

Are you the author? Sign in to claim
Production ready text to speech service built with Kotlin, Kokoro (82M parameters), ONNX Runtime, and Clean Architecture
![]()
A pure-JVM text-to-speech server powered by the Kokoro-82M neural TTS model. Runs ONNX inference natively on the JVM — no Python, no external services. Serves a REST API via Ktor and an MCP endpoint for AI assistant integration.
Supports single-voice synthesis, multi-voice dialogue with natural turn gaps, voice blending, inline phoneme annotations for foreign words, and WAV/MP3 output at 24 kHz.
The entire process of building this project — from model research and G2P engineering to clean architecture, deployment, and performance tuning — is described in detail in How to Build Self-Hosted TTS That Actually Sounds Good.
sdk install java 25-open
git clone https://github.com/alexsobolev/kokoro-tts-kotlin.git
cd kokoro-tts-kotlin
The TTS pipeline requires model weights, voice embeddings, and pronunciation dictionaries (~400 MB total). The script skips files that already exist.
./scripts/download-data.sh
This downloads into the data/ directory:
| File | Size | Source | Description |
|---|---|---|---|
kokoro-v1.0.int8.onnx | 92.3 MB | kokoro-onnx | Quantized ONNX TTS model |
voices-v1.0.bin | 28.2 MB | kokoro-onnx | Voice style embeddings |
config.json | 2.3 KB | Kokoro-82M | Tokenizer vocabulary |
us_gold.json | 3.0 MB | misaki | US English gold pronunciation dict |
us_silver.json | 3.0 MB | misaki | US English silver pronunciation dict |
gb_gold.json | 2.8 MB | misaki | GB English gold pronunciation dict |
gb_silver.json | 3.6 MB | misaki | GB English silver pronunciation dict |
en-pos-perceptron.bin | 3.9 MB | Apache OpenNLP | OpenNLP POS tagger model |
lexicon_fixes.json | 0.1 KB | Local | Custom pronunciation overrides |
By default the server uses local storage — audio files are written to an output/ directory and served via HTTP. No AWS credentials needed.
For S3 storage, set:
export STORAGE_MODE=s3
export AWS_REGION=eu-central-1
export S3_BUCKET=my-tts-bucket
See Configuration for all available settings.
./gradlew build # Compile, lint, static analysis, and tests
Download model and lexicon files (required once; see Download Model Files):
./scripts/download-data.sh
Then run the server:
./gradlew :app:run
The server starts on port 8080 with local file storage (no AWS required). Audio files are saved to output/ and served at http://localhost:8080/audio/.... Swagger UI at /swagger, OpenAPI spec at /openapi.
POST /v1/tts
Single voice:
{
"turns": [
{ "voice": "af_heart", "text": "Hello, world!" }
],
"speed": 1.0,
"format": "wav"
}
Multi-voice dialogue (turns concatenated with randomized 250-500ms silence gaps):
{
"turns": [
{ "voice": "af_heart", "text": "How are you today?" },
{ "voice": "am_adam", "text": "I am doing great, thanks for asking!" }
],
"speed": 1.2,
"format": "mp3"
}
Voice blending (weighted average of style embeddings, weights must sum to 1.0):
{
"turns": [
{ "voice": "af_heart:0.6+af_bella:0.4", "text": "A blended voice." }
]
}
Inline phoneme annotations for foreign words and proper nouns:
{
"turns": [
{ "voice": "af_heart", "text": "We visited (Machu Picchu)[mˈɑːtʃuː pˈiːtʃuː] in (Peru)[pəɹˈuː]." }
]
}
Response (local mode):
{
"url": "http://localhost:8080/audio/af_heart/uuid.wav",
"key": "af_heart/uuid.wav",
"expiresInSeconds": 0,
"sizeBytes": 48044,
"format": "wav",
"voice": "af_heart"
}
Defaults: speed = 1.0, format = "wav", voice = "af_heart".
Limits: speed in [0.5, 2.0], text per turn <= 5,000 characters, at least one turn.
| Endpoint | Description |
|---|---|
GET /health | Health check (returns OK) |
GET /v1/voices | List available voices with IDs and languages |
/mcp | MCP endpoint for AI assistant integration (SSE transport) |
/swagger | Interactive API docs |
| Status | Condition |
|---|---|
| 400 | Text too long, speed out of range, empty dialogue, malformed JSON |
| 404 | Voice not found |
| 500 | Inference or storage failure |
Both the Ktor server and Lambda expose MCP (Model Context Protocol) endpoints, enabling AI assistants like Claude Desktop to synthesize speech as a tool call.
Tools:
list_voices — returns all voice IDs and languagessynthesize_speech — single-voice synthesis with text, voice, speed, format parameterssynthesize_dialogue — multi-turn dialogue with different voices per turnTool descriptions instruct LLMs to wrap foreign proper nouns in (word)[IPA] annotations for correct pronunciation.
Testing with MCP Inspector: connect to http://localhost:8080/mcp (SSE transport).
Claude Desktop (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"kokoro-tts": {
"command": "npx",
"args": ["mcp-remote", "http://localhost:8080/mcp"]
}
}
}
Clean architecture across five Gradle modules:
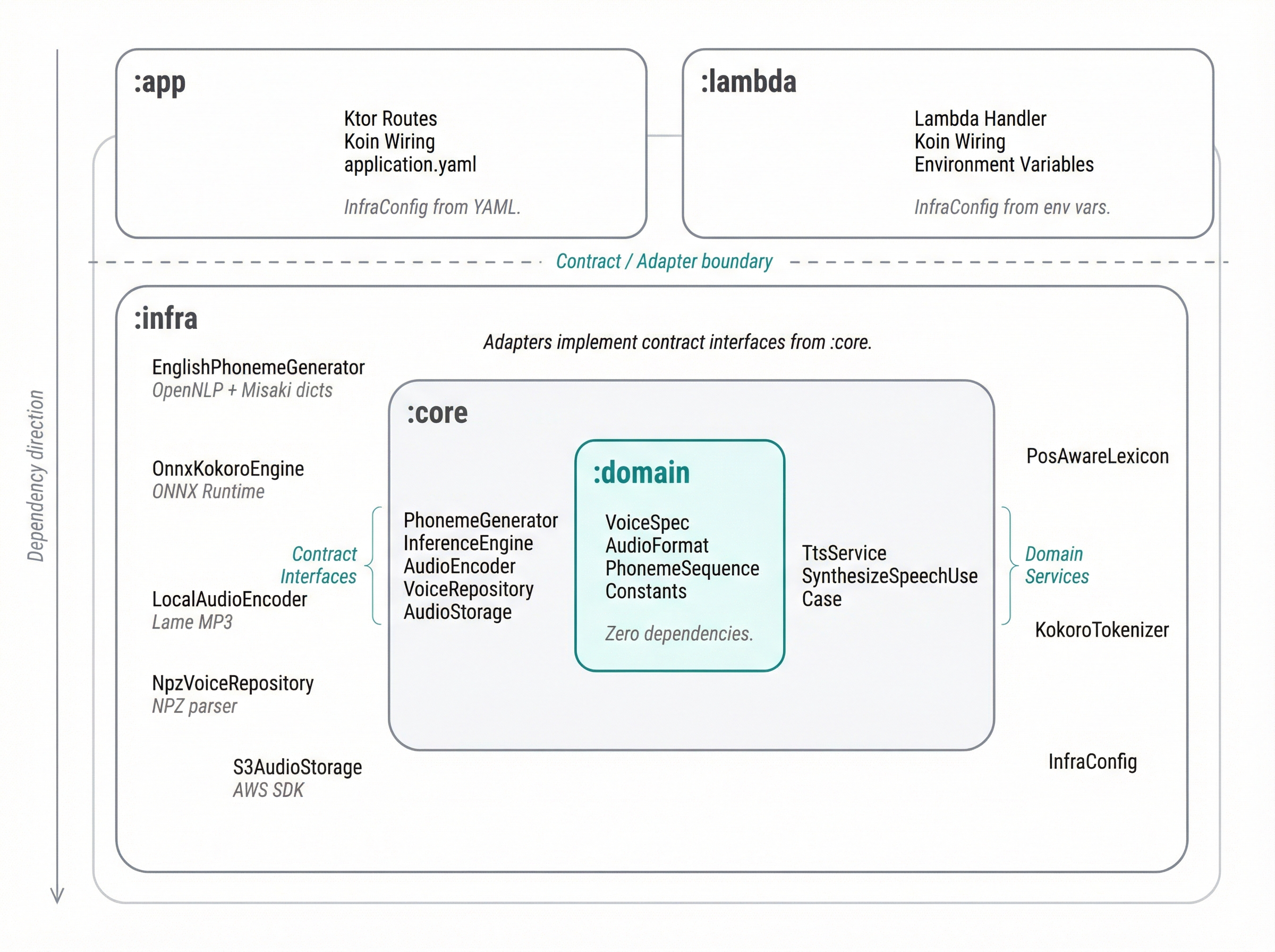
VoiceId, SpeechRate, AudioFormat, SynthesisException), zero dependenciesPhonemeGenerator, InferenceEngine, AudioEncoder, VoiceRepository, AudioStorage), DTOs, use cases, TTS service orchestrationText --> EnglishPhonemeGenerator --> KokoroTokenizer --> OnnxKokoroEngine --> SentencePostProcessor --> LocalAudioEncoder --> AudioStorage
(POS-aware G2P) (IPA -> tokens) (ONNX @ 24kHz) (volume envelopes) (WAV/MP3) (local disk or S3)
EnglishPhonemeGenerator converts English text to IPA phonemes using a POS-aware hybrid approach matching misaki's logic. Four misaki JSON dictionaries are merged at startup (US gold > US silver > GB gold > GB silver) into a PosAwareLexicon that preserves per-POS pronunciation variants (e.g., "live" as adjective lˈIv vs verb lˈɪv, "record" as noun ɹˈɛkəɹd vs verb ɹəkˈɔɹd). A lexicon_fixes.json corrections file is deep-merged on top with the highest priority, fixing 3 upstream misaki VBP bugs (read, reread, wound had present-tense VBP mapped to past-tense pronunciations).
Two-pass pipeline:
futureVowel context, apply function word overrides ("the" → ði/ðə, "to" → tʊ/tə/tu), re-lookup sentence-final words with stressed None-key variantsWord resolution (in priority order):
(word)[IPA] syntax bypasses the entire G2P pipelineði before vowels / ðə before consonants; "to" uses tʊ before vowels / tə before consonants / tu at sentence endNone keyThe Kokoro model doesn't strongly differentiate intonation by punctuation. TtsService and SentencePostProcessor compensate:
?) — 0.92x speed; rising volume ramp (1.0 -> 1.15x, quadratic) on last 600ms. Multi-clause questions split at the last clause boundary!) — gain boost (1.20x -> 1.0, linear fade) on first 400msRMS-windowed speech boundary detection ensures volume effects target voiced content, not model-generated silence.
Blended voices (e.g., af_heart:0.6+af_bella:0.4) are created by weighted averaging of 256-dimensional style embeddings. After blending, the result vector is L2-renormalized to the weighted average of input norms — without this, blended vectors have smaller magnitude and produce degraded audio.
setIntraOpNumThreads()docker build -t kokoro-tts .
docker run -p 8080:8080 kokoro-tts # local storage (default)
docker run -p 8080:8080 \
-e STORAGE_MODE=s3 \
-e AWS_REGION=eu-central-1 \
-e S3_BUCKET=my-tts-bucket \
kokoro-tts # S3 storage
Non-root user, 3 GB heap, ExitOnOutOfMemoryError. Multi-stage build with Gradle dependency caching.
docker build -f Dockerfile.lambda -t kokoro-tts-lambda .
Custom JDK 25 runtime (beyond AWS managed runtimes), 8 GB heap for ONNX model. Koin DI initializes once per container cold start. Auto-detects and decodes base64 request bodies from Lambda Function URLs.
app/src/main/resources/application.yaml:
tts:
tokenizer:
configPath: "data/config.json"
voices:
path: "data/voices-v1.0.bin"
phonemizer:
goldDictPath: "data/us_gold.json"
silverDictPath: "data/us_silver.json"
gbGoldDictPath: "data/gb_gold.json"
gbSilverDictPath: "data/gb_silver.json"
fixesDictPath: "data/lexicon_fixes.json"
pos:
modelPath: "data/en-pos-perceptron.bin"
model:
onnxPath: "data/kokoro-v1.0.int8.onnx"
aws:
region: "$AWS_REGION:"
s3Bucket: "$S3_BUCKET:"
storage:
mode: "$STORAGE_MODE:local"
prefix: "$STORAGE_PREFIX:tts-audio"
localOutputDir: "$LOCAL_OUTPUT_DIR:output"
baseUrl: "$BASE_URL:http://localhost:8080"
All settings support environment variable overrides using Ktor's $ENV_VAR:default syntax. The Lambda handler reads the same settings from environment variables directly.
| Variable | Default | Description |
|---|---|---|
STORAGE_MODE | local | Storage backend: local (disk + HTTP) or s3 |
LOCAL_OUTPUT_DIR | output | Directory for local audio files |
BASE_URL | http://localhost:8080 | Public base URL for local audio download links |
AWS_REGION | — | AWS region (required for s3 mode) |
S3_BUCKET | — | S3 bucket (required for s3 mode) |
STORAGE_PREFIX | tts-audio | S3 object key prefix |
./gradlew build # Compile + ktlint + detekt + tests
./gradlew :app:run # Dev server on port 8080
./gradlew buildFatJar # Fat JAR at app/build/libs/app-all.jar
./gradlew ktlintFormat # Auto-format code
./gradlew koverHtmlReport # Merged code coverage report → build/reports/kover/html/
./gradlew koverXmlReport # Merged XML coverage report (for CI)
The build runs ktlint (formatting), detekt (static analysis), and all tests as a single gate. Kover enforces a minimum 85% line coverage across all five modules with merged reporting at the root level. All tests follow the given-when-then pattern with // given, // when, // then section comments.
See GUIDELINES.md for detailed coding conventions, architecture rules, and design decisions.
Kotlin 2.3.0, JDK 25, Ktor 3.4.0, Koin 4.1.1, ONNX Runtime 1.23.2, Apache OpenNLP 2.5.3, kotlinx.serialization 1.8.1, AWS SDK for Kotlin 1.6.12, MCP SDK 0.8.4, jump3r (LAME MP3 encoder).
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows