

Are you the author? Sign in to claim
One memory, three terminals. Shared memory layer for Claude Code, Codex, and Gemini CLI — hybrid retrieval (vector + BM2
Shared Memory Layer for Claude Code, Codex, and Gemini CLI
One memory. Three terminals. Context that survives across windows.
A local-first memory system backed by LanceDB that turns scattered conversation history into reusable knowledge — shared across your coding agents, recalled automatically.

![]()
Coding agents forget everything between windows. Your context — project configs, debugging decisions, entity mappings — is scattered across Claude Code, Codex, and Gemini CLI with no shared memory.
RecallNest solves this: a single LanceDB-backed memory layer that your coding agents read and write. Context stored in one window is auto-recalled in another. Sessions checkpoint on exit and resume on start. Memory decays, evolves, and self-organizes — not just raw log storage.
/plugin marketplace add AliceLJY/recallnest
/plugin install recallnest@AliceLJY
RecallNest starts automatically with Claude Code. No manual MCP config needed.
Requires: Bun (recommended) or Node.js 18+. Dependencies install on first start.
npx recallnest --help # run directly
# or
npm install -g recallnest # install globally
recallnest doctor
Works with Node.js 18+ (via tsx) or Bun. No git clone needed.
git clone https://github.com/AliceLJY/recallnest.git
cd recallnest
bun install
cp config.json.example config.json
cp .env.example .env
# Edit .env → add your JINA_API_KEY
bun run api
# → RecallNest API running at http://localhost:4318
# Store a memory
curl -X POST http://localhost:4318/v1/store \
-H "Content-Type: application/json" \
-d '{"text": "User prefers dark mode", "category": "preferences"}'
# Recall memories
curl -X POST http://localhost:4318/v1/recall \
-H "Content-Type: application/json" \
-d '{"query": "user preferences"}'
# Check stats
curl http://localhost:4318/v1/stats
bash integrations/claude-code/setup.sh
bash integrations/gemini-cli/setup.sh
bash integrations/codex/setup.sh
Each script installs MCP access and managed continuity rules, so resume_context fires automatically in fresh windows.
bun run src/cli.ts ingest --source all
bun run seed:continuity
bun run src/cli.ts doctor
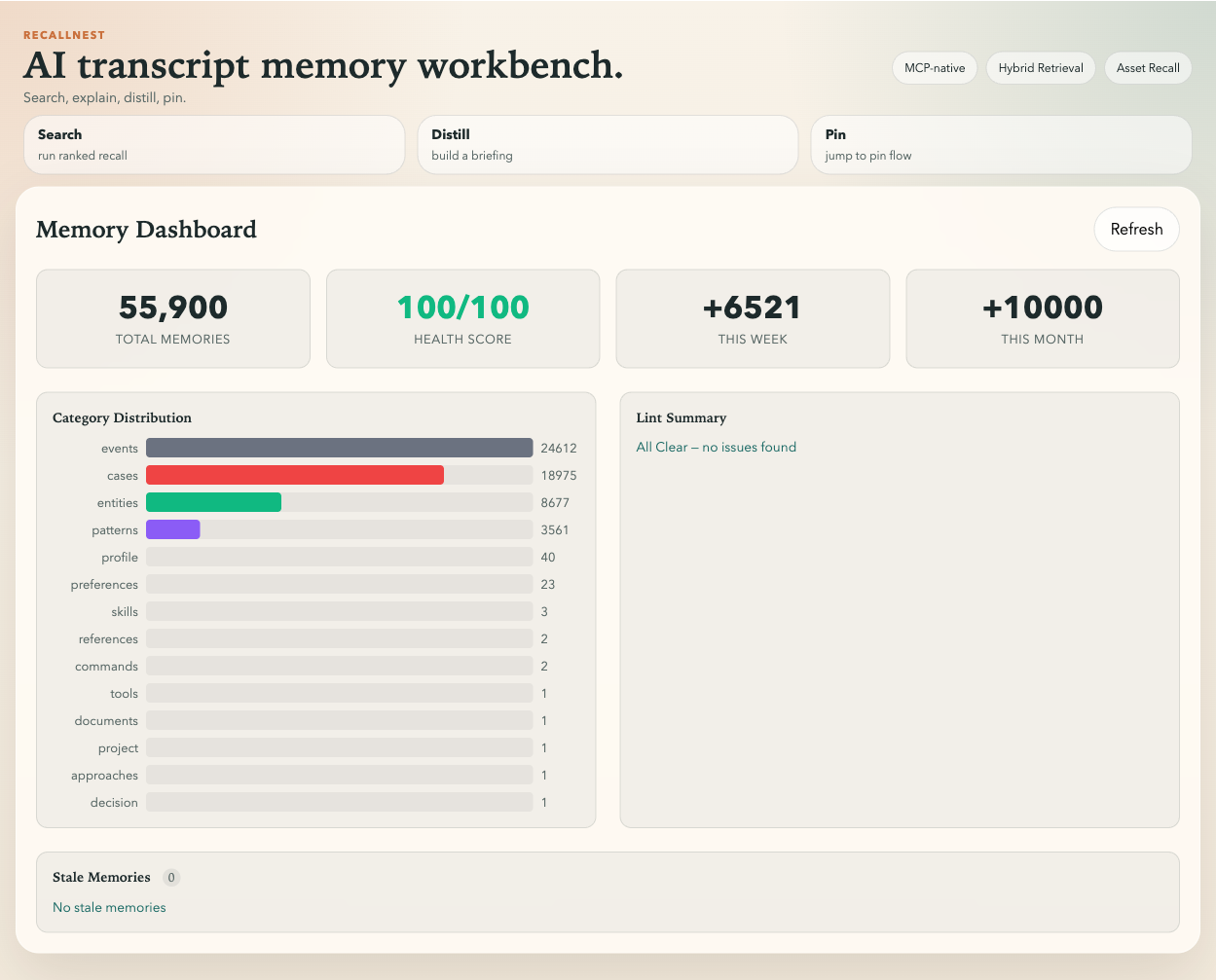
Dashboard — total count, category distribution, health score, and growth trends at a glance.
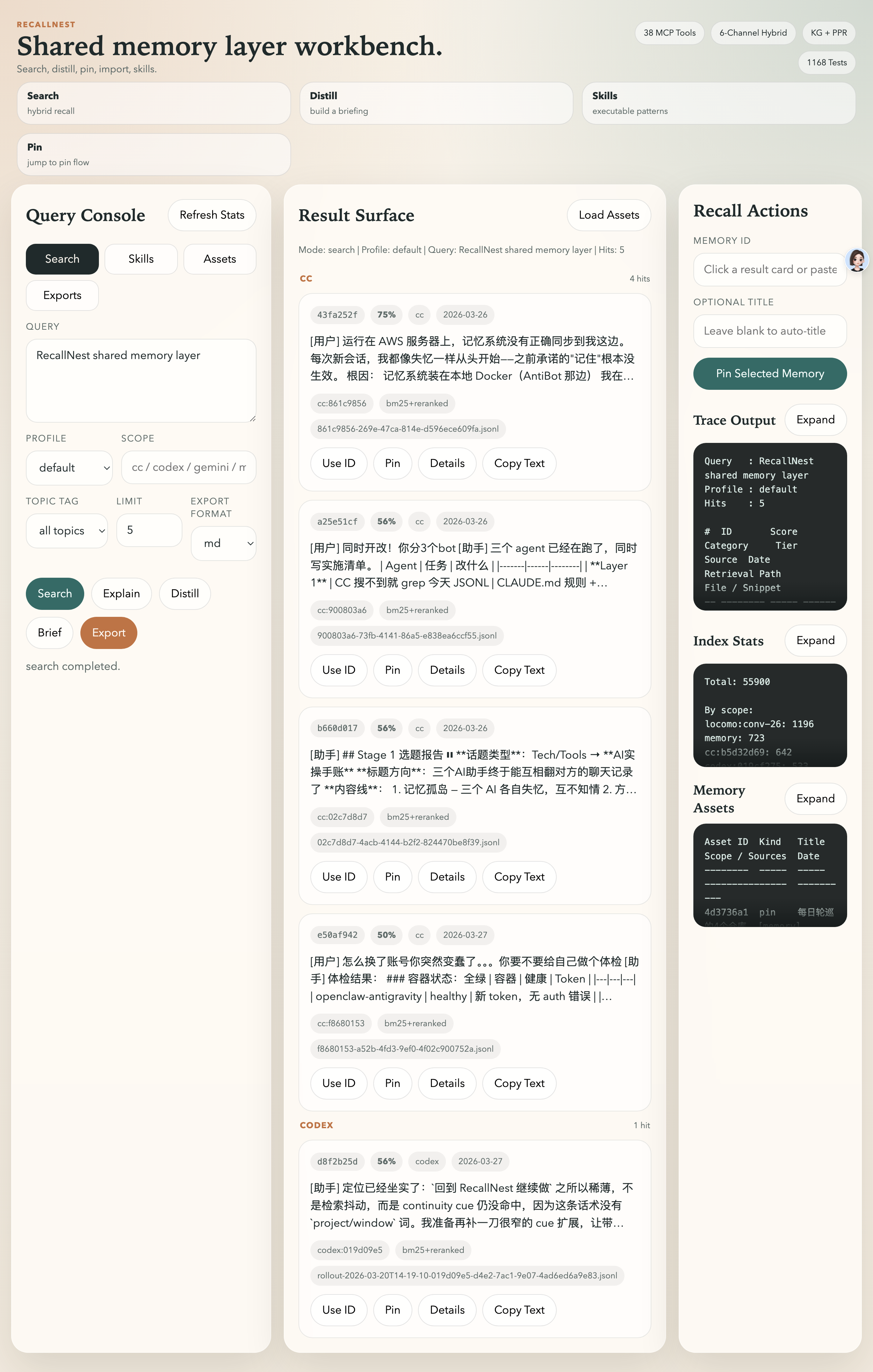
Search Workbench — hybrid search with topic tag filtering, 4 retrieval profiles, Skills browser, and asset management.
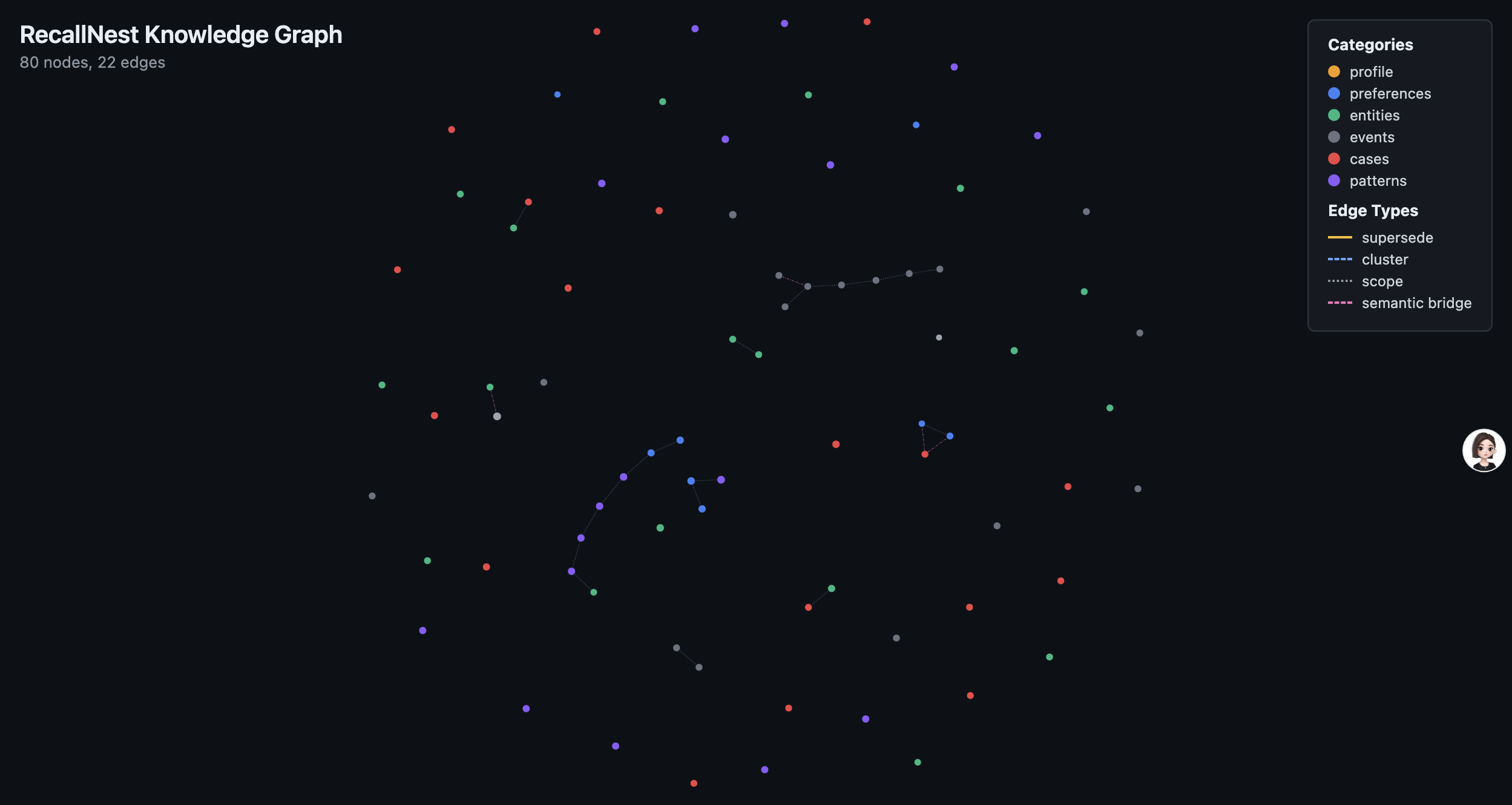
Knowledge Graph — interactive force-directed visualization with semantic bridges revealing cross-domain connections.
bun run src/ui-server.ts
# → http://localhost:4317
| Capability | Description |
|---|---|
| CC Plugin | Install in Claude Code with one command — no manual config |
| Shared Index | One LanceDB store for Claude Code, Codex, and Gemini CLI |
| Dual Interface | MCP (stdio) for CLI tools + HTTP API for custom agents |
| One-Click Setup | Integration scripts install MCP access and continuity rules |
| Capability | Description |
|---|---|
| Hybrid Retrieval | 6-channel: vector + BM25 + L0/L1/L2 multi-vector + KG graph (PPR) |
| 4 Retrieval Profiles | default, writing, debug, fact-check — tuned for different tasks |
| Session Continuity | checkpoint_session + resume_context (full/light/summary modes) with repo-state guard |
| Session Distiller | 3-layer conversation compression: microcompact → LLM summary → knowledge extraction |
| Conversation Import | Import from Claude Code, Claude.ai, ChatGPT, Slack, and plaintext |
| Topic Tags | Intra-scope topic partitioning — auto-detected, filterable in search |
| Capability | Description |
|---|---|
| Memory Evolution | Supersede chains, decay scoring, LLM importance, consolidation, archival |
| Smart Promotion | Evidence → durable memory with conflict guards, merge resolution, and audit trail |
| Privacy Tiers | 4-tier (ephemeral / private / durable / shared) with cascade forgetting |
| Admission Control | Write-time gating: noise filter, importance floor, dedup, rate limiting |
| Memory Lint | Contradiction, duplicate, stale, and orphan detection with health score |
| Offline Consolidation | dream command: clustering, merging, pruning of accumulated memories |
| Capability | Description |
|---|---|
| Knowledge Graph | Entity relation graph with PPR algorithm for multi-hop questions |
| Constructive Retrieval | Multi-source candidate expansion + grounded context reconstruction |
| Narrative Architecture | 3-layer autobiographical metadata (life-period → general-event → specific-event) |
| Skill Memory | Store, retrieve, and promote executable skills from recurring patterns |
| Predictive Reminders | Behavioral-signal prediction engine surfaces "you might need this" suggestions |
| 6 Categories | profile, preferences, entities, events, cases, patterns — with category-aware merge strategies |
| Capability | Description |
|---|---|
| Dashboard | Web UI with stats, category distribution, growth trends, and health |
| Workflow Observation | Dedicated append-only workflow health records, outside regular memory |
| Structured Assets | Pins, briefs, and distilled summaries — not just raw logs |
| Data Checkup | Data quality health checks on the memory store (including source health) |
| Source Heartbeats | Automatic ingest health tracking per data source with staleness alerts |
| Export Graph | Export interactive HTML knowledge graph visualization |
| Batch Operations | Store up to 20 memories in a single call with dedup |
| Connector Framework | Standard connector-v1 format for external data sources with example adapters |
v2.0 built the operational memory platform; v2.1 added philosophy-informed memory behavior.
Five upgrades derived from 9 research dimensions in philosophy of memory, each mapped to concrete engineering:
Emotion-Aware Decay (Affective Memory Theory) — Memories with strong emotional content decay 20-30% slower. Keyword-based emotion detection computes salience (mnemonic significance), which feeds into the Weibull half-life formula and a rebalanced 4-factor evolution score. Zero LLM cost.
Memory Ethics Layer (Right to Be Forgotten / GDPR Art. 17) — Four privacy tiers (ephemeral / private / durable / shared). Cascade forgetting engine that propagates deletion through KG triples, evolution chains, pin assets, and briefs. Full audit trail. forget_memory MCP tool for agent-driven deletion.
Autobiographical Narrative (Narrative Identity Theory / Conway's 3-layer model) — Memories are tagged with lifePeriod → generalEvent → specificEvent hierarchy, orthogonal to existing 6 categories. Retrieval pulls narrative siblings. Context rendering groups by life period. Rule-based tagger with EN+CN support.
Constructive Retrieval (Simulation Theory / Michaelian) — Instead of returning raw stored text, RecallNest now reconstructs context from an expanded candidate set: KG neighbors + evolution chains + cluster members + narrative siblings. Source-map grounded coverage replaces lexical overlap. Contradictions are detected and flagged.
Predictive Prospective Memory (Mental Time Travel / Tulving) — Heuristic prediction engine that surfaces "you might need this" reminders from behavioral signals: stale checkpoint open loops, corrected workflow observations, high-frequency dormant memories, and uncovered query topics. Zero LLM cost. Auto-expire in 7 days if unaccepted.
v2.1 added philosophy-informed behavior; v2.2 closes the last three engine-layer gaps identified by a frontier research scan (ACC, PI-LLM, TSM).
Memory Confidence Meta-tags (ACC / Dual-Process UQ) — Each memory now carries structured ConfidenceMetadata (score, reliability tier: direct / inferred / hearsay). Auto-assigned from source on write (manual = 0.9, agent = 0.7, conversation_import = 0.5). Retrieval scores are weighted by confidence. resume_context tags low-confidence items with [低置信].
Interference Detection + Active Forgetting Gate (PI-LLM / SleepGate) — Semantic cluster detection identifies groups of near-duplicate memories competing for retrieval. Enhanced RIF keeps only top-K (default 3) per cluster; extras are demoted 50% instead of removed. Write-time pre-warning: when a scope accumulates ≥5 high-similarity active memories, the weakest is flagged pending_review. data_checkup reports interference density.
Temporal Validity Windows (TSM / TiMem / Zep) — store_memory accepts validUntil (expiration) and eventTime (when the event actually happened). search_memory supports validAt (point-in-time query) and includeExpired (demote 80% instead of hide). Auto-GC applies 2× decay acceleration to expired memories.
v2.2 hardened retrieval quality; v2.3 opens RecallNest to external data sources with a standard connector framework and operational health monitoring.
Connector-v1 Standard (GB-2) — A JSON format (ConnectorOutputV1) that any external script can produce. Obsidian vaults, emails, RSS feeds, log files — normalize once, ingest through the full dedup/embed/extract pipeline. See docs/connector-spec.md for the specification and connectors/examples/ for adapter skeletons (email, logs, RSS).
Obsidian Vault Ingestion (GB-1) — First-party Obsidian connector: scans .md files, extracts frontmatter + wikilinks, maps folder structure to tags. One command: lm ingest --obsidian /path/to/vault.
Source Health Monitoring (GB-3) — Every connector ingest writes a heartbeat to data/source-heartbeat.json. data_checkup flags stale sources (>7d warning, >30d error). doctor --ci shows a per-source heartbeat summary with human-readable age.
┌──────────────────────────────────────────────────────────┐
│ Client Layer │
├──────────┬──────────┬──────────┬──────────────────────────┤
│ Claude │ Gemini │ Codex │ Custom Agents / curl │
│ Code │ CLI │ │ │
└────┬─────┴────┬─────┴────┬─────┴──────┬──────────────────┘
│ │ │ │
└──── MCP (stdio) ───┘ HTTP API (port 4318)
│ │
▼ ▼
┌──────────────────────────────────────────────────────────┐
│ Integration Layer │
│ ┌─────────────────────┐ ┌────────────────────────────┐ │
│ │ MCP Server │ │ HTTP API Server │ │
│ │ 41 tools │ │ 21 endpoints │ │
│ └─────────┬───────────┘ └──────────┬─────────────────┘ │
└────────────┼─────────────────────────┼───────────────────┘
└──────────┬──────────────┘
▼
┌──────────────────────────────────────────────────────────┐
│ Core Engine │
│ │
│ ┌────────────┐ ┌────────────┐ ┌─────────────────────┐ │
│ │ Retriever │ │ Classifier │ │ Context Composer │ │
│ │ (vector + │ │ (6 cats) │ │ (resume_context) │ │
│ │ BM25 + RRF)│ │ │ │ │ │
│ └────────────┘ └────────────┘ └──────────────────────┘ │
│ ┌────────────┐ ┌────────────┐ ┌─────────────────────┐ │
│ │ Decay │ │ Conflict │ │ Capture Engine │ │
│ │ Engine │ │ Engine │ │ (evidence → durable) │ │
│ │ (Weibull) │ │ (audit + │ │ │ │
│ │ │ │ merge) │ │ │ │
│ └────────────┘ └────────────┘ └──────────────────────┘ │
└──────────────────────────┬───────────────────────────────┘
▼
┌──────────────────────────────────────────────────────────┐
│ Storage Layer │
│ ┌─────────────────────┐ ┌────────────────────────────┐ │
│ │ LanceDB │ │ Jina Embeddings v5 │ │
│ │ (vector + columnar) │ │ (1024-dim, task-aware) │ │
│ └─────────────────────┘ └────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘
profile and preferences use merge-on-conflict (latest wins); events and cases use append-only (history preserved)Full architecture deep-dive:
docs/architecture.md
RecallNest serves two interfaces:
Examples live in integrations/examples/:
| Framework | Example | Language |
|---|---|---|
| Claude Agent SDK | memory-agent.ts | TypeScript |
| OpenAI Agents SDK | memory-agent.py | Python |
| LangChain | memory-chain.py | Python |
| Tool | Description |
|---|---|
workflow_observe | Store an append-only workflow observation outside regular memory |
workflow_health | Inspect workflow observation health or show a degraded-workflow dashboard |
workflow_evidence | Build an evidence pack for a workflow primitive |
store_memory | Store a durable memory for future windows |
store_workflow_pattern | Store a reusable workflow as durable patterns memory |
store_case | Store a reusable problem-solution pair as durable cases memory |
promote_memory | Explicitly promote evidence into durable memory |
promote_scan | Scan recent evidence and auto-promote qualifying memories into durable storage |
list_conflicts | List or inspect promotion conflict candidates |
audit_conflicts | Summarize stale/escalated conflict priorities |
escalate_conflicts | Preview or apply conflict escalation metadata |
resolve_conflict | Resolve a stored conflict candidate (keep / accept / merge) |
checkpoint_session | Store the current active work state outside durable memory |
latest_checkpoint | Inspect the latest saved checkpoint by session or scope |
resume_context | Compose startup context for a fresh window |
search_memory | Proactive recall at task start |
explain_memory | Explain why memories matched |
distill_memory | Distill results into a compact briefing |
brief_memory | Create a structured brief and re-index it |
pin_memory | Promote a scoped memory into a pinned asset |
export_memory | Export a distilled memory briefing to disk |
list_pins | List pinned memories |
list_assets | List all structured assets |
list_dirty_briefs | Preview outdated brief assets created before the cleanup rules |
clean_dirty_briefs | Archive dirty brief assets and remove their indexed rows |
memory_stats | Show index statistics |
memory_drill_down | Inspect a specific memory entry with full metadata and provenance |
auto_capture | Heuristically extract and store memory signals from text (zero LLM calls) |
set_reminder | Set a prospective memory reminder to surface in a future session |
consolidate_memories | Cluster near-duplicate memories and merge them (dry-run by default) |
store_skill | Store an executable skill with trigger conditions and verification |
retrieve_skill | Retrieve matching executable skills by semantic similarity |
scan_skill_promotions | Scan cases/patterns for promotion candidates to skills |
list_tools | Discover available tools by tier (core/advanced/full) |
batch_store | Store up to 20 memories in a single call with dedup |
distill_session | Distill a conversation into structured knowledge via 3-layer pipeline |
import_conversations | Import conversations from Claude Code, ChatGPT, Slack, and more |
data_checkup | Run data quality health checks on the memory store |
dream | Run offline memory consolidation (clustering, merging, pruning) |
memory_lint | Run memory quality checks: contradictions, duplicates, stale entries, orphans |
forget_memory | Cascade-delete a memory with KG cleanup, pin archival, and audit trail |
export_graph | Export memories as an interactive HTML knowledge graph |
Base URL: http://localhost:4318
| Endpoint | Method | Description |
|---|---|---|
/v1/recall | POST | Quick semantic search |
/v1/store | POST | Store a new memory |
/v1/capture | POST | Store multiple structured memories |
/v1/pattern | POST | Store a structured workflow pattern |
/v1/case | POST | Store a structured problem-solution case |
/v1/promote | POST | Promote evidence into durable memory |
/v1/conflicts | GET | List or inspect promotion conflict candidates |
/v1/conflicts/audit | GET | Summarize stale/escalated conflict priorities |
/v1/conflicts/escalate | POST | Preview or apply conflict escalation metadata |
/v1/conflicts/resolve | POST | Resolve a stored conflict candidate (keep / accept / merge) |
/v1/checkpoint | POST | Store the current work checkpoint |
/v1/workflow-observe | POST | Store a workflow observation outside durable memory |
/v1/checkpoint/latest | GET | Fetch the latest checkpoint by session or scope |
/v1/workflow-health | GET | Inspect workflow health or return a degraded-workflow dashboard |
/v1/workflow-evidence | GET | Build a workflow evidence pack from recent issue observations |
/v1/resume | POST | Compose startup context for a fresh window |
/v1/search | POST | Advanced search with full metadata |
/v1/stats | GET | Memory statistics |
/v1/lint | GET | Memory quality lint report |
/v1/health | GET | Health check |
Full documentation: docs/api-reference.md
# Search & explore
bun run src/cli.ts search "your query"
bun run src/cli.ts explain "your query" --profile debug
bun run src/cli.ts distill "topic" --profile writing
bun run src/cli.ts stats
# Workflow observation
bun run src/cli.ts workflow-observe resume_context "Fresh window skipped continuity recovery." --outcome missed --scope project:recallnest
bun run src/cli.ts workflow-health resume_context --scope project:recallnest
bun run src/cli.ts workflow-evidence checkpoint_session --scope project:recallnest
# Conflict management
bun run src/cli.ts conflicts list
bun run src/cli.ts conflicts list --attention resolved
bun run src/cli.ts conflicts list --group-by cluster --attention resolved
bun run src/cli.ts conflicts audit
bun run src/cli.ts conflicts audit --export --format md
bun run src/cli.ts conflicts escalate --attention stale
bun run src/cli.ts conflicts show af70545a
bun run src/cli.ts conflicts resolve af70545a --keep-existing
bun run src/cli.ts conflicts resolve af70545a --merge
bun run src/cli.ts conflicts resolve --all --keep-existing --status open
# Memory health & visualization
bun run src/cli.ts lint # memory quality report
bun run src/cli.ts lint --scope project:myapp # lint a specific scope
bun run src/cli.ts graph --open # export & open knowledge graph
bun run src/cli.ts graph --max-nodes 50 # smaller graph
# Ingestion & diagnostics
bun run src/cli.ts ingest --source all
bun run src/cli.ts doctor
RecallNest works out of the box with English. For multilingual memory (Chinese, Japanese, Thai, and 20+ more), install babel-memory with the language packs you need:
# Chinese
npm install babel-memory jieba-wasm
# Japanese
npm install babel-memory @sglkc/kuromoji
# Thai
npm install babel-memory wordcut
# European languages (German, French, Spanish, Russian, etc.)
npm install babel-memory snowball-stemmers
# Multiple languages at once
npm install babel-memory jieba-wasm @sglkc/kuromoji snowball-stemmers
RecallNest auto-detects babel-memory at startup — no configuration needed. Without babel-memory, RecallNest still works perfectly with standard BM25 text search.
RecallNest is actively maintained. All major architecture phases are complete — see the full Roadmap for current priorities and future plans.
RecallNest started as a fork of memory-lancedb-pro and shares its core ideas around hybrid retrieval, decay modeling, and memory-as-engineering-system. The key difference:
| Source | Contribution |
|---|---|
| memory-lancedb-pro by @win4r | Fork base — hybrid retrieval, decay modeling, and memory architecture |
| Claude Code | Foundation and early project scaffolding |
| OpenAI Codex | Productization and MCP expansion |
Special thanks to Qin Chao (@win4r) and the CortexReach team for the foundational work.
Part of the 小试AI open-source AI workflow:
| Project | Description |
|---|---|
| babel-memory | Multilingual preprocessing for BM25 — 27+ languages, zero deps |
| cc-empire | Hooks/rules/methodology — the connective tissue of the whole ecosystem |
| telegram-ai-bridge | Telegram bots for Claude, Codex, and Gemini |
| tg-bridge-channel | Sister Telegram bridge using Claude Agent View background sessions |
| wechat-ai-bridge | Run Claude Code / Codex / Gemini in WeChat with session management |
| openclaw-tunnel | Docker ↔ host CLI bridge (maintenance mode — LanceDB test only) |
| digital-clone-skill | Build digital clones from corpus data |
| claude-code-studio | Multi-session collaboration platform for Claude Code |
| workflow-orchestrator | Natural-language pipeline orchestrator for Claude Code |
MIT
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows