

Are you the author? Sign in to claim
RLAnything (ICML 2026) & AutoTool (ICML 2026), DemyAgent: Open-Source RL for LLMs and Agentic Scenarios

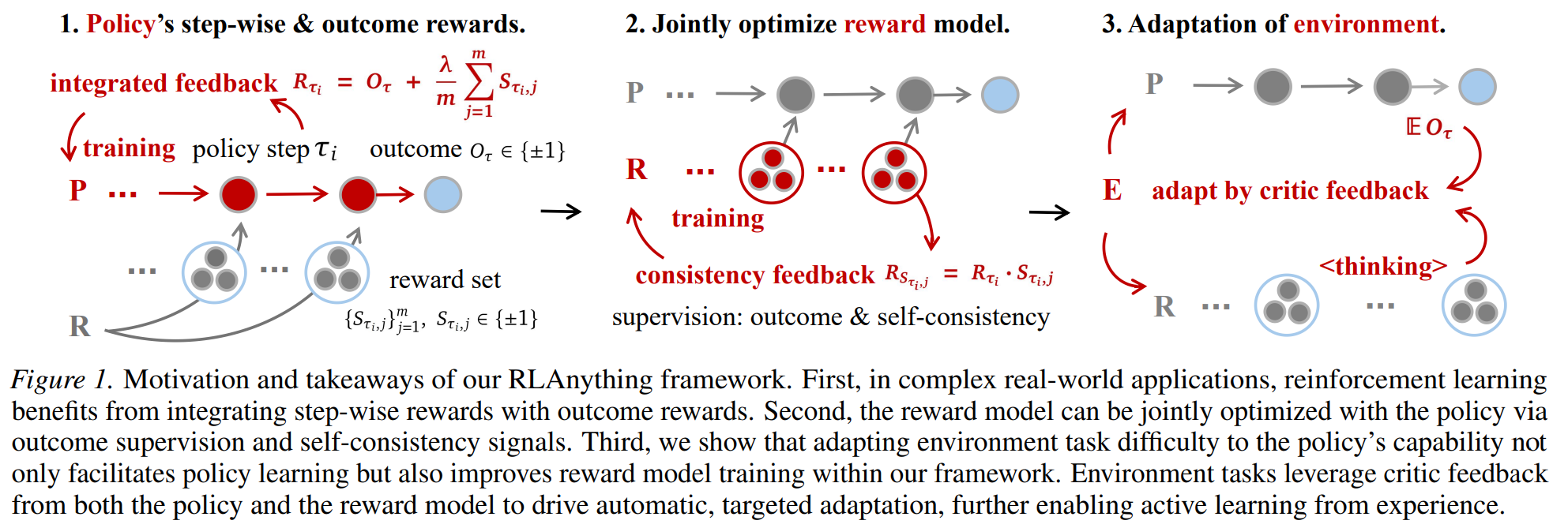 |
| An overview of our research on RLAnything. |
In this work, we propose RLAnything, a reinforcement learning framework that dynamically optimizes each component through closed-loop optimization, amplifying learning signals and strengthening the overall system:
 |
| An overview of our research on agentic RL. |
In this work, we systematically investigate three dimensions of agentic RL: data, algorithms, and reasoning modes. Our findings reveal:
We also contribute high-quality SFT and RL datasets, demonstrating that simple recipes enable even 4B models to outperform 32B models on challenging benchmarks including AIME2024/2025, GPQA-Diamond, and LiveCodeBench-v6.
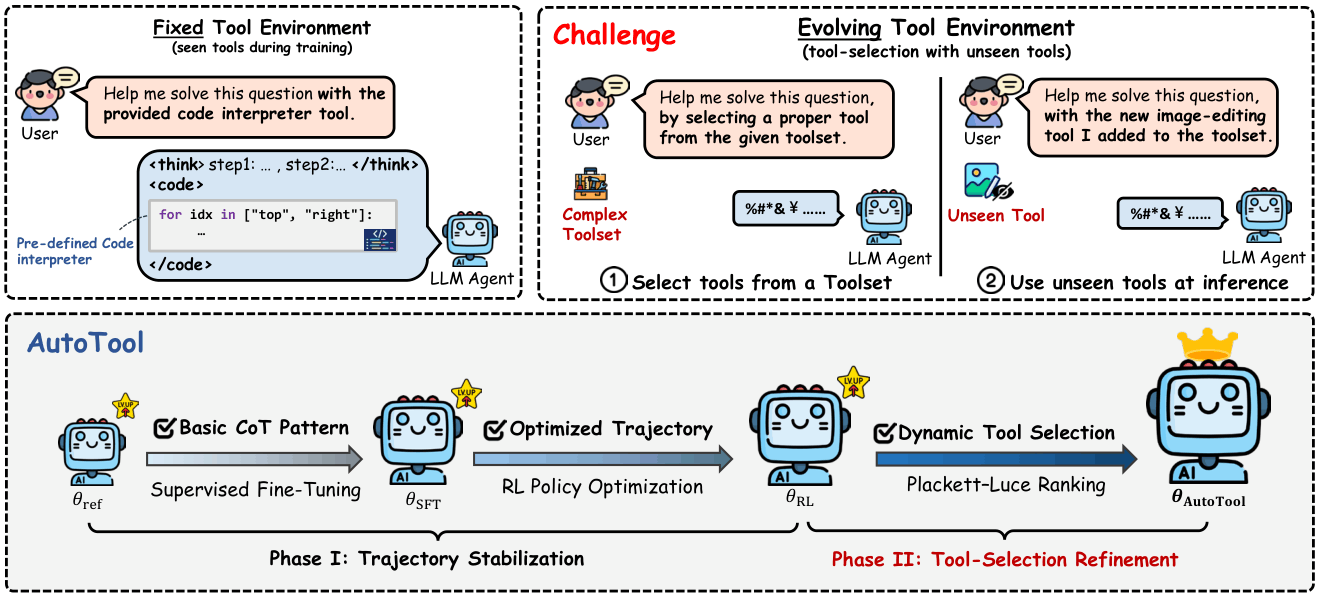 |
| An overview of our research on AutoTool. |
In this work, we move beyond the fixed-toolset assumption in agentic RL and train LLM agents with dynamic tool-selection capabilities over large, evolving toolsets:
See autotool/ for the full training framework and instructions.
| RLAnything | DemyAgent | AutoTool | |
|---|---|---|---|
| Focus | Closed-loop RL optimization | Agentic reasoning | Dynamic tool selection |
| Core Idea | Joint optimization of policy, reward model & environment | Real trajectories + exploration-friendly techniques + deliberative reasoning | Tool-selection rationales + PL-ranking refinement over evolving toolsets |
| Release | LLM/GUI/Coding Policy & Reward Model | 3K SFT + 30K RL Data, SOTA-level DemyAgent-4B | Dual-phase training code, 200K tool-use data (coming soon) |
[2026.5] 🎉 AutoTool is accepted by ICML 2026! We open-source our work AutoTool under autotool/, including:
[2026.5] 🎉 RLAnything is accepted by ICML 2026! Check out our paper, models, and blog.
[2026.2] 🦞 We release OpenClaw-RL, a new fully asynchronous RL framework built on top of Open-AgentRL, targeting personalized agentic AI trained from live conversation feedback. OpenClaw-RL introduces:
[2026.2] We fully open-source our work RLAnything, including:
[2025.10] We fully open-source our work DemyAgent, including:
DemyAgent:
RLAnything:
AutoTool: see autotool/README.md for installation, training (Phase I & II), and results
git clone https://github.com/Gen-Verse/Open-AgentRL.git
conda create -n OpenAgentRL python=3.11
conda activate OpenAgentRL
cd Open-AgentRL
bash scripts/install_vllm_sglang_mcore.sh
pip install -e .[vllm]
conda create --name rlanything python=3.10
source activate rlanything
pip install -r requirements_rlanything.txt
Before you start SFT, make sure you have downloaded the 3K Agentic SFT Data and the corresponding base models like Qwen2.5-7B-Instruct and Qwen3-4B-Instruct-2507. Configure qwen3_4b_sft.sh and qwen2_7b_sft.sh, and set the absolute paths to your model and the .parquet data files.
TRAIN_DATA: Path to the .parquet file of the SFT dataset
EVAL_DATA: Path to the evaluation data (can be set to the same as TRAIN_DATA)
MODEL_PATH: Path to your base models like Qwen2.5-7B-Instruct or Qwen3-4B-Instruct-2507
SAVE_PATH: Directory to save the SFT model checkpoints
After all configurations are set, simply run the code below to finetune Qwen3-4B-Instruct-2507:
bash recipe/demystify/qwen3_4b_sft.sh
After obtaining the SFT models, utilize the following command to merge the model:
python3 -m verl.model_merger merge --backend fsdp --local_dir xxx/global_step_465 --target_dir xxx/global_step_465/huggingface
After obtaining the SFT models (you can also directly use our provided checkpoints Qwen2.5-7B-RA-SFT and Qwen3-4B-RA-SFT), you can start Agentic RL with our GRPO-TCR recipe.
First, download our 30K Agentic RL Data and the evaluation datasets.
Then, configure the SandboxFusion environment for code execution.
There are two ways to create a sandbox:
Using either method, obtain an API endpoint (something like https://<ip-address-or-domain-name>/run_code), and configure it in recipe/demystify/sandbox_fusion_tool_config.yaml and the function check_correctness inverl/utils/reward_score/livecodebench/code_math.py.
Next, configure the Agentic RL scripts grpo_tcr_qwen2_7b.sh and grpo_tcr_qwen3_4b.sh:
.parquet file of the agentic RL dataset.parquet files of the benchmarks. You can also add more benchmarks like GPQA-Diamond in test_filesTraining Resources: We conducted our training on one $8\times \text{Tesla-A100}$ node with a batch size of 64.
After finishing the configurations, run the code below to conduct Agentic RL with the GRPO-TCR recipe:
bash recipe/demystify/grpo_tcr_qwen3_4b.sh
You can observe the training dynamics and evaluation results in Weights & Biases (wandb).
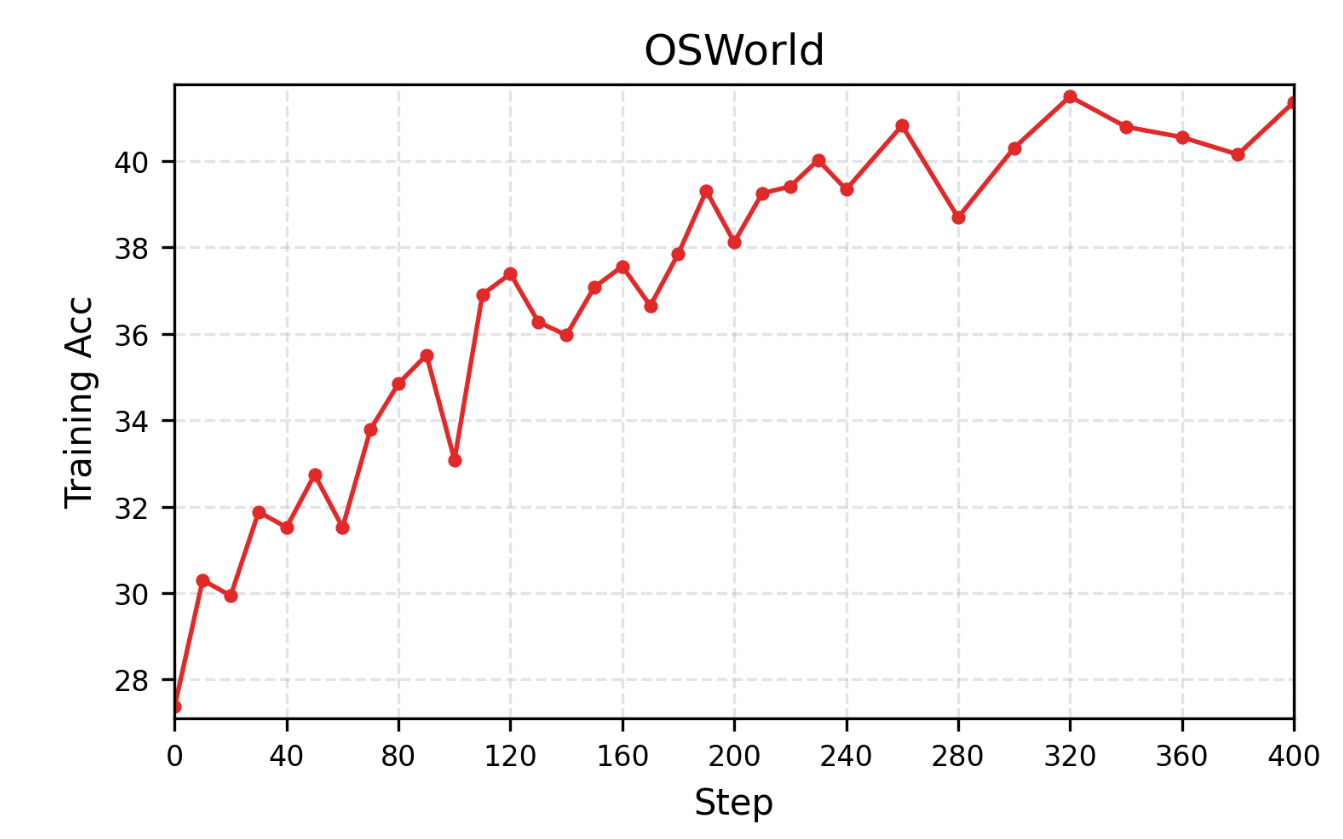
Our reinforcement learning and evaluation pipeline for OSWorld is built on a pool of virtual machines running in parallel on cloud instances. Specifically, we use Volcengine Cloud in our experiments. Before training, you need to set up the security group and VM image on Volcengine following these instructions.
Before training, you need set osworld_rl.yaml in configs. The detailed instructions are within it. To start the RLAnything training, simply
python osworld_rl.py config=configs/osworld_rl.yaml
# you need to set num_node in osworld_rl.yaml to 1 if you only use one node.
In our experiments, we train with multiple nodes:
if [[ ${MLP_ROLE_INDEX:-0} -eq 0 ]]; then
python osworld_rl.py config=configs/osworld_rl.yaml
else
exec tail -f /dev/null
fi
# directly submit this to head machine
To conduct reinforcement learning or evaluation on AlfWorld, you need to first download the AlfWorld data with the following commands (after you have pip installed the rlanything environment)
alfworld-download
Then you will have a directory that contains at least detectors, json_2.1.1, and logic. This will be the directory to save AlfWorld environment files. Our adapted environment files will be generated under alfworld_file_path/json_2.1.1/alfworld_rl/syn_train. syn_train saves accepted environment files, while temp_train saves generated files which to be validated (not accept yet).
Before training, you need set alfworld_rl.yaml in configs. The detailed instructions are within it. To start the RLAnything training, simply
python alfworld_rl.py config=configs/alfworld_rl.yaml
# you need to set num_node in alfworld_rl.yaml to 1 if you only use one node.
In our experiments, we train with multiple nodes:
if [[ ${MLP_ROLE_INDEX:-0} -eq 0 ]]; then
python alfworld_rl.py config=configs/alfworld_rl.yaml
else
exec tail -f /dev/null
fi
# directly submit this to head machine
You need to first download the training and evaluation dataset. Simply open ./data and follow the instructions to do so. Then you can start the training with
python coding_rl.py config=configs/coding_rl.yaml
# you need to set num_node in coding_rl.yaml to 1 if you only use one node.
In our experiments, we train on 4 nodes
if [[ ${MLP_ROLE_INDEX:-0} -eq 0 ]]; then
python coding_rl.py config=configs/coding_rl.yaml
else
exec tail -f /dev/null
fi
If you have already trained a model, you can refer to the following process for agentic reasoning capability evaluation. Alternatively, you can download our checkpoint from 🤗 DemyAgent-4B for direct testing.
Configure the scripts eval_qwen2_7b_aime_gpqa.sh and eval_qwen3_4b_aime_gpqa.sh. The configuration process is similar to the training setup—set the paths to your models and .parquet files of the benchmarks.
Simply run the code below to evaluate performance on AIME2024/2025 and GPQA-Diamond:
bash recipe/demystify/eval/eval_qwen3_4b_aime_gpqa.sh
You can observe the average@32/pass@32/maj@32 metrics from your wandb project.
First, run inference for the benchmark:
bash recipe/demystify/eval/eval_qwen3_4b_livecodebench.sh
Specifically, we save the validation rollout paths in VAL_SAVE_PATH. After obtaining the validation rollouts, refer to the official evaluation process for local results in LiveCodeBench.
To eval the model on OSWorld, use
python osworld_eval.py config=configs/osworld_eval.yaml
You can also evaluate with multi-nodes to accelerate.
if [[ ${MLP_ROLE_INDEX:-0} -eq 0 ]]; then
python osworld_eval.py config=configs/osworld_eval.yaml
else
exec tail -f /dev/null
fi
To eval the model on AlfWorld, use
python alfworld_eval.py config=configs/alfworld_eval.yaml
For evaluation, simply
python coding_eval.py config=configs/coding_eval.yaml
We provide the evaluation results of the agentic reasoning abilities of our models on challenging benchmarks including AIME2024/AIME2025, GPQA-Diamond, and LiveCodeBench-v6.
| MATH | Science | Code | ||
|---|---|---|---|---|
| Method | AIME2024 | AIME2025 | GPQA-Diamond | LiveCodeBench-v6 |
| Self-Contained Reasoning | ||||
| Qwen2.5-7B-Instruct | 16.7 | 10.0 | 31.3 | 15.2 |
| Qwen3-4B-Instruct-2507 | 63.3 | 47.4 | 52.0 | 35.1 |
| Qwen2.5-72B-Instruct | 18.9 | 15.0 | 49.0 | - |
| DeepSeek-V3 | 39.2 | 28.8 | 59.1 | 16.1 |
| DeepSeek-R1-Distill-32B | 70.0 | 46.7 | 59.6 | - |
| DeepSeek-R1-Zero (671B) | 71.0 | 53.5 | 59.6 | - |
| Agentic Reasoning | ||||
| Qwen2.5-7B-Instruct | 4.8 | 5.6 | 25.5 | 12.2 |
| Qwen3-4B-Instruct-2507 | 17.9 | 16.3 | 44.3 | 23.0 |
| ToRL-7B | 43.3 | 30.0 | - | - |
| ReTool-32B | 72.5 | 54.3 | - | - |
| Tool-Star-3B | 20.0 | 16.7 | - | - |
| ARPO-7B | 30.0 | 30.0 | 53.0 | 18.3 |
| rStar2-Agent-14B | 80.6 | 69.8 | 60.9 | - |
| DemyAgent-4B (Ours) | 72.6 | 70.0 | 58.5 | 26.8 |
As demonstrated in the table above, despite having only 4B parameters, DemyAgent-4B matches or even outperforms much larger models (14B/32B) across challenging benchmarks. Notably, DemyAgent-4B achieves state-of-the-art agentic reasoning performance, surpassing ReTool-32B and rStar2-Agent-14B, and even outperforming long-CoT models like DeepSeek-R1-Zero on AIME2025, which further validates the insights of our research.
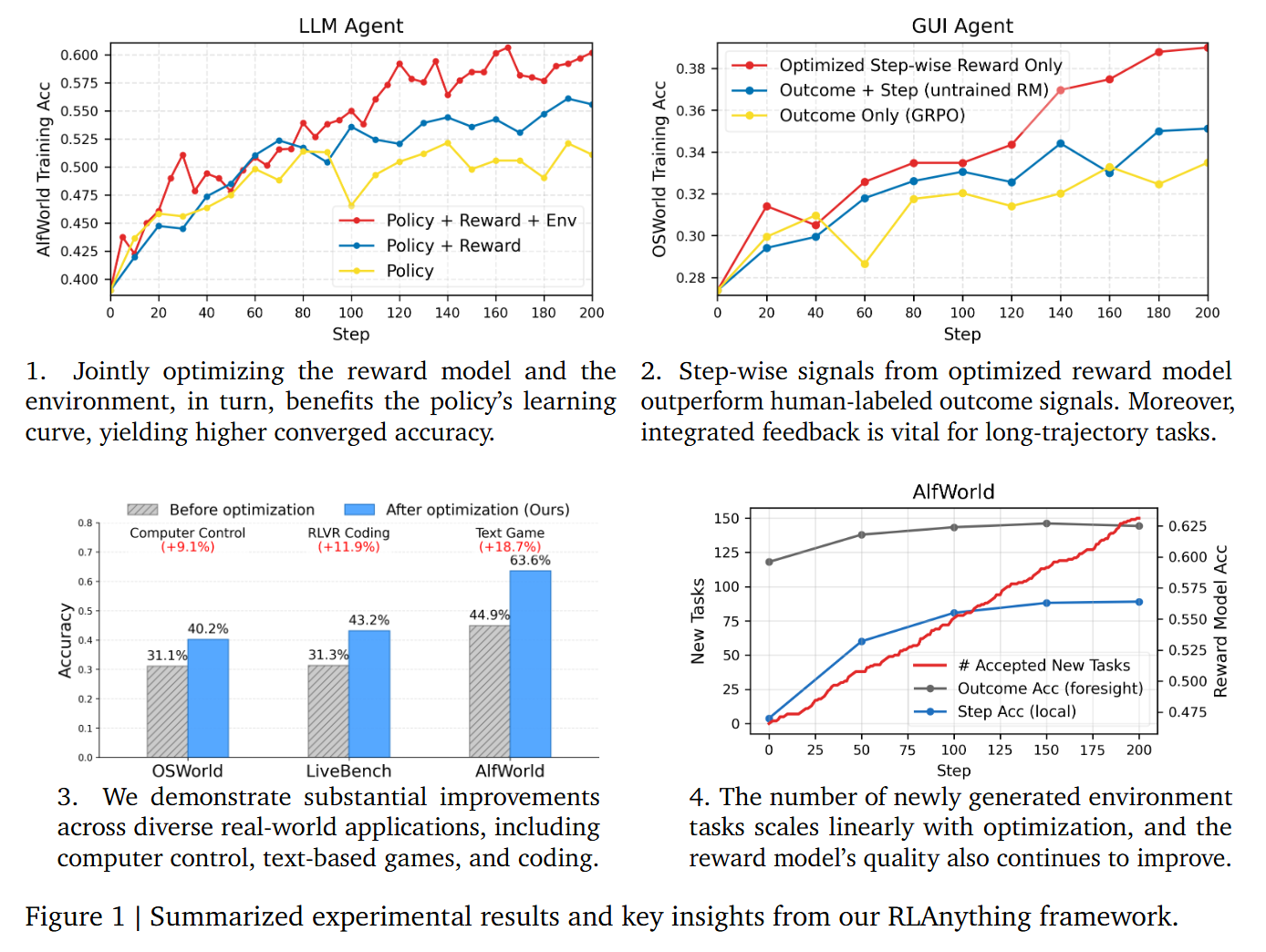
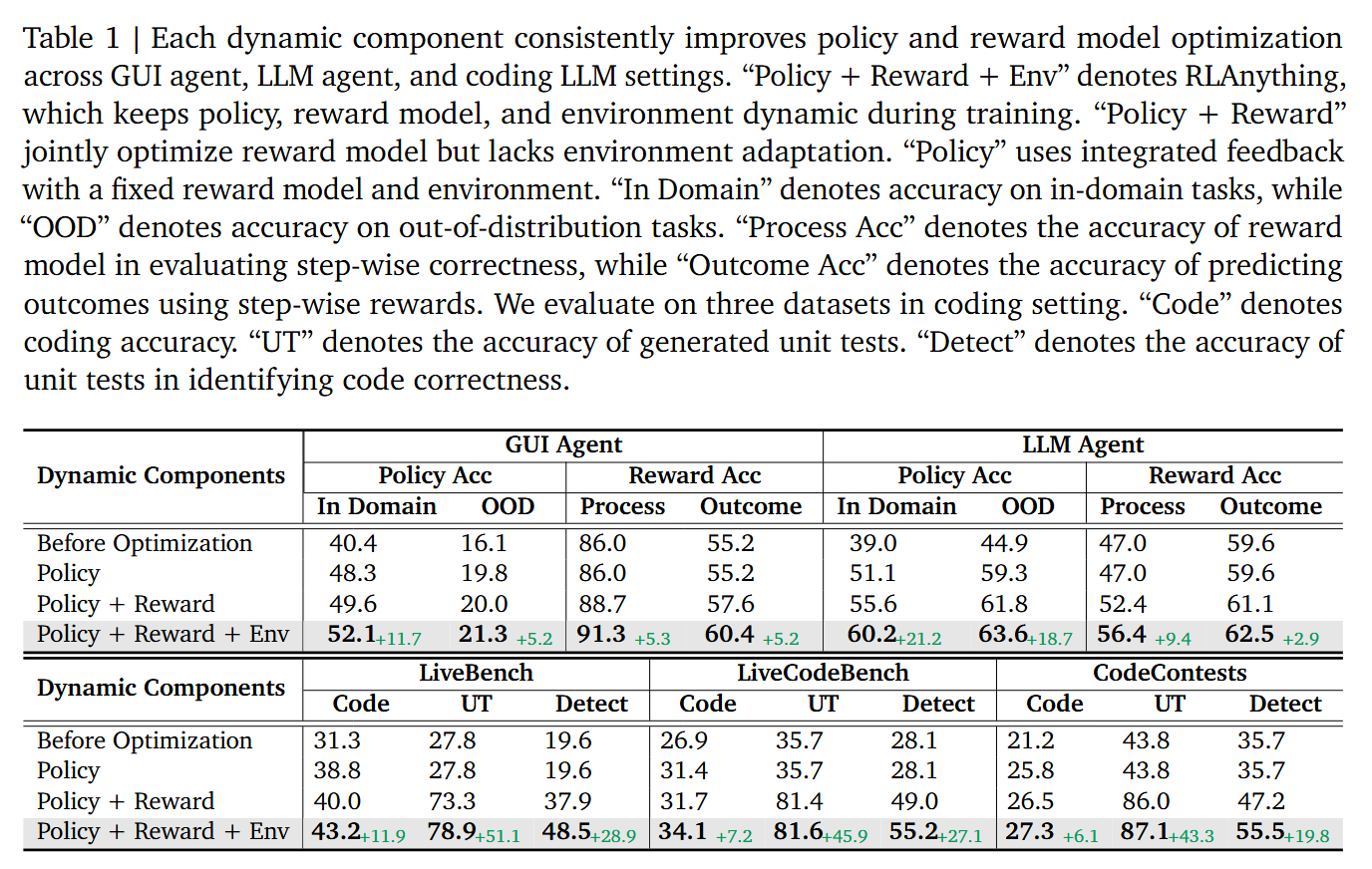
In the following table, we demonstrate the effectiveness of the RLAnything framework. Each added dynamic component contributes to improvements in the overall system.
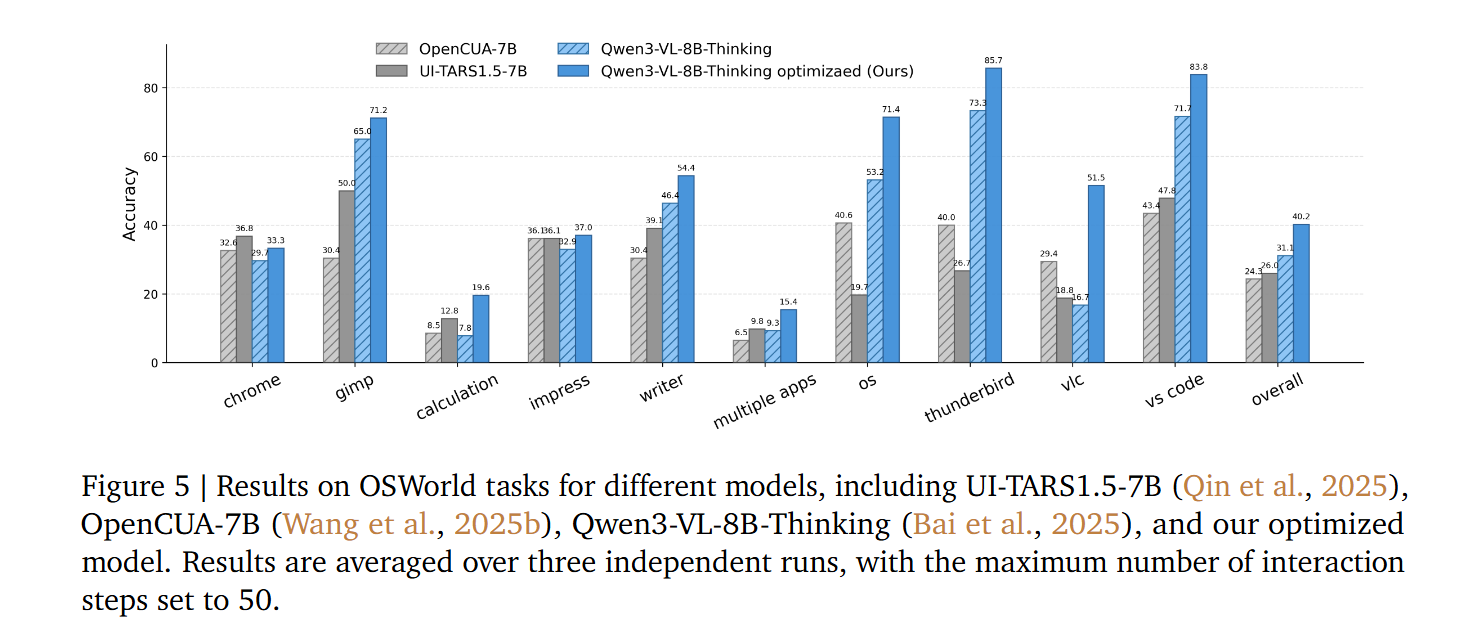
We further scale the optimization for GUI agent and achieves SoTA results:
@article{yu2025demystify,
title={Demystifying Reinforcement Learning in Agentic Reasoning},
author={Yu, Zhaochen and Yang, Ling and Zou, Jiaru and Yan, Shuicheng and Wang, Mengdi},
journal={arXiv preprint arXiv:2510.11701},
year={2025}
}
@article{wang2026rlanything,
title={RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System},
author={Wang, Yinjie and Xie, Tianbao and Shen, Ke and Wang, Mengdi and Yang, Ling},
journal={Forty-third International Conference on Machine Learning},
year={2026}
}
@inproceedings{zou2026autotool,
title={AutoTool: Dynamic Tool Selection and Integration for Agentic Reasoning},
author={Jiaru Zou and Ling Yang and Yunzhe Qi and Sirui Chen and Mengting Ai and Ke Shen and Jingrui He and Mengdi Wang},
booktitle={Forty-third International Conference on Machine Learning},
year={2026}
}
This work aims to explore more efficient paradigms for Agentic RL. Our implementation builds upon the excellent codebases of VeRL and ReTool. We sincerely thank these projects for their valuable insights and high-quality implementations, which have greatly facilitated our research.
⚠️ Experimentelle Skill-Sammlung für deutsches Recht (Arbeits-, Gesellschafts-, Insolvenz-, Datenschutz-, Prozessrecht u
Manage multiple Claude Code agents from TUI or Web with tmux and git worktrees
Project management using GitHub Issues + Git worktrees for parallel agent execution
Core skills library for Claude Code with 20+ battle-tested skills including TDD, debugging, and brainstorming