

Are you the author? Sign in to claim
Audit your Claude CLI history. Visualize, browse, edit -- all with one command, all local, no auth
A local, offline web UI for auditing, pruning, and cleaning the conversation history your LLM CLI has written to disk. Currently supports Claude Code; the architecture accommodates other providers (Codex, Gemini) but only Claude is implemented today.
Local only. No API key. No auth. No outbound network. Never invokes claude. Reads and rewrites ~/.claude/projects/*.jsonl on your machine, nothing else.
Status: alpha. Active development, fast-moving surface. APIs, JSONL marker formats, sidecar layouts, and word-list semantics all change without notice between commits. Pin a version if you depend on any of it. Bug reports and pull requests welcome; expect churn.
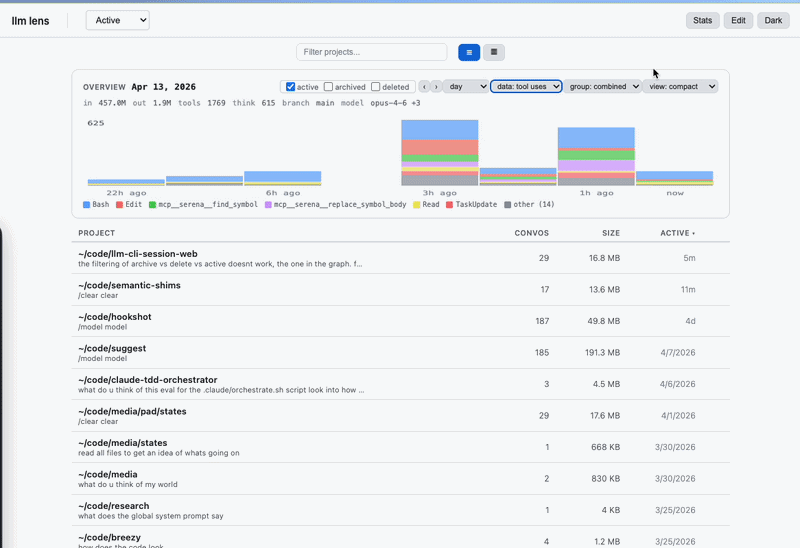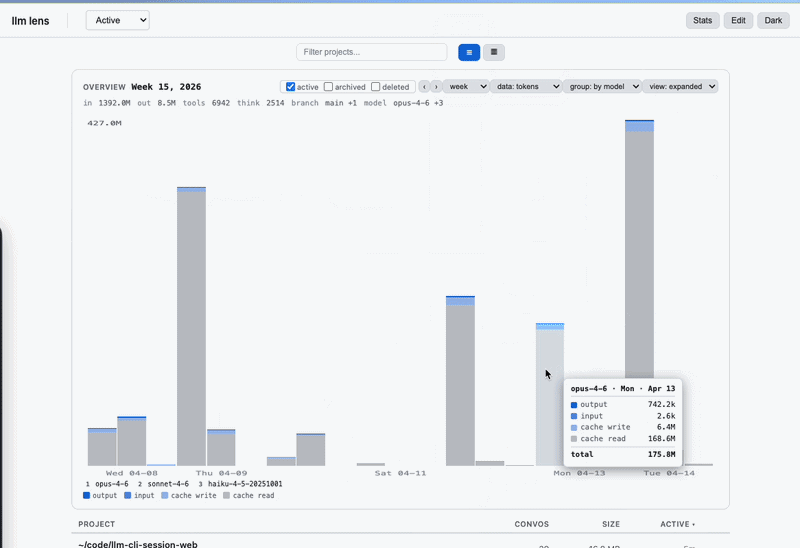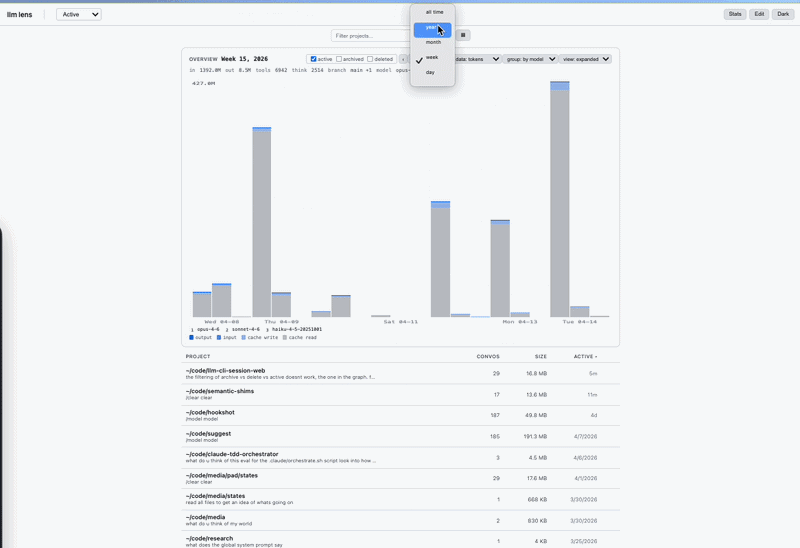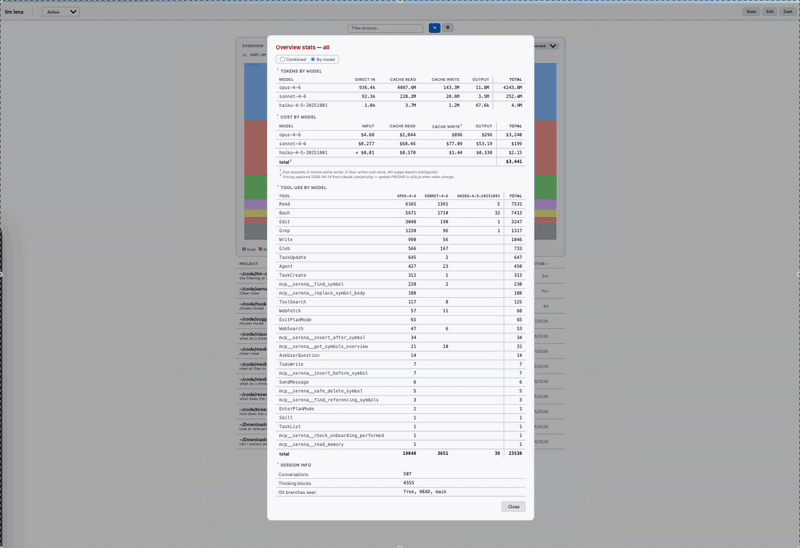
Token counts and USD costs come from the actual message.usage fields Anthropic returned for each turn — not estimates. Per-model breakdowns, per-project rollups, per-day/week/month buckets. The overview chart shows where your money went and which sessions were expensive. Pricing table in utils.js (captured from claude.com/pricing on 2026-04-14; update when rates change).
/resume cheaperThis is the lever that's easy to miss. Anything you remove from a conversation shrinks what Claude Code sends as context the next time you /resume it. Less context sent → fewer input tokens billed per turn going forward. The editing tools aren't just cleanup; they're direct downstream cost reduction:
Edit — rewrite a prose message's text in place; usage, UUIDs, and the resume chain stay intact. For fine-tuned customization. Prose-only: tool/thinking blocks are locked.
Redact — redact a message's text to .. Original usage is preserved (historical accuracy), but on resume the redacted content is what gets sent.
Normalize whitespace — collapse runs of spaces/tabs and 3+ newlines.
Strip verbosity. Doesn't change agent behavior — just reclaims tokens and sharpens meaning. Default list is conservative (obviousness signalers like "obviously", "clearly", "of course", plus meta-commentary phrases like "that's a great question", "at the end of the day"). Add sincerity markers, intensifiers, or hedges via Curate word lists if you want them gone too. Test for any candidate: remove it and see if the sentence loses meaning. If not, it's filler.
Strip priming language. Emotionally charged words and sycophancy in prior turns degrade the next turn's output — see Mulder's "I ran 1950 experiments" and a community replication on r/ClaudeAI for the evidence base. Two sub-lists stripped in one pass: swears (word-bounded, with a * stem syntax for safe conjugations — fuck* catches fuck/fucks/fucker/fucking; bare ass stays exact so assistant survives) and drift phrases (sycophancy / meta-commentary like "You're absolutely right!", "Let me think step by step." — matched exactly, case-insensitive). Two optional checkboxes in the curation modal extend the transform: lowercase user-role text (capslock-rant reduction) and collapse aggressive-repeat punctuation (!!! / ??? / ..... → single marks; preserves ... ellipsis; fence-aware). Both off by default.
Whitelist. A single global list at ~/.cache/llm-lens/word_lists.json honored by every remove-* transform — any trigger entry containing a whitelisted phrase (case-insensitive substring) is skipped at match time. Ships with a curated seed of SWE / tool / code terms (benchmark, claude, kubernetes, etc.); edit in the same modal.
All curated lists live at ~/.cache/llm-lens/word_lists.json and are editable in-app.
Preview before apply — bulk and per-message transforms (redact, normalize, verbosity / priming cleanup) route through a review modal by default: diff per message with +N/-M deltas, uncheck any row you don't want, then Apply selected. Toggle from the transform menu or from inside the modal.
Extract a pruned subset into a new conversation, leaving the original untouched.
Export — pull selected turns out as plain text or JSONL (choose which fields via JSONL fields… in the Export/Extract menu), or download the entire raw .jsonl for an external pipeline (fine-tuning, evals, diffing). Raw download is verbatim and preserves fields the parser drops (parentUuid, sessionId, message.id, toolUseResult, etc.).
Each conversation card shows a ctx 120k (60%) badge, and the conversations table has a sortable Ctx column. It shows how close Claude Code's auto-compaction will fire. Sort descending to surface sessions near the window; those are the ones worth pruning before /compact swaps your working memory for a summary. Denominator is 200k by default, promotes to 1M if any session in your cache has exceeded 200k (signal you're on the 1M plan); override with the LLM_LENS_CONTEXT_WINDOW env var.
Deletes don't vanish from your accounting. Per-conversation deleted_delta tombstones are stored in the sidecar cache so project- and overview-level rollups still reflect what you actually spent. Duplicating a conversation writes a sidecar recording the shared-prefix stats so the copy doesn't double-count against the parent while both exist.
Every Bash tool_use block is parsed for the underlying command name and counted: grep × 42, git × 31, sed × 8. Wrappers like sudo, env FOO=1, and bash -c '...' are stripped (the inner script is what counts); pipelines attribute to the first command. The per-conversation stats modal has a Bash commands section with the breakdown.
In the Messages view, Bash badges expand inline to show the actual command — truncated preview by default, click show full for the whole thing. Strings that look like API keys, GitHub/Slack/AWS/OpenAI/Anthropic tokens, Bearer headers, *_KEY=/*_SECRET=/*_PASSWORD= env assignments, or URLs with embedded passwords are masked as [sensitive] and require a click to reveal — safer to screenshot or share-screen with this on.
A whitespace-rendering toggle (· for spaces, → for tabs) on the Messages view, useful when tracking down stray characters in redacted/normalized text or comparing what the agent wrote to what you expected. Off by default; off doesn't affect on-disk content.
Claude Code writes a lot of sidecar metadata alongside each turn that it doesn't need on /resume — duplicate normalizedMessages blobs, oversized tool outputs, multi-page Bash stdouts, and occasionally huge thinking-block transcripts. Debloat trims them in place without touching anything that counts.
Select convos in the conversations view, click the split-button ▾ → Debloat N…. The modal opens instantly with one row per selected convo in a live Scanning… state; scans run per-convo in parallel and each row patches in place when done, showing exact reclaim (not an estimate — the count comes from the same rewrite engine the apply uses). Total reclaim in the header updates as rows resolve; the confirm button stays disabled with a Scanning… label until the last row lands, then flips to Debloat N.
Rules (ported from brtkwr.com/posts/2026-01-22-pruning-claude-code-conversation-history, minus the agent_progress rule — its .data.message target carries real subagent invocation content in this project's data shape, deferred as future opt-in):
normalizedMessages wherever it appears (safe no-op when absent)toolUseResult >10KB → replaced with a compact marker preserving the original byte counttype preserved so thinking_count stays correcttoolUseResult.stdout >1000 chars → truncated to first 1000 chars + marker; sibling fields (exitCode, stderr, interrupted) left alonetool_result blocks inside message.content with stringified length >10KB → content replaced with a marker string; type and tool_use_id preserved so has_tool_result, resume-chain linkage, and tool_use↔tool_result pairing all surviveEvery tracked stat survives. Each rewrite is verified against its own pre-debloat stats — if any invariant key changes (tokens, cost, tool counts, thinking counts, bash commands, slash commands, per-model breakdowns), the file is restored byte-for-byte and the apply reports a failure. tool_use blocks — including Bash commands like sed -i … — are never touched, since commands and tool_uses counters read from them.
Tombstone on the card. After debloat, the conversation card grows a debloated · 847 MB freed pill, backed by a debloat_delta sidecar entry keyed on (filepath, mtime, size) so it self-invalidates if the file changes again. Token/cost rollups continue to report pre-debloat values because usage is preserved — the badge is purely an additive disk-space marker.
Lossy. Truncated content cannot be recovered. Use Duplicate or Download raw convo first if you want an off-tool backup. Same /resume-chain caveats as Redact and Delete.
Each project gets up to 5 colored tags with custom labels you set yourself (e.g. bug-fix, spike, needs-review). Tags are project-scoped — different projects keep independent label sets — and stored in ~/.cache/llm-lens/tags.json, separate from sessions.json so they survive cache rebuilds. Click a tag in the bar above the conversation list to filter by it; the overview chart, summary stats, and Stats modal all re-aggregate to just the tagged subset, so questions like "how much did my bug-fix work cost this month?" are one click away.
Tagging itself is gated behind the Edit button, alongside the existing message-level edit mode:
Heavy tools, Thinking, Expensive, and Edited (any conversation that's had a message redacted or deleted). Each has a live slider; matching conversations highlight as you drag. Combined with the assign popup, this is "tag every conversation with >50 tool uses as heavy" in three clicks.Tags persist across archive/unarchive (keyed by conversation ID, not file path) and clean up automatically when a conversation or project is deleted.
Open the Overview chart at the top of Projects or Conversations. Range → Month, Mode → Tokens or Cost. Click into the heavy days. Drill from Projects → Conversations → Messages. Archive stuff you're done with; delete stuff you'll never need; leave the rest.
sessionId and rewritten message UUIDs so /resume doesn't collide with the parent)./resume cleanly — that's a separate claude --resume <id> from the terminal, and undocumented invariants mean a pass today doesn't guarantee a pass tomorrow.Select the messages to redact. Redact. The chain, UUIDs, and token counts stay intact — only the visible text becomes .. Safe to paste the file into a bug report or share the session ID.
Open the Messages view. Edit mode → Select all → split-button ▾ → Remove verbosity or Remove priming language. Verbosity is about token cost and clarity. Priming combines two sub-lists (swears + drift phrases) and targets agent behavior — emotional priming and sycophancy-induced drift both degrade the next turn's output. Curate either list via Curate word lists… (stored at ~/.cache/llm-lens/word_lists.json).
Open a conversation's stats modal → Bash commands section. See the frequency-ranked list of what was run. For specific calls, scroll the Messages view: each Bash badge is expandable inline and shows the full command (with sensitive-pattern masking on by default).
When an agent delegates work via the Task tool, the parent convo only sees a tool_use/tool_result pair — the subagent's real back-and-forth (its own prompts, tool calls, responses) lives in a separate file. In the Messages view, the Task badge gets a → <agent-name> link; click it to open that subagent's full transcript as its own conversation view (breadcrumb: parent → agent). Useful when the parent's summary hides a pile of cost or a tool call you didn't know happened. Legacy inline sidechains show the same link on the main message they branched from, tagged legacy.
In the conversations view, switch to Edit mode. Sort by size descending to surface the heaviest files. Check a batch, click the split-button ▾ on Archive N, pick Debloat N…. Review the per-convo scan rows (each shows exact before/after/reclaim); rows with nothing reclaimable are shown but excluded from the apply list. Confirm. Each file rewrites with invariant verification — any that fail a stats check are restored byte-for-byte and reported in the toast. Card footer now shows a debloated · N freed pill on each one.
Open the Messages view → Edit → select the turns you want. Click Export/Extract ▾ → JSONL fields… first if you need non-default fields (model, usage, timestamp, etc.; role + content are always on), then use Download JSONL or Copy JSONL to clipboard. For a verbatim dump that round-trips back into Claude Code, use Download raw convo in the header — preserves parentUuid chain, sessionId, message.id, tool block linkage, and all the other fields the parser flattens out.
Click Edit on the project view. Click an empty tag slot, name it (e.g. bug-fix). Use the Smart-select presets to find matching conversations — Edited for ones you've pruned, Heavy tools with the slider for shell-heavy sessions, etc. Click "Tag N matching" → pick the tag. Exit edit mode. Now click that tag pill in the bar: the conversation list, the overview chart, and the per-bucket totals all narrow to just those conversations.
This tool is non-destructive by default. Every editing action has a preserving alternative:
| You want to | Non-destructive option |
|---|---|
| Hide a conversation | Archive (moves to ~/.cache/llm-lens/archive/, reversible) |
| Remove messages | Extract to new convo (leaves original intact) |
| Edit a message | Redact text, keeping usage and chain |
| Apply a transform (redact / normalize / priming / verbosity) | Preview first — review the diff per message, uncheck any you don't want, Apply selected |
| Try a risky edit | Duplicate first, edit the copy |
| Preserve a conversation off-tool | Download raw convo (verbatim .jsonl, re-importable) |
Shrink a huge .jsonl on disk | Duplicate, then Debloat the copy (or Download raw convo first for an off-tool backup — Debloat is lossy) |
Destructive actions (delete-convo, delete-message, in-place normalize/redact, debloat) rewrite files on disk. Claude Code's /resume replay semantics aren't publicly documented, so any in-place edit is best-effort — the tool re-links parentUuid chains and strips orphan tool_use/tool_result blocks to stay resume-safe, but we can't guarantee it against invariants we can't see. If resume-ability of a specific conversation matters to you, duplicate before editing.
Deleting a whole conversation or project is low-risk — that's just file removal, no chain-surgery.
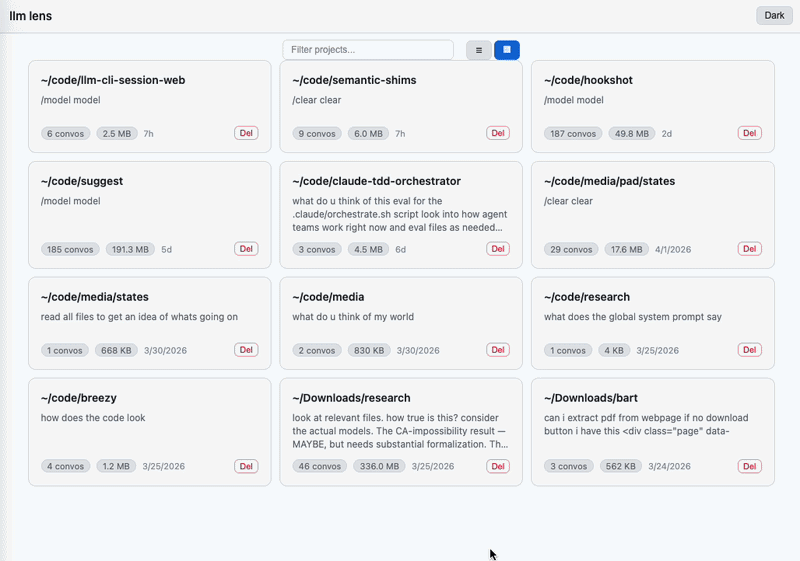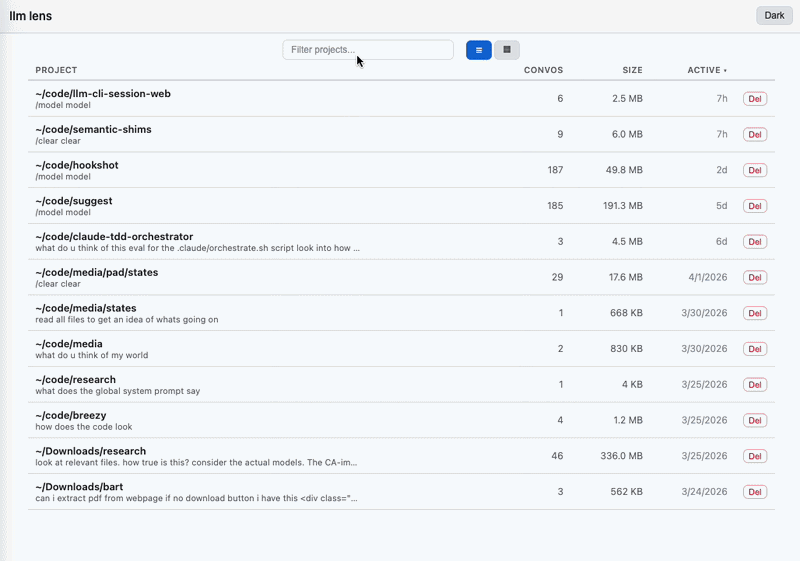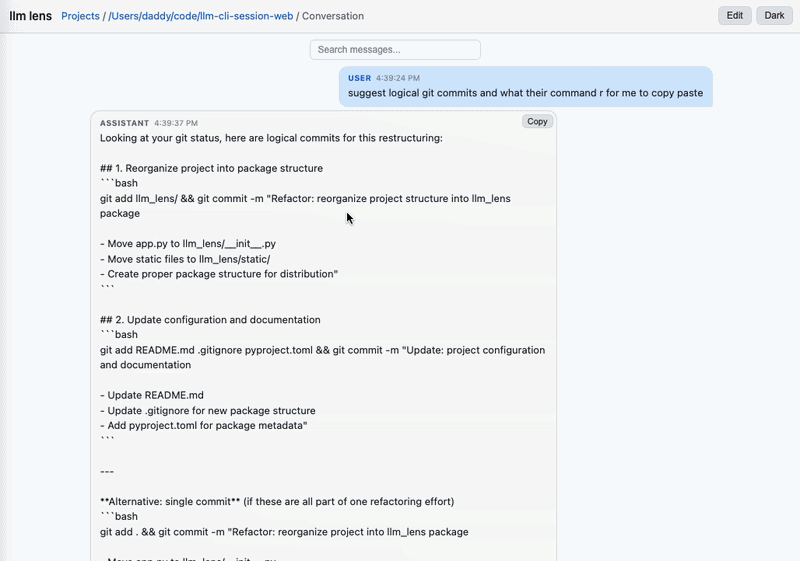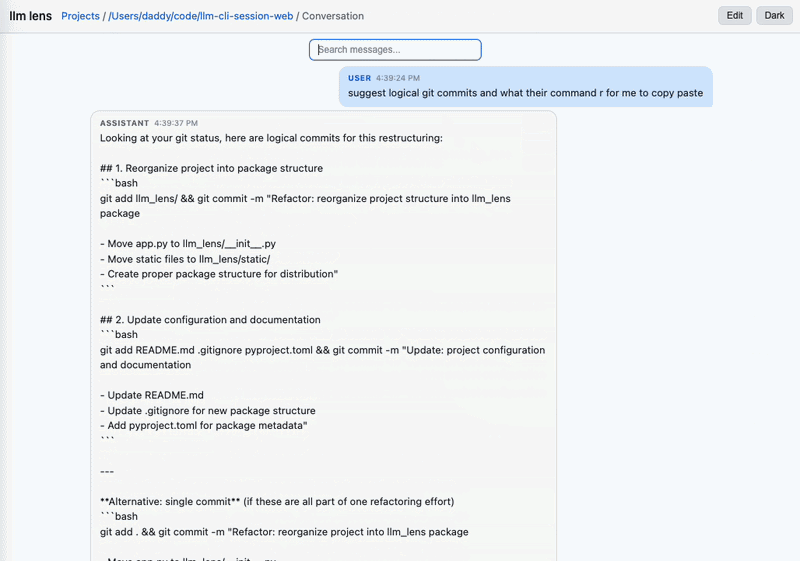
Three views, each paginated + sortable + searchable:
~/.claude/projects/* subdirectory. Convo count, total size, preview, aggregate stats..jsonl sessions in a project. Toggle active/archived. Card view shows inline stats plus a debloated · N freed pill on files that have been through Debloat. Delete/archive/duplicate per-row. Edit-mode bulk toolbar collapses Archive/Debloat/Delete into one severity-ranked split button (Archive is the default face; arrow opens a menu with all three).→ <agent-name> link that drills into the subagent's own transcript without leaving the parent convo's context. Thinking blocks collapsed by default. Toggle to render whitespace (· for spaces, → for tabs) when you care about exact text. Edit mode surfaces per-message Copy / Redact (split-button with transform variants: redact / normalize whitespace / remove verbosity / remove priming language / remove custom filter) / Delete, a Download raw convo button in the header (whole-file verbatim download), and a bulk action bar with select-all when messages are selected: Export/Extract ▾ menu (Copy plain / Copy JSONL / Download JSONL / Extract to new conversation / JSONL fields…), Redact ▾ split, and Delete.Overview chart on Projects and Conversations views: activity over day/week/month buckets, with modes for message count, tokens, or USD cost. Aggregate totals and cost estimates for the selected window.
Requirements: Python 3.8+, a browser, Claude Code installed at least once (so ~/.claude/projects/ exists).
pipx install llm-lens-web # or: uv tool install llm-lens-web
llm-lens-web # opens http://localhost:5111
Custom port: llm-lens-web 8080. The server binds 0.0.0.0 — reachable on your LAN. There's no auth, so don't run it on an untrusted network.
Upgrade / uninstall: pipx upgrade llm-lens-web / pipx uninstall llm-lens-web (substitute uv tool if that's what you used).
pyproject.toml Package metadata
llm_lens/
__init__.py Flask backend: REST API, static serving, main()
peek_cache.py Persistent sidecar cache (token stats, titles, tombstones)
tag_store.py Per-project tag labels + assignments (separate sidecar)
debloat.py Lossy disk-space reclaim with stats-invariant guardrails
static/
index.html SPA shell
css/styles.css All styles; dark/light via CSS vars
js/
main.js Routing + delegated click handler
state.js Shared state + localStorage
api.js Fetch wrappers
router.js Hash router
toolbar.js Toolbar helper
modal.js Confirm dialogs
utils.js Formatting + PRICING table
views/
projects.js
conversations.js
messages.js
No build step. Plain ES modules.
git clone <repo>
cd llm-cli-session-web
pip install -e .
LLM_LENS_DEBUG=1 llm-lens-web
-e + LLM_LENS_DEBUG=1 gives edit-reload.
CLAUDE_PROJECTS_DIR = ~/.claude/projects/ is hardcoded. Each subdirectory is a project; each .jsonl is a conversation. Main provider coupling.~/.cache/llm-lens/sessions.json, keyed on (filepath, mtime, size) so entries auto-invalidate. Debounced atomic writes; in-process @lru_cache in front for hot reads.deleted_delta entry preserving final stats so project/overview rollups stay honest. Path-reuse handled by keying on (pre-delete mtime, size). Edit / redact ops contribute a messages_edited counter to the same delta so the Edited smart-select preset works without re-reading files. Debloat writes its own additive sidecar entry, debloat_delta: {bytes_reclaimed, counts, at}. Usage-derived rollups are untouched (tokens / cost stay at pre-debloat values); the delta only powers the debloated · N freed card badge.debloat.py applies five rules from brtkwr's pruning post minus agent_progress (that rule's .data.message target carries real subagent content in this project's data shape — deferred as future opt-in): drop normalizedMessages, replace top-level toolUseResult >10KB with a marker dict, truncate thinking >20KB to first 2KB, truncate toolUseResult.stdout >1KB to first 1KB, and replace oversized inline tool_result.content with a marker (preserving type + tool_use_id for resume-chain). Every rewrite is atomic (tempfile + os.replace) with a full-byte backup and a _verify_stats_equal check against the aggregator's own stat dict; failure restores byte-for-byte and raises StatsInvariantError. scan_convo(path) returns the exact reclaim (not an estimate) by running the same rule engine without writing.~/.cache/llm-lens/tags.json — separate from sessions.json so a peek_cache.hard_clear() doesn't wipe them. Same lock + debounce-flush pattern as peek_cache, plus an atexit.register(flush) so abrupt shutdowns still persist. Per-folder shape: {labels: [{name, color}, ...], assignments: {convo_id: [tag_idx, ...]}}. Overview/stats endpoints accept an optional tags filter that intersects against assignments server-side; tombstones are skipped under tag filtering since deleted convos no longer have assignments.rename to ~/.cache/llm-lens/archive/<folder>/, mtime preserved so time-bucketed stats don't shift.sessionId/uuid/parentUuid inside so /resume doesn't collide with the parent. Sidecar <new-id>.dup.json records the shared-prefix stats so aggregation subtracts them while the parent still exists.~/.cache/llm-lens/word_lists.json ({swears, filler, verbosity, custom_filter, whitelist, lowercase_user_text, abbreviations, apply_abbreviations, custom_filter_enabled, collapse_punct_repeats}). Empty list = opt-out (not "fall back to defaults"). Defaults shipped in code and exposed via GET /api/word-lists/defaults. swears + filler back priming cleanup; verbosity targets token cost. whitelist is a global never-redact honored by every remove-* transform via case-insensitive substring containment. custom_filter is a user-populated list for convo-specific boilerplate; custom_filter_enabled (bool, default off) controls whether Remove custom filter appears in the split-button menu. lowercase_user_text (bool) toggles a scoped pre-lowercase on remove_priming for user-role messages; collapse_punct_repeats (bool) flattens !!! / ??? / ..... on remove_priming (fence-aware, preserves ... ellipsis). abbreviations is a list of {from, to} pairs applied after remove_verbosity when apply_abbreviations is on; defaults are empirically verified against tiktoken o200k_base and split into de-abbreviations (i.e.→ie, w/→with) and token-neutral disk-savers (you→u, please→pls).~/.cache/llm-lens/download_fields.json. Keys cover every field the exporter can emit (uuid, role, content, timestamp, commands, model, usage); role and content are always true regardless of payload. The modal's checkboxes render them disabled and the server re-forces them on save. For fields the parser drops (parentUuid, sessionId, message.id, toolUseResult, …), use the raw-convo download instead._extract_command_name(cmd) parses each Bash tool_use's input.command, strips wrappers (sudo, env VAR=…, bash -c '…' recurses into the inner script) and pipeline tail, returns the first real command. Aggregated per-conversation as stats.commands: {name: count}. Tool-use markers in parsed messages are now [Tool: Bash:<tool_use_id>] so the frontend can correlate a badge with the command attached to the message via the commands: [{id, command}] field.<convo_id>/subagents/agent-[<name>-]<hash>.jsonl — a sibling of the parent <convo_id>.jsonl. One file = one run. run_id is the trailing <hash>. Messages inside are wrapped in a type: "progress" envelope with the real payload at data.message; _format_entry_message unwraps it so the same rendering code handles parent and agent entries. The run's parent-side anchor is the first parentToolUseID value in the file that matches a parent tool_use block named Agent or Task — that's where the inline → <agent-name> marker attaches. Other parentToolUseID values pointing at ordinary tools (Read/Write/Edit/etc.) are audit-trail bookkeeping and are intentionally ignored for anchoring. Files with no Agent/Task-named ptu are still valid runs; they surface only in the Subagents toolbar list. Old sessions used an inline format — isSidechain: true entries in the parent file — still supported: clusters are grouped by their closest non-sidechain ancestor and surfaced with source: "inline", run id inline:<anchor_uuid>. Both formats appear in one unified agent_runs list.SECRET_PATTERNS in views/messages.js matches well-known credential shapes (Anthropic/OpenAI/GitHub/Slack/AWS/Google keys, Bearer …, *_KEY=/*_SECRET=/*_PASSWORD= env-style, URL-embedded passwords). Matches render as [sensitive] chips with the original in data-secret; revealSecret(el) swaps the chip for the raw text on click. Conservative — high-entropy strings without a known prefix won't match.unlink, rename, shutil.copy2, line-filtered rewrites. No database.| Method | Path | Description |
|---|---|---|
GET | /api/overview | Activity buckets (range, mode, group_by, offset, optional tags=0,2 when folder is set) |
GET | /api/projects | All projects + metadata |
POST | /api/projects/stats | Aggregate token stats across projects (optional tags: {folder: [idx,...]} in body) |
GET | /api/projects/:folder/conversations | Paginated conversations |
GET | /api/projects/:folder/archived | Archived conversations |
POST | /api/projects/:folder/stats | Aggregate stats for a project |
POST | /api/projects/:folder/names | Bulk custom-title fetch |
POST | /api/projects/:folder/refresh-cache | Re-scan + flush sidecar |
GET | /api/projects/:folder/conversations/:id | Paginated messages. Response also carries agent_runs: [{tool_use_id, name, source, message_count, first_ts, anchor_uuid?}] — one per subagent run spawned by the convo, usable to decorate Task badges in the UI. |
GET | /api/projects/:folder/conversations/:id/agent/:tool_use_id | Messages for a single subagent run. Same envelope as the messages endpoint, plus agent_name / parent_convo_id. |
GET | /api/projects/:folder/conversations/:id/raw | Source .jsonl as attachment (verbatim) |
GET | /api/projects/:folder/conversations/:id/stats | Stats for one conversation |
DELETE | /api/projects/:folder/conversations/:id | Delete (stats tombstoned) |
POST | /api/projects/:folder/conversations/:id/archive | Archive |
POST | /api/projects/:folder/conversations/:id/unarchive | Unarchive |
POST | /api/projects/:folder/conversations/:id/duplicate | Duplicate (rewrites IDs, writes sidecar) |
DELETE | /api/projects/:folder/conversations/:id/messages/:uuid | Delete one message |
POST | /api/projects/:folder/conversations/:id/messages/:uuid/edit | Replace a prose-only message's text in place. Body: {text}. Transforms (redact / normalize_whitespace / remove_swears / remove_filler / remove_verbosity / remove_priming / remove_custom_filter) are applied client-side from the Messages view — this endpoint just persists the result. |
POST | /api/projects/:folder/conversations/:id/extract | New convo from selected UUIDs |
POST | /api/projects/:folder/conversations/bulk-delete | Bulk delete |
POST | /api/projects/:folder/conversations/bulk-archive | Bulk archive |
POST | /api/projects/:folder/conversations/bulk-unarchive | Bulk unarchive |
POST | /api/projects/:folder/conversations/debloat-scan | Batch read-only scan ({ids} → per-id {bytes_reclaimable, counts, current_size}). Exact byte numbers, not estimates. |
POST | /api/projects/:folder/conversations/:id/debloat | Apply debloat to one convo. Stats-invariant verified; 500 + byte-for-byte restore on StatsInvariantError. |
POST | /api/projects/:folder/conversations/bulk-debloat | Apply debloat across many; one-convo failure doesn't block the rest. |
DELETE | /api/projects/:folder | Delete an entire project |
GET | /api/projects/:folder/tags | Label definitions + per-conversation assignments |
PUT | /api/projects/:folder/tags/labels | Replace label definitions (max 5; {labels: [{name, color}, ...]}) |
POST | /api/projects/:folder/tags/assign | Set tags for one conversation ({convo_id, tags: [idx,...]}) |
POST | /api/projects/:folder/tags/bulk-assign | Add or remove a single tag across many ({ids, tag, add: bool}) |
GET | /api/word-lists | Effective curated lists + global whitelist + flags ({swears, filler, verbosity, custom_filter, whitelist, lowercase_user_text, abbreviations, apply_abbreviations, custom_filter_enabled, collapse_punct_repeats}) |
POST | /api/word-lists | Persist user-curated lists (same shape) |
GET | /api/word-lists/defaults | Shipped defaults |
POST | /api/projects/:folder/conversations/:id/custom-filter/scan | N-gram frequency scan over one conversation. Body: {min_length_chars, min_count, n_min, n_max}. Excludes phrases already in custom_filter or whitelist. Returns {msg_count, candidates}. |
GET | /api/download-fields | Effective JSONL export field prefs (role/content always true) |
POST | /api/download-fields | Persist user's JSONL field selection |
All mutations invalidate the sidecar cache for affected files and return {"ok": true} on success.
__init__.py following the pattern (route → fs op → cache invalidation → JSON).actions map in main.js, implement in the relevant view, tag the HTML element with data-action="...".Claude-specific surface is small:
CLAUDE_PROJECTS_DIR — discovery path_peek_jsonl_cached / _parse_messages_cached — JSONL shape (message.role, content blocks, isSidechain, isMeta, file-history-snapshot, uuid, cwd, timestamp)_agent_runs_for_convo / _inline_agent_runs_from_parent — subagent layout (<convo_id>/subagents/agent-*.jsonl, parentToolUseID keying, the type: "progress" wrapper) plus the legacy inline-sidechain fallbackWhen adding a second provider:
Provider protocol with discover_projects(), list_conversations(), read_messages(), delete_conversation(), etc.llm_lens/providers/claude_code.py behind it.:provider to API routes and a provider selector to the frontend.[project.optional-dependencies] extras.Don't pre-build the abstraction before there's a second implementation — extract from two working ones, not from guesses.
1000+ skills curated from Anthropic, Vercel, Stripe, and other engineering teams
Design enforcement with memory — keeps your UI consistent across a project
Detects 37 AI writing patterns and rewrites text with human rhythm across 5 voice profiles
WCAG accessibility audit — automated scanning, manual review, remediation