in-process; includes a bundled JVM, no separate Java install needed; latest release: 26.3.2Docker deployment offers multiple scenarios. Before deploying any scenario, set up your environment files:
Environment File Setup (Required for All Scenarios):
Backend Configuration (.env):
# Navigate to backend directory
cd flexible-graphrag
# Linux/macOS
cp env-sample.txt .env
# Windows Command Prompt
copy env-sample.txt .env
# Edit .env with your database credentials, API keys, and settings
# Then return to project root
cd ..
Docker Configuration (docker.env):
# Navigate to docker directory
cd docker
# Linux/macOS
cp docker-env-sample.txt docker.env
# Windows Command Prompt
copy docker-env-sample.txt docker.env
# Edit docker.env for Docker-specific overrides (network addresses, service names)
# Stay in docker directory for next steps
Configuration Setup:
# If not already in docker directory from previous step:
# cd docker
# Edit docker-compose.yaml to uncomment/comment services as needed
# Scenario A setup in docker-compose.yaml:
# Keep these services uncommented (default setup):
- includes/neo4j.yaml
- includes/qdrant.yaml
- includes/elasticsearch-dev.yaml
- includes/kibana-simple.yaml
# Keep these services commented out:
# - includes/app-stack.yaml # Must be commented out for Scenario A
# - includes/proxy.yaml # Must be commented out for Scenario A
# - All other services remain commented unless you want a different vector database,
# graph database, OpenSearch for search, or Alfresco included
Deploy Services:
# From the docker directory
docker-compose -f docker-compose.yaml -p flexible-graphrag up -d
Configuration Setup:
# If not already in docker directory from previous step:
# cd docker
# Edit docker-compose.yaml to uncomment/comment services as needed
# Scenario B setup in docker-compose.yaml:
# Keep these services uncommented:
- includes/neo4j.yaml
- includes/qdrant.yaml
- includes/elasticsearch-dev.yaml
- includes/kibana-simple.yaml
- includes/app-stack.yaml # Backend and UI in Docker
- includes/proxy.yaml # NGINX reverse proxy
# Keep other services commented out unless you want a different vector database,
# graph database, OpenSearch for search, or Alfresco included
Deploy Services:
# From the docker directory
docker-compose -f docker-compose.yaml -p flexible-graphrag up -d
Scenario B Service URLs:
Scenario C: Fully Standalone - Not using docker-compose at all
flexible-graphrag/.envScenario D: Backend/UIs in Docker, Databases External
docker/docker.env: Backend in Docker reads this file
neo4j:7687, qdrant:6333)host.docker.internal:PORTScenario E: Mixed Docker/Standalone
flexible-graphrag/.env: Use host.docker.internal:PORT for locally-running Docker databases, use actual hostnames/IPs for remote Docker or non-Docker databasesManaging Docker services:
# Navigate to docker directory (if not already there)
cd docker
# Create and start services (recreates if configuration changed)
docker-compose -f docker-compose.yaml -p flexible-graphrag up -d
# Stop services (keeps containers)
docker-compose -f docker-compose.yaml -p flexible-graphrag stop
# Start stopped services
docker-compose -f docker-compose.yaml -p flexible-graphrag start
# Stop and remove services
docker-compose -f docker-compose.yaml -p flexible-graphrag down
# View logs
docker-compose -f docker-compose.yaml -p flexible-graphrag logs -f
# Restart after configuration changes
docker-compose -f docker-compose.yaml -p flexible-graphrag down
# Edit docker-compose.yaml, docker.env, or includes/app-stack.yaml as needed
docker-compose -f docker-compose.yaml -p flexible-graphrag up -d
Configuration:
docker/docker-compose.yamlflexible-graphrag/.env with docker/docker.env for Docker-specific overrides (like using service names instead of localhost). No configuration needed in app-stack.yamlSee docker/README.md for detailed Docker configuration.
Note: Skip this entire section if using Scenario B (Full Stack in Docker).
Create environment file (cross-platform):
# Linux/macOS
cp flexible-graphrag/env-sample.txt flexible-graphrag/.env
# Windows Command Prompt
copy flexible-graphrag\env-sample.txt flexible-graphrag\.env
Edit .env with your database credentials and API keys.
# 1. Create and activate a virtual environment
uv venv venv-3.13 --python 3.13
venv-3.13\Scripts\Activate # Windows
source venv-3.13/bin/activate # Linux/macOS
# 2. Install flexible-graphrag
uv pip install flexible-graphrag
# 3. Optionally install ArcadeDB embedded mode support (includes bundled JVM, no Java install needed)
uv pip install arcadedb-embedded>=26.3.2
# 3a. Optional dependency groups, for example:
uv pip install "flexible-graphrag[langchain]"
# Other extras ([langchain-extras], [age-extras], overrides): see source README, Prerequisites > Optional.
# 4. Create .env from the sample (copy from the source repo or download env-sample.txt)
copy env-sample.txt .env # Windows
cp env-sample.txt .env # Linux/macOS
# Edit .env with your LLM API keys and database settings
# 5. Start your databases (docker compose or standalone)
docker compose -f docker/docker-compose.yml up -d
# 6. Run the backend
flexible-graphrag
# or: uv run start.py
Navigate to the backend directory:
cd flexible-graphrag
Create and activate a virtual environment, then install in editable mode:
uv venv venv-3.13 --python 3.13
venv-3.13\Scripts\Activate # Windows
source venv-3.13/bin/activate # Linux/macOS
uv pip install -e .
# see flexible-graphrag/pyproject.toml for all options
# --- Optional: dependency groups from pyproject.toml [project.optional-dependencies] ---
# LangChain (peer framework; use overrides when combining with langchain-extras)
uv pip install -e ".[langchain]"
uv pip install --override extras-overrides.txt -e ".[langchain,langchain-extras]"
uv pip install --override extras-overrides.txt -e ".[langchain,langchain-extras,age-extras]"
python scripts/patch_langchain_age.py
uv pip install --override extras-overrides.txt -e ".[surrealdb-extras]"
uv pip install "surrealdb>=2.0" "langchain-core>=1.3"
uv pip install --override extras-overrides.txt -e ".[spanner-extras]"
uv pip uninstall llama-index
# RDF extras (base install already includes rdflib/pyoxigraph; use these if you need the named groups)
uv pip install -e ".[rdf]"
uv pip install -e ".[rdf-full]"
# Observability
uv pip install -e ".[observability]"
uv pip install -e ".[observability-openlit]"
uv pip install -e ".[observability-dual]"
# Development tests / tooling
uv pip install -e ".[dev]"
# Docling OCR backends (see DOCLING_OCR in env-sample)
uv pip install -e ".[docling-ocr-easyocr]"
uv pip install -e ".[docling-ocr-tesserocr]"
uv pip install -e ".[docling-ocr-ocrmac]" # macOS only
# Embedded ArcadeDB (not a bracket extra; bundled JVM)
uv pip install arcadedb-embedded>=26.3.2
uv-managed venv (alternative): change managed = false to managed = true in pyproject.toml [tool.uv] section, then just run uv pip install -e ..
Notes: run only the optional lines you need. For age-extras, run patch_langchain_age.py on Python 3.14+ (safe on 3.12/3.13). For surrealdb-extras, keep the follow-up surrealdb / langchain-core upgrades. For spanner-extras, uv pip uninstall llama-index removes the meta-package pulled in by llama-index-spanner. See ### Optional under Prerequisites for context.
Windows Note: If installation fails with "Microsoft Visual C++ 14.0 or greater is required" error, install Microsoft C++ Build Tools (required for compiling Docling dependencies). Select "Desktop development with C++" during installation.
Create a .env file by copying the sample and customizing:
cp env-sample.txt .env # Linux/macOS
copy env-sample.txt .env # Windows
Edit .env with your specific configuration. See docs/GETTING-STARTED/ENVIRONMENT-CONFIGURATION.md for detailed setup guide.
Note: The system requires Python 3.12, 3.13, or 3.14 as specified in pyproject.toml (requires-python = ">=3.12,<3.15"). Python 3.12 and 3.13 are fully tested. Python 3.14 works with the patches applied automatically in main.py at startup. Virtual environment management is controlled by managed = false in pyproject.toml [tool.uv] section (you control venv creation and naming).
flexible-graphrag # after uv pip install flexible-graphrag
# or: uv run start.py # with source
The backend will be available at http://localhost:8000.
Standalone backend and frontend URLs:
Choose one of the following frontend options to work with:
Navigate to the React frontend directory:
cd flexible-graphrag-ui/frontend-react
Install Node.js dependencies (first time only):
npm install
Start the development server (uses Vite):
npm run dev
The React frontend will be available at http://localhost:5174.
Navigate to the Angular frontend directory:
cd flexible-graphrag-ui/frontend-angular
Install Node.js dependencies (first time only):
npm install
Start the development server (uses Angular CLI):
npm start
The Angular frontend will be available at http://localhost:4200.
Navigate to the Vue frontend directory:
cd flexible-graphrag-ui/frontend-vue
Install Node.js dependencies (first time only):
npm install
Start the development server (uses Vite):
npm run dev
The Vue frontend will be available at http://localhost:3000.
The system provides a tabbed interface for document processing and querying. Follow these steps in order. See docs/UI-GUIDE/UI-GUIDE.md for full details.
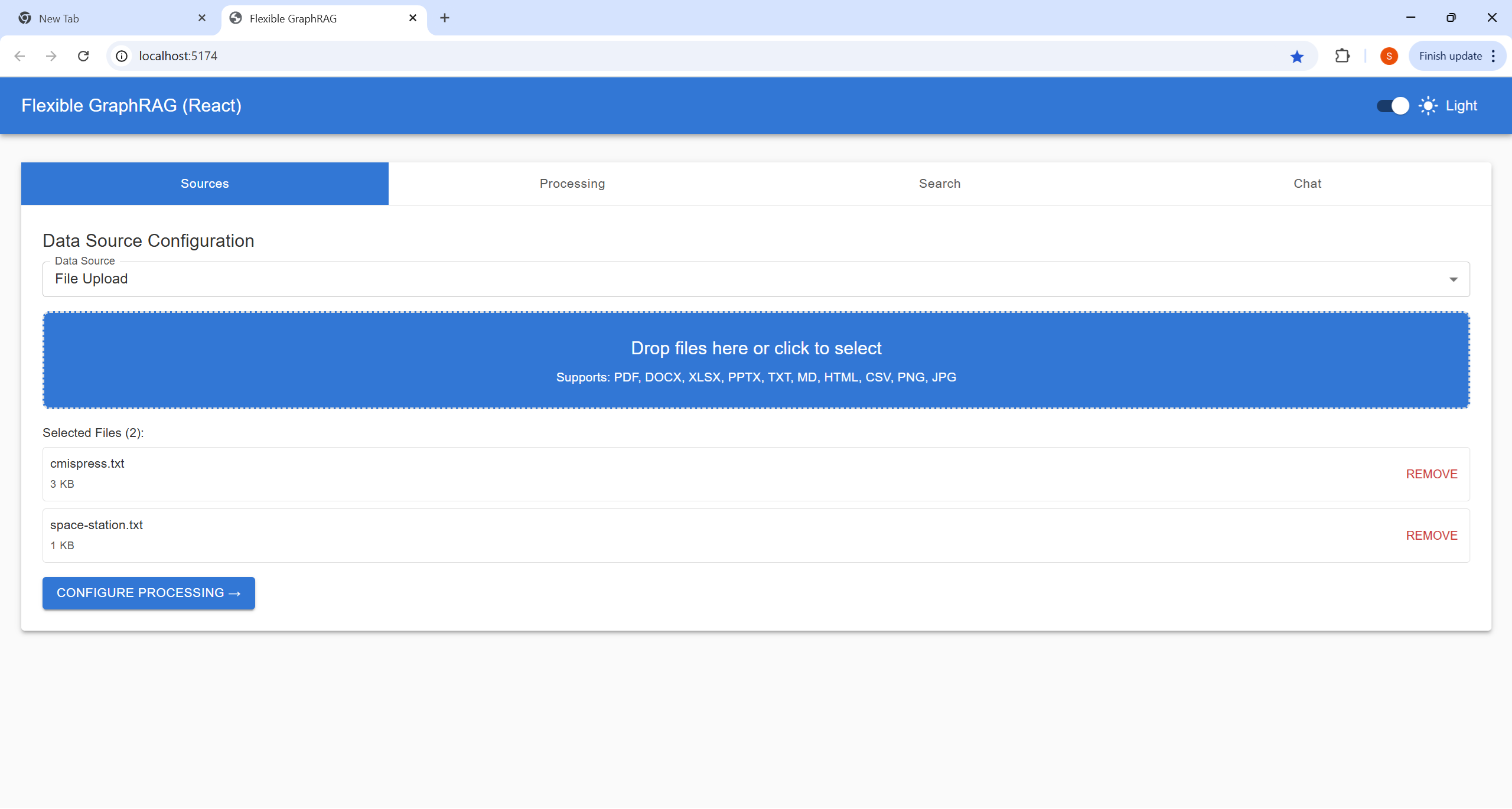
Configure your data source and select files for processing. The system supports 13 data sources:
Detailed Configuration:
http://localhost:8080/alfresco)/Sites/example/documentLibrary)http://localhost:8080/alfresco/api/-default-/public/cmis/versions/1.1/atom)/Sites/example/documentLibrary)All Data Sources (13 available):
See the Data Sources section for complete details on all 13 sources.
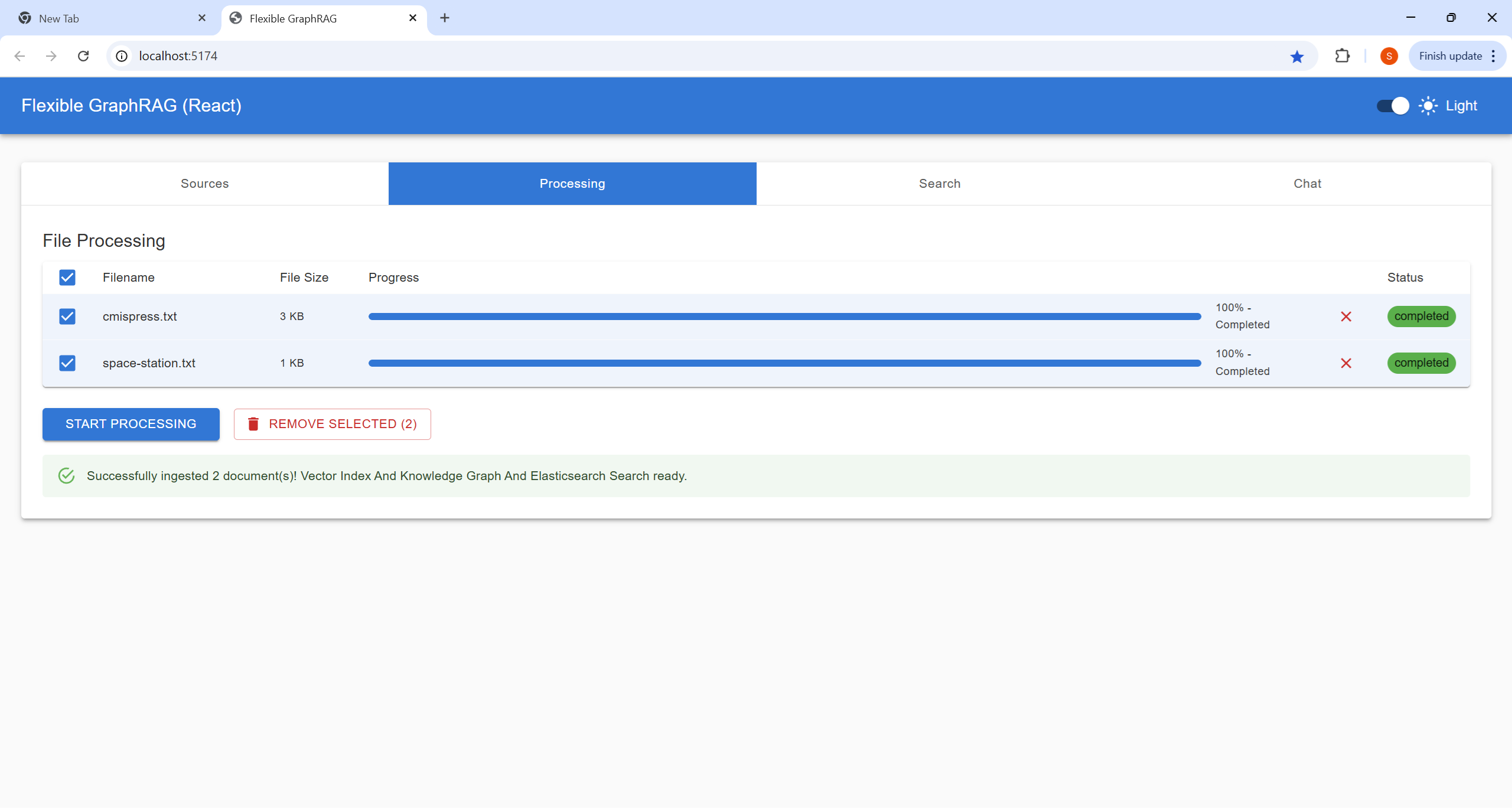
Process your selected documents and monitor progress:
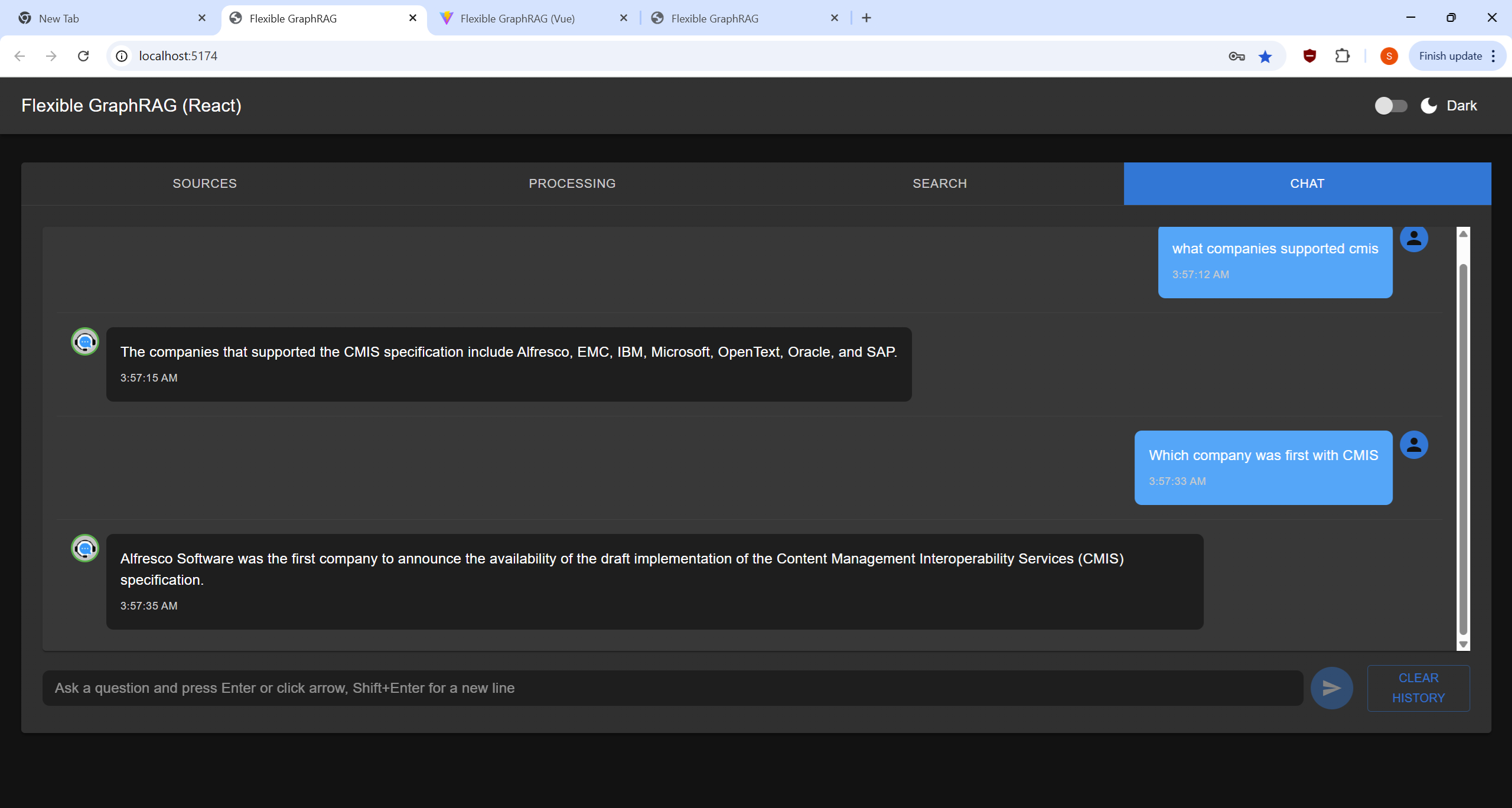
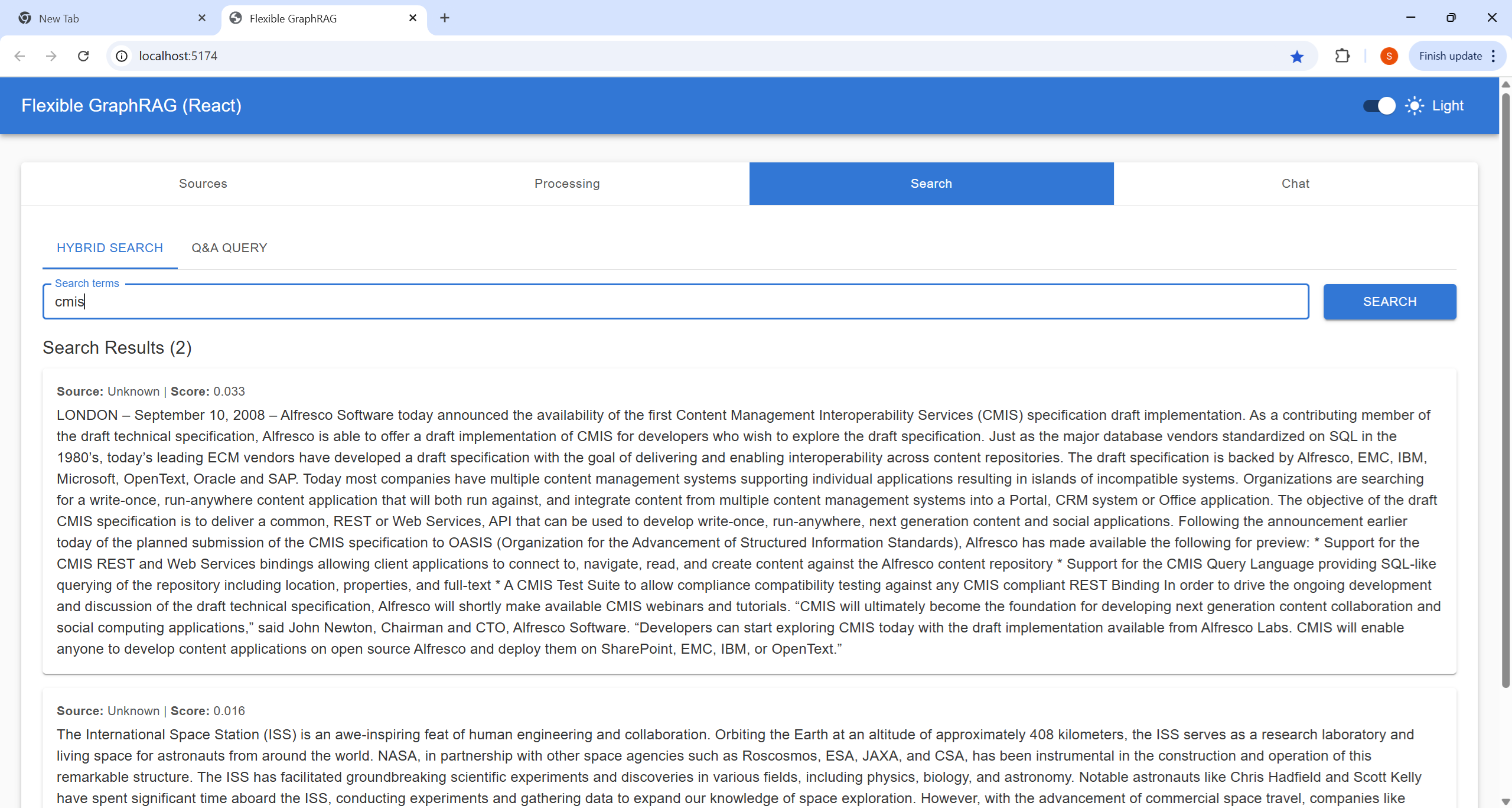
Perform searches on your processed documents:
Interactive conversational interface for document Q&A:
Between tests you can clean up data:
cleanup.py: Clears vector, graph, and search indexes in one step — run from the flexible-graphrag directoryThe MCP server (flexible-graphrag-mcp) is a lightweight standalone package that connects MCP clients (Claude Desktop, Cursor, etc.) to the Flexible GraphRAG backend via its REST API.
For full details see flexible-graphrag-mcp/README.md and flexible-graphrag-mcp/QUICK-USAGE-GUIDE.md. For the full list of available MCP tools see MCP Tools for Claude Desktop and Other MCP Clients below.
First terminal — install and run the flexible-graphrag backend (see Python Backend Setup above) — it must be running on http://localhost:8000.
Second terminal — install and start the MCP server in HTTP mode:
uv venv venv-mcp --python 3.13
venv-mcp\Scripts\Activate # Windows
source venv-mcp/bin/activate # Linux/macOS
uv pip install flexible-graphrag-mcp
flexible-graphrag-mcp --http --port 3001
Third terminal — test with MCP Inspector:
npx @modelcontextprotocol/inspector
Open the URL printed in the console (token pre-filled), set transport to Streamable HTTP, URL to http://localhost:3001/mcp, then click Connect.
Use with Claude Desktop and other MCP clients — see flexible-graphrag-mcp/README.md for stdio transport config and client-specific setup.
The MCP server provides 9 specialized tools for document intelligence workflows:
| Tool | Purpose | Usage |
|---|---|---|
get_system_status() | System health and configuration | Verify setup and database connections |
ingest_documents() | Bulk document processing | All sources support skip_graph; filesystem/Alfresco/CMIS use paths; Alfresco also supports nodeDetails list (13 sources have their own config: filesystem, repositories (Alfresco, SharePoint, Box, CMIS), cloud storage, web) |
ingest_text(content, source_name) | Custom text analysis | Analyze specific text content |
search_documents(query, top_k) | Hybrid document retrieval | Find relevant document excerpts |
query_documents(query, top_k) | AI-powered Q&A | Generate answers from document corpus |
test_with_sample() | System verification | Quick test with sample content |
check_processing_status(id) | Async operation monitoring | Track long-running ingestion tasks |
get_python_info() | Environment diagnostics | Debug Python environment issues |
health_check() | Backend connectivity | Verify API server connection |
The FastAPI backend provides the following REST API endpoints:
Base URL: http://localhost:8000/api/
System
| Endpoint | Method | Purpose |
|---|---|---|
/api/health | GET | Health check — verify backend is running |
/api/status | GET | System status and configuration (databases, LLM, feature flags) |
/api/info | GET | System information and package versions |
/api/python-info | GET | Python environment diagnostics |
Ingestion
| Endpoint | Method | Purpose |
|---|---|---|
/api/ingest | POST | Ingest documents from a data source (filesystem, s3, web, cmis, ...) |
/api/upload | POST | Upload files directly for processing |
/api/ingest-text | POST | Ingest raw text content |
/api/test-sample | POST | Test the system with built-in sample content |
/api/cleanup-uploads | POST | Remove temporarily uploaded files |
Async Processing
| Endpoint | Method | Purpose |
|---|---|---|
/api/processing-status/{id} | GET | Poll status of an async ingestion operation |
/api/processing-events/{id} | GET | Server-Sent Events stream for real-time progress |
/api/cancel-processing/{id} | POST | Cancel an ongoing processing operation |
Search & Query
| Endpoint | Method | Purpose |
|---|---|---|
/api/search | POST | Hybrid search — returns ranked document excerpts |
/api/query | POST | AI-powered Q&A — generates an answer from the document corpus |
Graph
| Endpoint | Method | Purpose |
|---|---|---|
/api/graph | GET | Graph database status and node/relationship counts (Neo4j: live Cypher counts; other LC-backed stores: counts via lc_graph.query() where supported; remaining stores: status + dashboard URL) |
/api/graph/query | POST | Execute a native graph query against the configured store — Cypher (Neo4j, Memgraph, FalkorDB, ArcadeDB, Ladybug, Apache AGE), AQL (ArangoDB), SurrealQL (SurrealDB), Gremlin (Cosmos), GSQL (TigerGraph), openCypher (Neptune/Analytics), GQL (Spanner), SPARQL fallback for RDF-only |
RDF / Ontology (when RDF_GRAPH_DB is configured)
| Endpoint | Method | Purpose |
|---|---|---|
/api/rdf/query/sparql | POST | Execute a SPARQL query against the configured RDF store |
/api/rdf/ontology/info | GET | Return loaded ontology entity and relation type lists |
/api/rdf/ontology/upload | POST | Upload a new ontology file at runtime |
/api/rdf/rdf-store/list | GET | List registered RDF stores |
/api/rdf/rdf-store/connect | POST | Register an additional RDF store at runtime |
/api/rdf/rdf-store/{name} | DELETE | Deregister an RDF store |
/api/rdf/export/rdf | POST | Export knowledge graph as RDF (501 stub — not yet implemented) |
Interactive API Documentation (requires running backend):
| UI | URL | Notes |
|---|---|---|
| Swagger UI | http://localhost:8000/docs | Try endpoints, inspect schemas, submit requests |
| ReDoc | http://localhost:8000/redoc | Cleaner read-only reference view |
See docs/DEVELOPER/REST-API.md for the full endpoint reference with request/response examples.
VS Code launch configurations, backend/frontend debugging, log levels, and MCP Inspector setup — see docs/DEVELOPER/DEVELOPER-FULL-STACK-DEBUGGING.md.
Flexible GraphRAG includes comprehensive observability features for production monitoring:
Install observability dependencies (optional):
cd flexible-graphrag
uv pip install -e ".[observability-dual]" # OpenInference (LlamaIndex + LangChain) + OpenLIT (recommended)
# Or combine with dev tools: uv pip install -e ".[observability-dual,dev]"
Enable in .env:
ENABLE_OBSERVABILITY=true
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318
OBSERVABILITY_BACKEND=both # openinference, openlit, or both (recommended)
Start observability stack:
cd docker
# Uncomment observability.yaml in docker-compose.yaml first
docker-compose -f docker-compose.yaml -p flexible-graphrag up -d
Access dashboards:
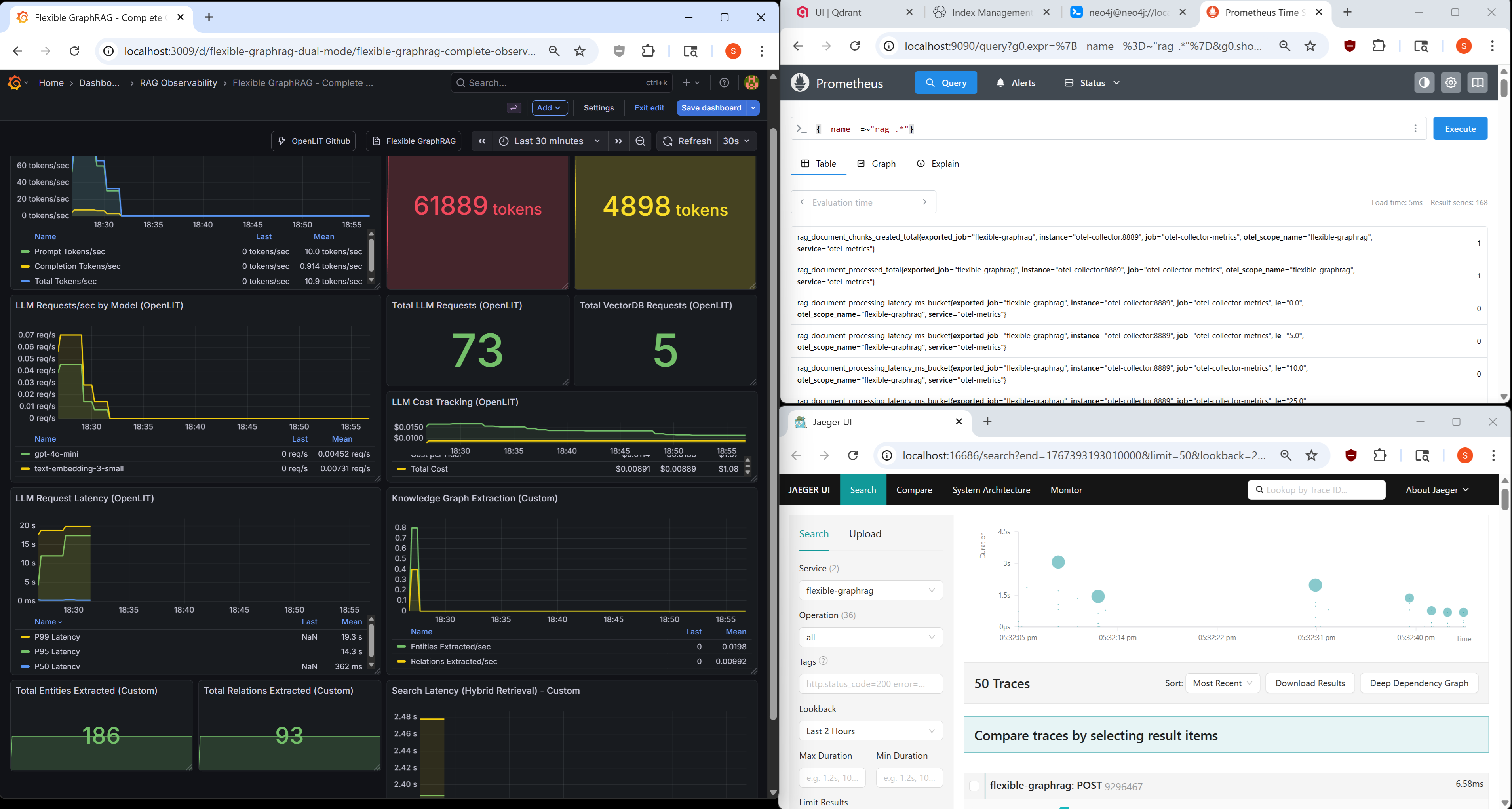
See docs/DEVELOPER/OBSERVABILITY/OBSERVABILITY.md for complete setup, custom instrumentation, and production best practices.
/flexible-graphrag: Python FastAPI backend
main.py: FastAPI REST API serverbackend.py: Shared business logic used by both API and MCPconfig.py: Configurable settings for data sources, databases, and LLM providersfactories.py: Factory classes for LLM and database creationhybrid_system.py: Main hybrid search and ingestion systempost_ingestion_state.py: Post-ingestion document state trackingquery_engine.py: Query engine with result deduplication and re-scoringretriever_setup.py: Retriever assembly — vector, search, graph, RDF, synonym expansionschema_manager.py: Database schema managementadapters/: Framework-neutral ABCs and factories for all subsystems
adapters/graph/: Property graph and RDF store adapter ABCsadapters/llm/: LLM and embedding adapter ABCs (BothLLMAdapter, BothEmbeddingAdapter)adapters/process/: Chunker and KG extractor ABCs and build_* factoriesadapters/search/: Search store adapter ABCadapters/vector/: Vector store adapter ABCincremental_updates/: Auto-sync engine — detectors, orchestrator, state manager for real-time/near-real-time source syncingest/: Modular ingestion steps — ingest_from_files, ingest_from_text, ingest_from_source, run_chunk_pipeline, update_pg_graph, update_rdf_graph, update_vector, update_searchlangchain/: LangChain peer framework — graph, vector, search, chunking, KG extraction, retrieval
langchain/graph/pg_store_adapters/: 15 property graph store adapters (one file per store)langchain/graph/rdf_store_adapters/: 4 RDF/SPARQL store adapters (Fuseki, GraphDB, Oxigraph, Neptune)langchain/graph/retrievers/: li_/lc_ two-layer retriever classes — text-to-query, neighborhood, vector, logging, synonymlangchain/llm/: LangChain LLM + embedding factories for all 13 providerslangchain/process/: LangChainChunkerAdapter (6 splitter types), LangChainKGExtractorAdapterlangchain/search/adapters/: BM25, Elasticsearch, OpenSearch search adapterslangchain/vector/adapters/: 10 vector store adaptersllamaindex/: LlamaIndex peer framework — graph, vector, search, chunking, KG extraction
llamaindex/graph/adapters/: LlamaIndex property graph store adapters (Neo4j, ArcadeDB, FalkorDB, Memgraph, Nebula, Neptune, etc.)llamaindex/llm/: LlamaIndex LLM + embedding factories for all 13 providersllamaindex/process/: LlamaIndexChunkerAdapter, LlamaIndexKGExtractorAdapterllamaindex/search/adapters/: Elasticsearch, OpenSearch search adaptersllamaindex/vector/adapters/: Qdrant, Elasticsearch, OpenSearch, pgvector, Chroma, and othersobservability/: OpenTelemetry instrumentation, Prometheus metrics, tracing setupprocess/: Core document processing — document_processor.py (Docling/LlamaParse), kg_extractor.py, node_pipeline.pyrdf/: RDF/ontology support — ontology manager, KG-to-RDF converter, SPARQL tools, bundled schemas (rdf/schemas/)
rdf/store/: RDF store adapters — Fuseki, GraphDB, Oxigraph, store factorysources/: Data source connectors — filesystem, CMIS/Alfresco, Azure Blob, S3, GCS, OneDrive, SharePoint, Google Drive, Box, web, Wikipedia, YouTube, etc.stores/: Index managers — index_manager.py, rdf_manager.pypyproject.toml: Modern Python package definition (PEP 517/518)uv.toml: UV package manager configurationstart.py: Startup script (flexible-graphrag console entry point)install.py: Installation helper script/flexible-graphrag-mcp: Standalone MCP server
main.py: HTTP-based MCP server (calls REST API)pyproject.toml: MCP package definition with minimal dependenciesREADME.md: MCP server setup and installation instructionsQUICK-USAGE-GUIDE.md: Quick usage guide/flexible-graphrag-ui: Frontend applications
/frontend-react: React + TypeScript frontend (built with Vite)
/src: Source codevite.config.ts: Vite configurationtsconfig.json: TypeScript configurationpackage.json: Node.js dependencies and scripts/frontend-angular: Angular + TypeScript frontend (built with Angular CLI)
/src: Source codeangular.json: Angular configurationtsconfig.json: TypeScript configurationpackage.json: Node.js dependencies and scripts/frontend-vue: Vue + TypeScript frontend (built with Vite)
/src: Source codevite.config.ts: Vite configurationtsconfig.json: TypeScript configurationpackage.json: Node.js dependencies and scripts/docker: Docker infrastructure
docker-compose.yaml: Main compose file with modular includes/includes: Modular database and service configurations/nginx: Reverse proxy configurationREADME.md: Docker deployment documentation/docs: Documentation
ARCHITECTURE.md: System architecture and component relationshipsDEPLOYMENT-CONFIGURATIONS.md: Standalone, hybrid, and full Docker deployment guidesDOCKER-RESOURCE-CONFIGURATION.md: Docker memory/CPU configuration for Windows (WSL2), macOS, and Linux — essential for running the full stack, especially with vLLMENVIRONMENT-CONFIGURATION.md: Environment setup guide with database switchingPOSTGRES-SETUP.md: PostgreSQL setup for pgvector and incremental state managementSCHEMA-EXAMPLES.md: Knowledge graph schema examplesPERFORMANCE.md: Performance benchmarks and optimization guidesDEFAULT-USERNAMES-PASSWORDS.md: Database credentials and dashboard accessPORT-MAPPINGS.md: Complete port reference for all servicesDATA-SOURCES/: Data source setup guides (Azure Blob, S3, GCS, Alfresco etc.)DOC-PROCESSING/: Document processing guides (Docling GPU, parser output)GRAPH-DATABASES/: Graph database guides (Neo4j, Neptune, Nebula, ArcadeDB, etc.)INCREMENTAL-UPDATE-AUTO-SYNC/: Incremental updates documentation (README, QUICKSTART, SETUP-GUIDE, API-REFERENCE)LLM/: LLM and embedding configuration guidesLANGCHAIN/: LangChain integration guides (RDF QA fusion, graph retriever setup, adapter reference)OBSERVABILITY/: Observability and monitoring guidesRDF/: RDF/ontology guides (store setup, ontology config, ingestion modes, SPARQL examples, user guide)VECTOR-DATABASES/: Vector database guides (dimensions, integration, Chroma modes)/scripts: Utility scripts
create_opensearch_pipeline.py: OpenSearch hybrid search pipeline setupsetup-opensearch-pipeline.sh/.bat: Cross-platform pipeline creationrdf_cleanup.py: RDF store CLI tool — list-docs, count, clear-doc, clear-alllitellm_config.yaml: Sample LiteLLM proxy config (copy to your LiteLLM install dir)/incremental: Incremental updates control scripts
sync-now.sh/.ps1/.bat: Trigger immediate synchronizationset-refresh-interval.sh/.ps1/.bat: Configure polling intervalREADME.md: Script usage documentation/tests: Test suite
test_bm25_*.py: BM25 configuration and integration testsconftest.py: Test configuration and fixturesrun_tests.py: Test runner/examples: Standalone usage examples (not re-tested)
observability_example.py: OpenTelemetry / observability integration example/rdf: RDF/ontology examples
sparql_examples.py: Sample SPARQL queries for all three storesunified_query_engine_examples.py: UnifiedQueryEngine usage examplesstore_index_example.py: Build a LlamaIndex from an RDF storeontology_guided_ingestion_example.py: OntologyAwarePropertyGraphBuilder usageingest_with_ontology.py: Ontology-guided ingestion example classrdf_export_import_examples.py: RDF export/import patternsconfig_rdf_stores.py: RDF store config reference snippetsThis project is licensed under the terms of the Apache License 2.0. See the LICENSE file for details.
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows