

Are you the author? Sign in to claim
The benchmark tasks and evaluation harness for "PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments".
PhysicianBench is a benchmark for evaluating LLM agents on physician tasks grounded in real clinical workflows. It comprises 100 long-horizon tasks (670 sub-checkpoints) adapted from real primary-care/specialty consultations across 21 specialties, executed in an EHR environment with real patient records accessed via standard FHIR APIs. Solving each task requires retrieving data across encounters, reasoning over heterogeneous clinical information, executing consequential clinical actions, and producing clinical documentation.
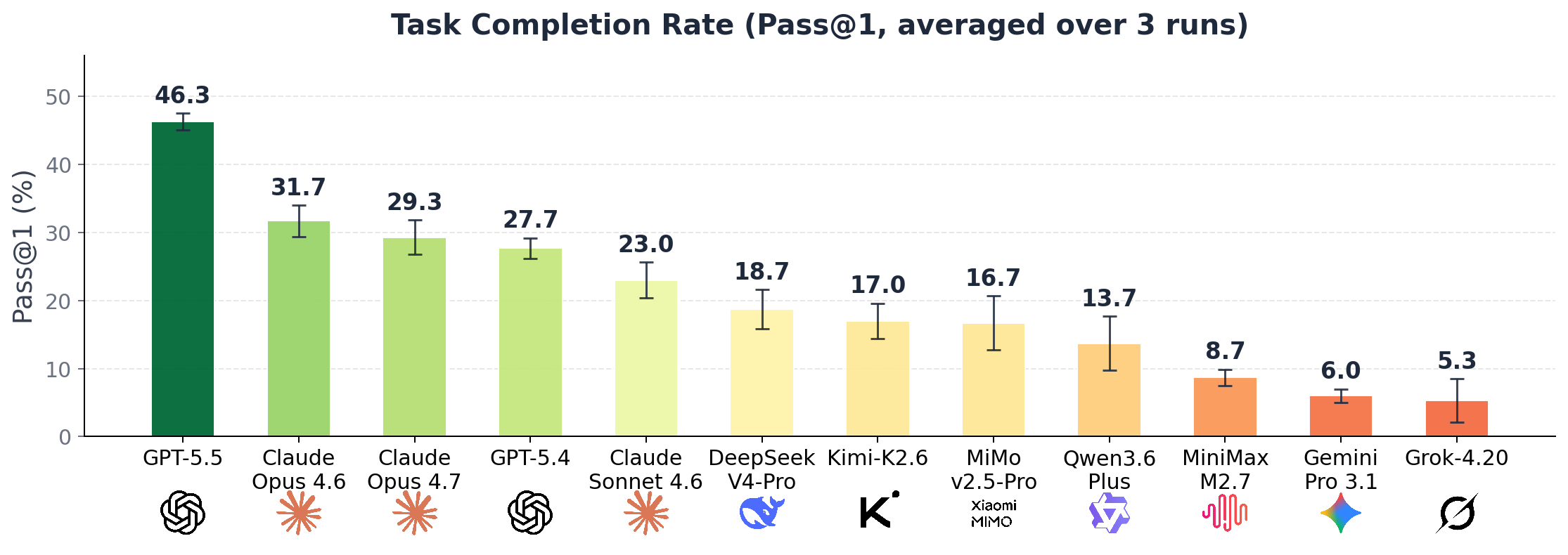
Overall model performance on PhysicianBench, ranked by pass@1 success rate.
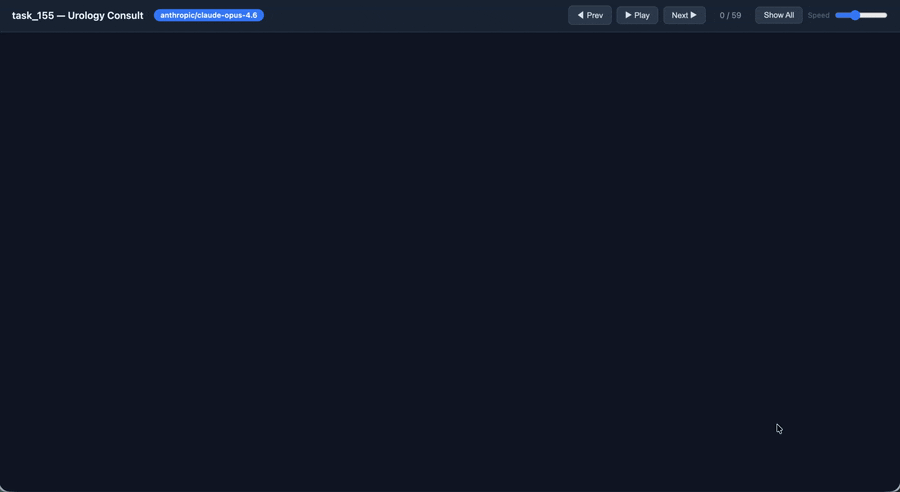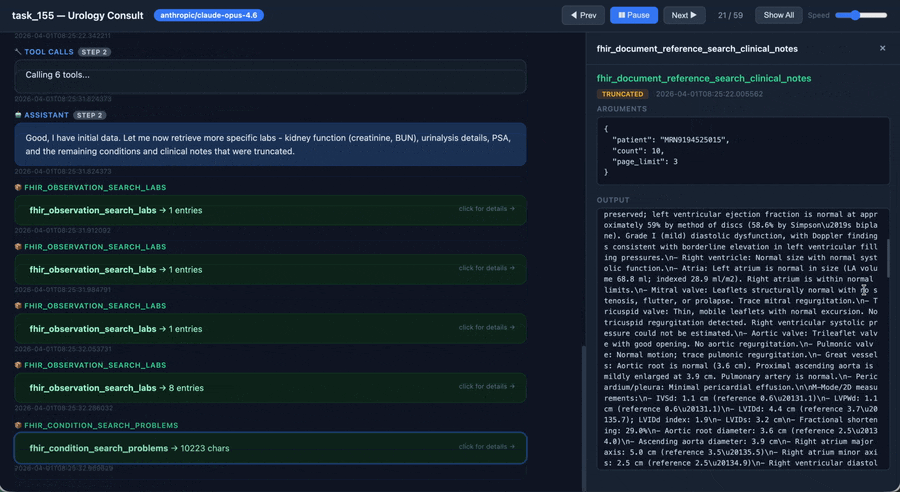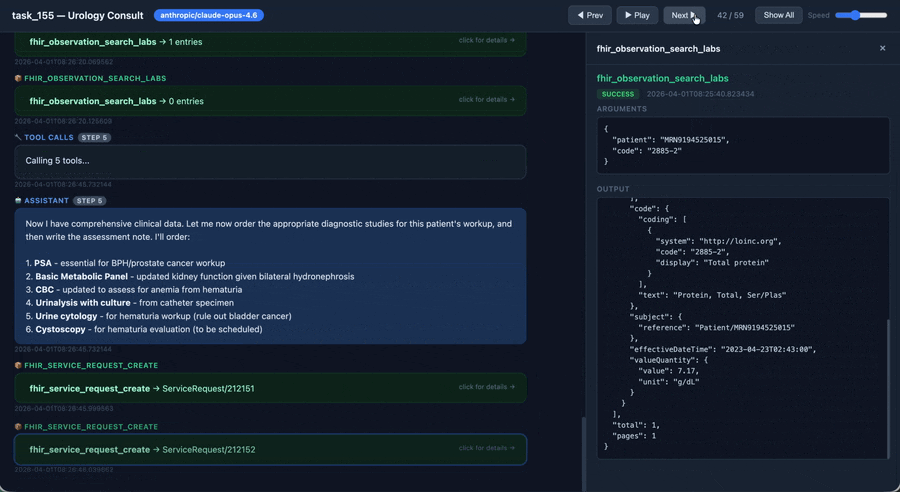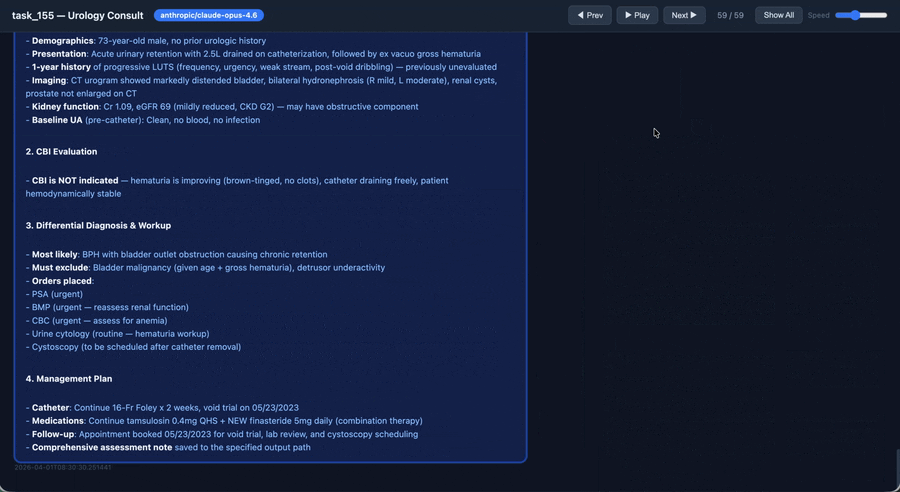
An agent working through a PhysicianBench task (2× speed). Explore the full interactive viewer on the website.
PhysicianBench uses uv for environment management. If you don't have it yet:
curl -LsSf https://astral.sh/uv/install.sh | sh
Then install project dependencies:
uv sync
The benchmark runs against a FHIR server pre-loaded with patient records, distributed as a Docker image archive on Stanford Redivis:
📦 EHR Docker image: stanford.redivis.com/datasets/a0ek-0ad8tjsw9
After downloading physicianbench-fhir-v1.tar.gz, load it into Docker:
gunzip -c physicianbench-fhir-v1.tar.gz | docker load
run_task.py and run_batch_task.sh will spin up a fresh container from this image per task and tear it down afterward, so no manual server management is required.
Create a .env file in the repo root with one of the supported backends — set whichever key matches the provider you want to use:
# Pick one (priority: OpenRouter > Anthropic > OpenAI)
OPENROUTER_API_KEY=sk-or-...
ANTHROPIC_API_KEY=sk-ant-...
OPENAI_API_KEY=sk-...
Models are passed via --model. Use OpenRouter-style IDs when going through OpenRouter (e.g., openai/gpt-5.5, anthropic/claude-opus-4.7), or native model IDs for the Anthropic / OpenAI APIs (e.g., claude-opus-4-7, gpt-5.5).
uv run python scripts/run_task.py tasks/v1/aortic_aneurysm_cad \
--model openai/gpt-5.5 --reasoning-effort high
This will:
jobs/<batch>/<task>/.bash scripts/run_batch_task.sh --model openai/gpt-5.5 --reasoning-effort high
Available parameters:
| Flag | Default | Description |
|---|---|---|
--model, -m | openai/gpt-5.5 | Model ID. Format depends on backend (see Configure model API keys). |
--reasoning-effort | high | One of low, medium, high. Forwarded to reasoning-capable models. |
--temperature | api-default | Sampling temperature (omit to use the API default). |
--n_runs | 1 | Number of independent runs per task — enables pass@3 / pass^3 scoring. |
--max-tasks | 0 (all) | Cap the number of tasks to run, useful for smoke tests. |
--max-steps | 100 | Max LLM ↔ tool steps per task before the agent is force-stopped. |
--resume | — | Path to an existing batch job dir; skips already-completed tasks and continues. |
--task-dir | tasks/v1 | Root directory of task folders. |
--fhir-image | fhir-full:v1 | Docker image tag of the pre-loaded FHIR server. |
--port | 18080 | Host port to map the FHIR container to. |
| (positional args) | — | Specific task names to run (e.g., aortic_aneurysm_cad chronic_cough_geriatric). If omitted, all tasks under --task-dir are run. |
Examples:
# Specific tasks only
bash scripts/run_batch_task.sh aortic_aneurysm_cad chronic_cough_geriatric
# Multiple runs per task (for pass@k)
bash scripts/run_batch_task.sh --model anthropic/claude-opus-4.7 --n_runs 3
# Resume an interrupted batch
bash scripts/run_batch_task.sh --resume jobs/2026-04-29__03-57-03__openai_gpt-5.5__high__t0
@article{physicianbench2026,
title = {PhysicianBench: Evaluating LLM Agents on Physician Tasks in Real-World EHR Environments},
author = {Ruoqi Liu and Imran Q. Mohiuddin and Austin J. Schoeffler and Kavita Renduchintala and Ashwin Nayak and Prasantha L. Vemu and Shivam C. Vedak and Kameron C. Black and John L. Havlik and Isaac Ogunmola and Stephen P. Ma and Roopa Dhatt and Jonathan H. Chen},
year = {2026},
eprint = {2605.02240},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2605.02240}
}
See LICENSE.
⚠️ Experimentelle Skill-Sammlung für deutsches Recht (Arbeits-, Gesellschafts-, Insolvenz-, Datenschutz-, Prozessrecht u
Manage multiple Claude Code agents from TUI or Web with tmux and git worktrees
Project management using GitHub Issues + Git worktrees for parallel agent execution
Core skills library for Claude Code with 20+ battle-tested skills including TDD, debugging, and brainstorming