

Are you the author? Sign in to claim
A multi-step LangChain v1 sales-conversation agent that uses the Azure OpenAI Responses API, an MCP server with Postgres
page_type: sample languages:
A Python sample that shows how to build a multi-step sales agent with LangChain v1 and Azure OpenAI that drive sales through a 6-step funnel using the handoffs pattern. The agent grounds it's responses in data stored in a Postgres database with pgvector for semantic search. The database is deployed as an Model Context Protocol (MCP) server, that exposes several tools the agent can use to quickly access data. Since the agent is using the Responses API, it can easily connect to MCP servers and comes with several build in tools like a code interpreter and image genration. Get started now.
![]()
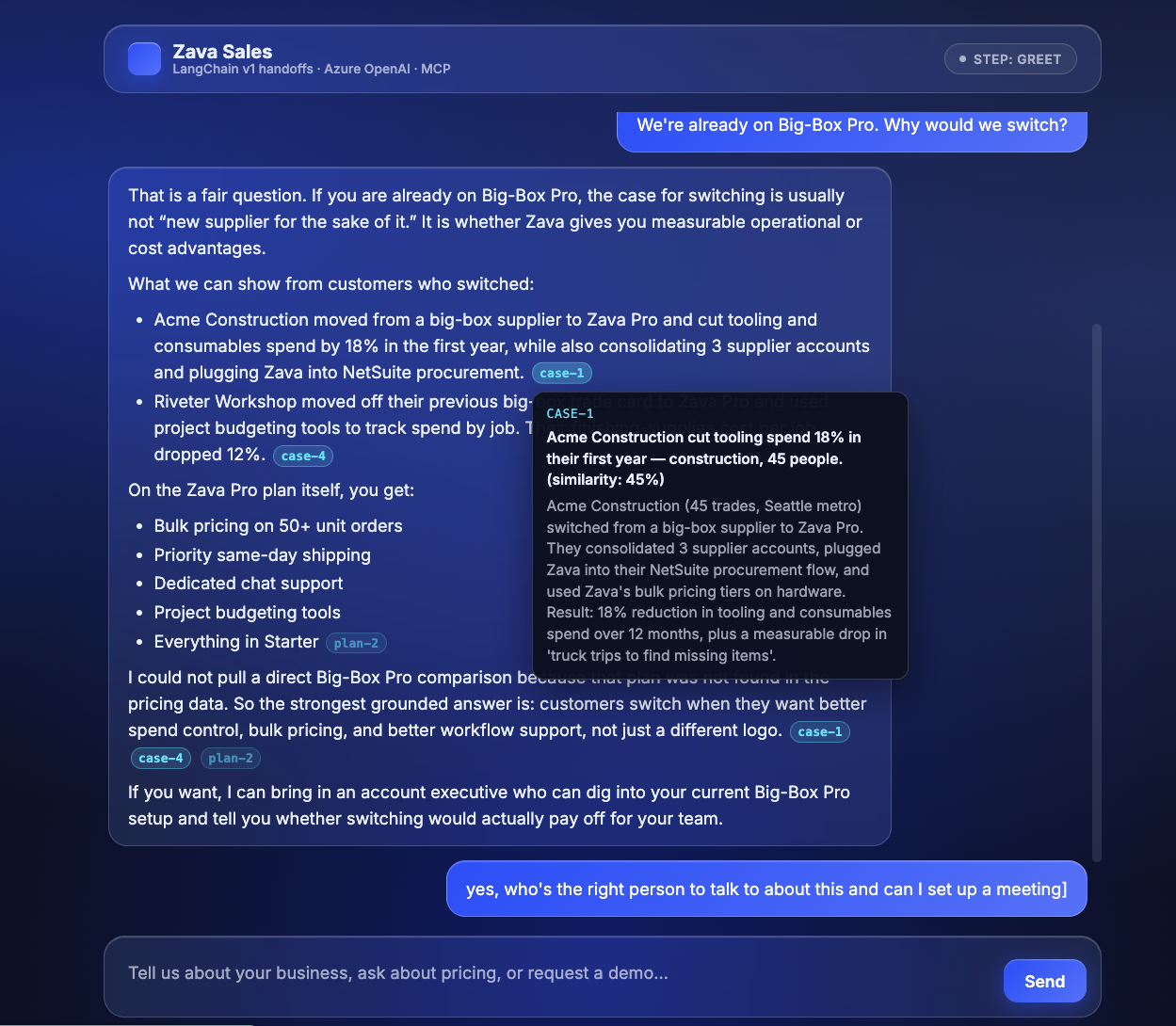
gpt-5.4-mini will power the main agent and middleware tasks will use gpt-5-nano)text-embedding-3-small vectors for case studies, KB articles, and the product catalogue.search_case_studies, search_kb_articles, get_pricing, compare_plans — over streamable HTTP.The core LangChain Agent and the PostgreSQL MCP server are deployed independently as two Container Apps:
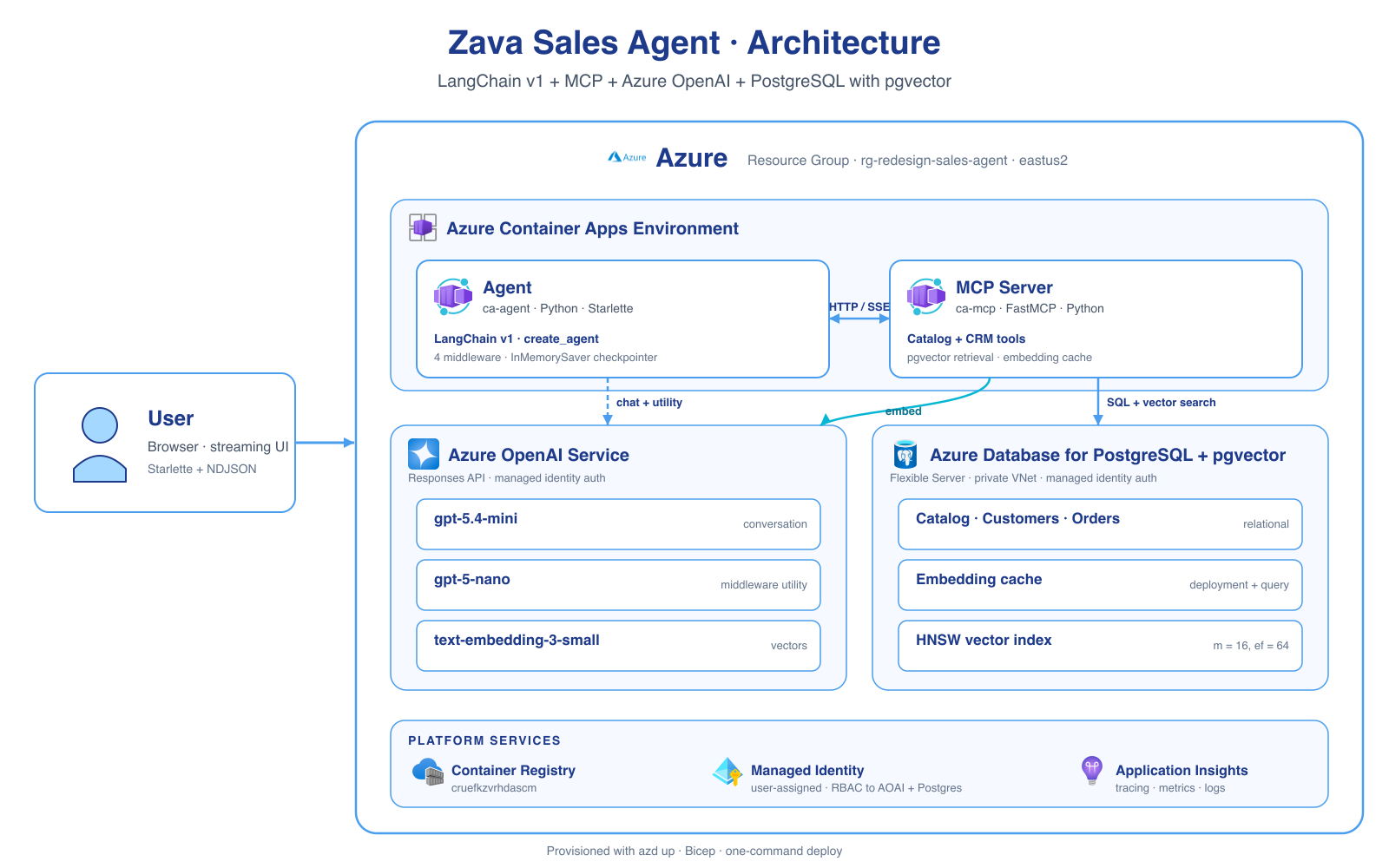
The agent is the only public-facing service. The MCP server is reachable only from inside the Container Apps environment. All Azure access uses a user-assigned managed identity with RBAC to Azure OpenAI and PostgreSQL.
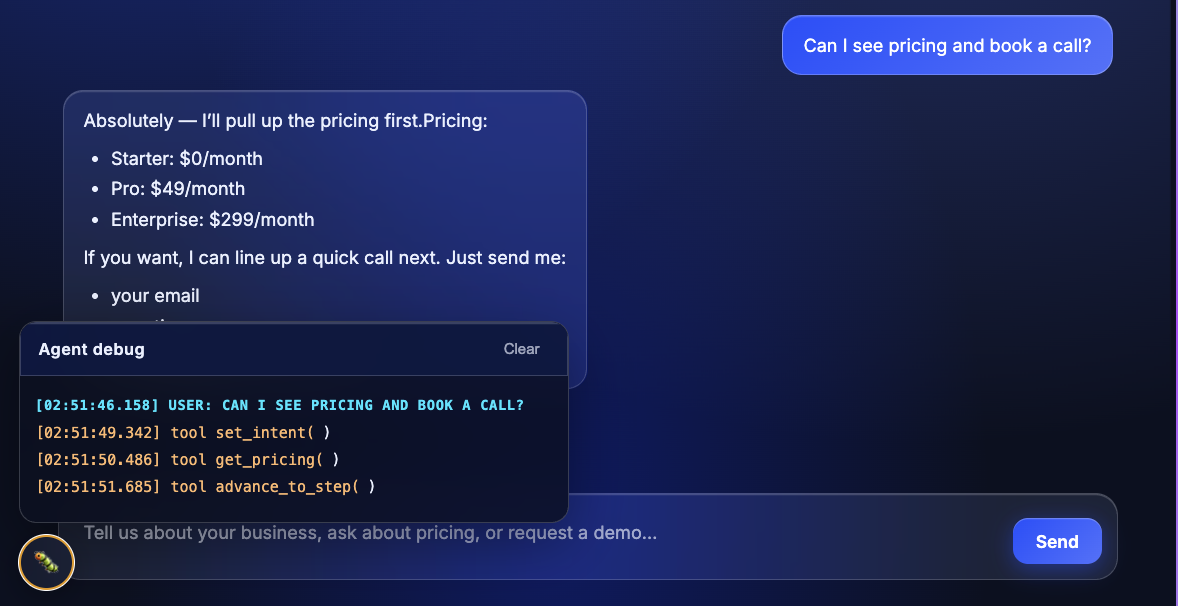
Each step is a small system prompt plus a filtered tool subset. The agent moves between steps by calling state-mutating tools (set_intent, advance_to_step, back_to_greet, escalate_to_ae):

The state machine lives in agent/app/middleware/steps.py; the per-step prompts are plain text in agent/app/prompts/.
azd).The fastest path is to open the repo in GitHub Codespaces — every tool above is preinstalled.
Deploy the app to Azure:
az login
azd auth login
azd up
azd up provisions Azure OpenAI (with three model deployments: gpt-5.4-mini for the main agent, gpt-5-nano for middleware utilities, and text-embedding-3-small for vector search), a Postgres Flexible Server with pgvector, a Container Apps environment, and the two container images. After the build finishes a postprovision hook seeds the database with the Zava DIY catalogue (~424 products with pre-computed embeddings) and the sales knowledge base (case studies, pricing plans, KB articles).
Estimated time: ~10–15 minutes end-to-end on a fresh subscription. Postgres flexible-server creation is the slowest single step (~5–7 minutes); the model deployments, container builds, and seeding fill the rest.
eastus2. Override with azd env set AZURE_LOCATION <region> before azd up. The gpt-5.4-mini and gpt-5-nano deployments need a region that has both available (e.g. eastus2, swedencentral).azd hooks run postprovision.azd up builds two container images with uv. Subsequent azd deploy <service> rebuilds for a single service take ~30–60 seconds.When it finishes you'll see something like:
🚀 Your LangChain Agent is Ready!
🌐 Web chat: https://ca-agent-<id>.<region>.azurecontainerapps.io/
Health: https://ca-agent-<id>.<region>.azurecontainerapps.io/api/health
MCP Server: https://ca-mcp-<id>.<region>.azurecontainerapps.io/mcp
Open the web chat URL and try:
To remove every resource later, run azd down.
.
├── agent/ # Public-facing chat service
│ ├── app/
│ │ ├── agent.py # build_models + build_agent (4-middleware chain)
│ │ ├── main.py # Starlette app, NDJSON streaming /api/chat
│ │ ├── streaming.py # Stream-chunk parser (text / tools / images / citations)
│ │ ├── state.py # SalesState (BANT fields + funnel step)
│ │ ├── middleware/
│ │ │ ├── refine.py # Pronoun-resolution rewrite via nano model
│ │ │ ├── steps.py # STEP_CONFIG: per-step prompt + tool subset
│ │ │ └── validate.py # Groundedness check on educate/objection answers
│ │ ├── tools/
│ │ │ └── workflow.py # set_intent, update_lead_profile, escalate_to_ae, …
│ │ └── prompts/ # 6 step prompts (greet, qualify, educate, objection, book, handoff_to_ae)
│ └── static/ # Single-page chat UI
├── mcp/
│ └── app.py # 9 MCP tools over Postgres + pgvector + cached embeddings
├── data/
│ ├── generate_database.py # Seeds the products / orders core schema
│ └── generate_sales_kb.py # Seeds pricing plans, KB articles, case studies (with embeddings)
├── infra/ # Bicep templates and parameters used by `azd up`
└── azure.yaml # azd service definitions and hooks
agent/app/agent.py builds the agent at startup inside a Starlette lifespan hook so the MCP connection, OpenAI credentials, and middleware closures are reused across requests:
main = ChatOpenAI(model="gpt-5.4-mini", use_responses_api=True, ...)
nano = ChatOpenAI(model="gpt-5-nano", use_responses_api=True, tags=["nano-utility"])
refine_query = make_refine_query(nano)
validate_response = make_validate_response(nano)
summariser = SummarizationMiddleware(model=nano, max_tokens_before_summary=4000)
agent = create_agent(
model=main,
tools=LOCAL_TOOLS + mcp_tools,
state_schema=SalesState,
middleware=[refine_query, apply_step_config, validate_response, summariser],
checkpointer=InMemorySaver(),
)
Things worth noting:
gpt-5-mini only runs the user-facing turn; pronoun-resolution, groundedness checks, and summarisation use the cheap gpt-5-nano. Every nano call is tagged with nano-utility so the chat UI can suppress its tokens from the visible bubble.apply_step_config is the heart of the funnel. On every model call it reads state["current_step"], swaps in that step's system prompt, and filters request.tools down to the tools the step actually allows. The model can only call what the step exposes.validate_response runs in educate and objection only. It looks for [doc-id] citations in the assistant's answer and rewrites ungrounded answers to ask the user whether to escalate to a human AE — instead of silently hallucinating pricing or case studies.use_responses_api=True opts into Azure OpenAI's Responses API, which lets the model call hosted tools like code_interpreter directly. api_key=token_provider is a callable that returns a fresh Entra ID bearer token, so there are no API keys anywhere.mcp/app.py uses FastMCP to expose nine read-only tools to the agent. Each tool corresponds to something a step prompt actually asks for:
| Tool | Step that uses it | Purpose |
|---|---|---|
get_current_utc_date | any | Anchors relative dates like "next Tuesday". |
get_table_schemas | analytics escape hatch | Column definitions for the retail schema. |
execute_sales_query | analytics escape hatch | Read-only ad-hoc SQL. Defence-in-depth: read-only Postgres role + SQL deny-list. |
semantic_search_products | educate | pgvector cosine search over product descriptions. |
get_product_details | educate | Full record for one product_id. |
search_case_studies | educate, objection | Embedded customer stories, optionally filtered by industry / team size. |
search_kb_articles | educate, objection | Embedded FAQ / how-Zava-works articles. |
get_pricing | educate, objection | Pricing plan(s) with a [plan-id] citation. |
compare_plans | objection | Side-by-side feature/price comparison. |
Every embedding lookup goes through an in-process LRU cache keyed on (deployment_name, query_text) — so repeated "do you have customers like us?"-style queries inside a session are free. The deployment name is part of the key so swapping models invalidates the cache automatically.
The agent talks to this server over the streamable_http MCP transport — no shared library, just HTTP. That's what makes it easy to swap the MCP server out for one written in any other language.
Every cross-service hop uses Managed Identity:
azdinfra/main.bicep provisions everything in a single deployment:
pgvector enabled and Entra ID auth on.agent and mcp-server).azure.yaml declares the two services, points them at their Dockerfiles, and registers a postprovision hook that creates the retail schema, loads the seed JSON files, and regenerates embeddings against whatever embedding model was actually deployed.
You have two options. Both assume you've run azd up at least once so Azure OpenAI exists.
# Pull the deployed environment values
azd env get-values > .env.local
echo "MCP_SERVER_URL=http://localhost:8000" >> .env.local
# Terminal 1 — MCP server
cd mcp && source ../.env.local && python app.py
# Terminal 2 — agent
cd agent && source ../.env.local && PORT=8001 python app.py
# Open http://localhost:8001
This runs both Python services on your machine but uses the cloud Postgres and Azure OpenAI deployments.
docker compose up -d # local Postgres + pgvector
cp .env.example .env.local # add your Azure OpenAI endpoint
cd data && source ../.env.local && \
python generate_database.py && \
python generate_sales_kb.py && \
python regenerate_embeddings.py # match embeddings to your deployment
# Then start mcp/ and agent/ as in Option 1
VS Code tasks (Cmd/Ctrl+Shift+P → Tasks: Run Task) are pre-configured for Start MCP Server, Start Agent, Start PostgreSQL (Docker), and Initialize Database.
Add a function to mcp/app.py and decorate it. The agent will pick it up on the next start, but the tool will only be visible inside steps that whitelist its name in agent/app/middleware/steps.py:
# mcp/app.py
@mcp.tool(annotations={"title": "Top Categories", "readOnlyHint": True})
async def top_categories(limit: int = 5, ctx: Context = None) -> str:
"""Return the top-selling product categories."""
...
# agent/app/middleware/steps.py
STEP_CONFIG["educate"]["tools"].add("top_categories")
Edit infra/main.parameters.json:
{ "openAiModelName": { "value": "gpt-5-mini" } }
Use a model that supports the Responses API. Note that not every model supports every hosted tool — check the Azure OpenAI model matrix.
Each funnel step is a separate prompt file under agent/app/prompts/. To change how the agent qualifies leads, edit qualify.txt. To change which tools that step is allowed to call, edit the corresponding entry in agent/app/middleware/steps.py. Redeploy with azd deploy agent.
The book step currently calls propose_meeting_times (text-only) and hands the actual calendar booking to the AE on escalation. The natural next step is to wire Microsoft Work IQ MCP servers (mcp_CalendarServer, mcp_TeamsServer, mcp_MailTools) as a second MultiServerMCPClient entry, so the agent can directly book meetings, pull recent emails about a lead, and check Teams discussions. Work IQ uses delegated OAuth + a Microsoft 365 Copilot license, so the deployment story will need an MSAL.js sign-in on the chat UI to forward a per-request user bearer to the agent.
azd monitor # opens Application Insights
az containerapp logs show -n <agent-name> -g <rg-name> --follow # tail logs
Application Insights captures every request to /api/chat, every MCP tool call, and every Azure OpenAI request, with end-to-end traces.
azd down
This deletes the resource group and every resource provisioned by azd up.
langchain-mcp-adaptersThis project welcomes contributions. Most contributions require you to agree to a Contributor License Agreement; see https://cla.opensource.microsoft.com.
MIT — see LICENSE.
Questions? Open an issue on GitHub or read SUPPORT.md.
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows