

Are you the author? Sign in to claim
Context-optimized MCP server for web scraping. Reduces LLM token usage by 70-90% through server-side CSS filtering and H
![]()
![]()
A context-optimized MCP server for web scraping. Reduces LLM token usage by 70-90% through server-side HTML filtering, markdown conversion, and CSS selector targeting.
# Run with Docker (GitHub Container Registry)
docker run -d -p 8000:8000 --name scraper-mcp ghcr.io/cotdp/scraper-mcp:latest
# Add to Claude Code
claude mcp add --transport http scraper http://localhost:8000/mcp --scope user
Try it:
> scrape https://example.com
> scrape and filter .article-content from https://blog.example.com/post
Endpoints:
http://localhost:8000/mcphttp://localhost:8000/perplexity tool)perplexity_reason tool)PERPLEXITY_API_KEY environment variable (overridable at runtime)sonar is enabled by default; sonar-pro,
sonar-reasoning, sonar-reasoning-pro, and sonar-deep-research must be enabled
explicitly to control cost (see docs/CONFIGURATION.md)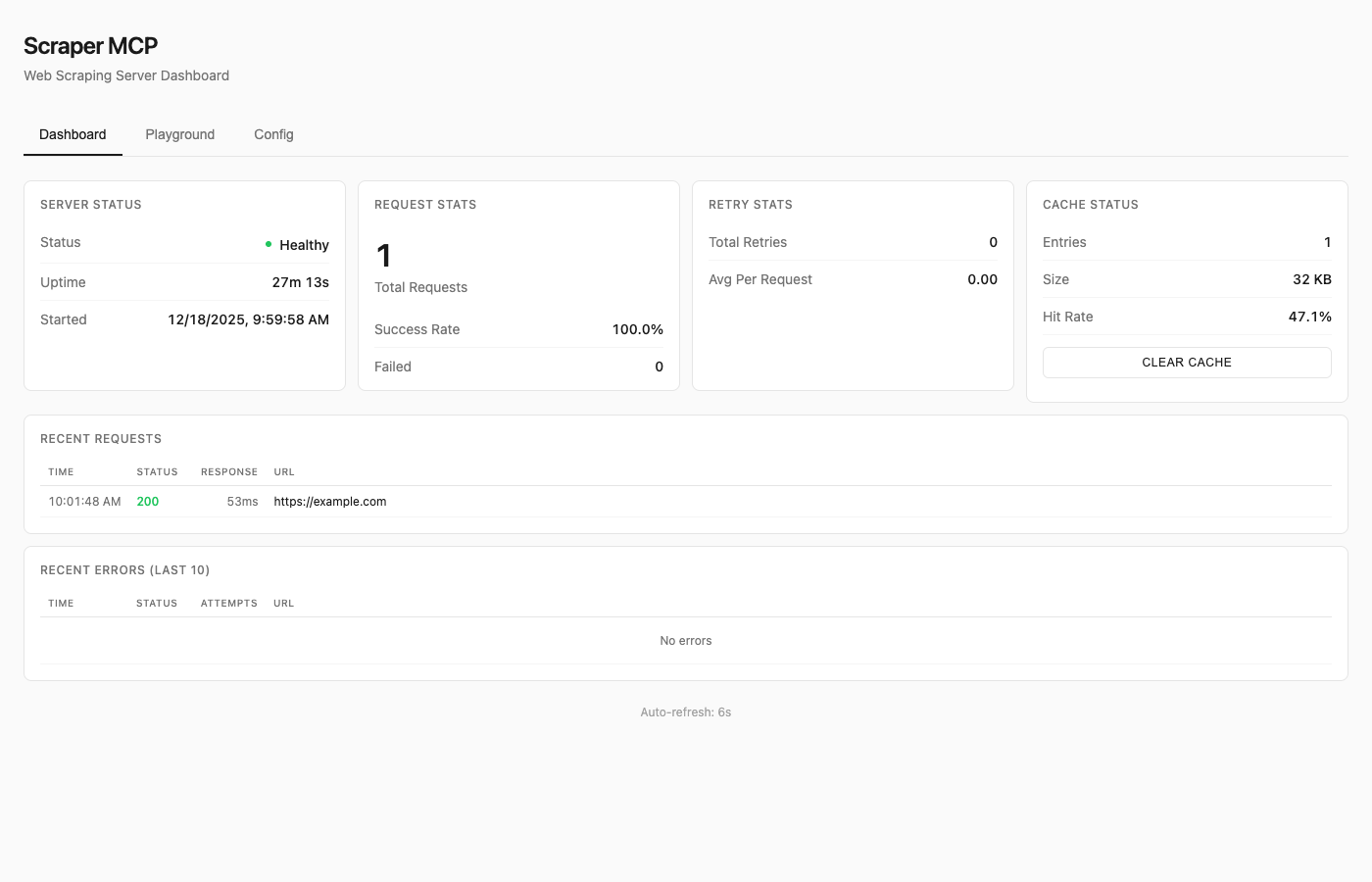
See Dashboard Guide for details.
| Tool | Description |
|---|---|
scrape_url | HTML converted to markdown (best for LLMs) |
scrape_url_html | Raw HTML content |
scrape_url_text | Plain text extraction |
scrape_extract_links | Extract all links with metadata |
perplexity | AI web search with citations |
perplexity_reason | Complex reasoning tasks |
All tools support:
timeout and max_retries parameterscss_selector for targeted extractionrender_js for JavaScript rendering (SPAs, dynamic content)Note: Resources are disabled by default to reduce context overhead. Enable with
--enable-resourcesflag orENABLE_RESOURCES=trueenvironment variable.
MCP resources provide read-only data access via URI-based addressing:
| URI | Description |
|---|---|
cache://stats | Cache hit rate, size, entry counts |
cache://requests | List of recent request IDs |
cache://request/{id} | Retrieve cached result by ID |
config://current | Current runtime configuration |
config://scraping | Timeout, retries, concurrency |
server://info | Version, uptime, capabilities |
server://metrics | Request counts, success rates |
Note: Prompts are disabled by default to reduce context overhead. Enable with
--enable-promptsflag orENABLE_PROMPTS=trueenvironment variable.
MCP prompts provide reusable workflow templates:
| Prompt | Description |
|---|---|
analyze_webpage | Structured webpage analysis |
summarize_content | Generate content summaries |
extract_data | Extract specific data types |
seo_audit | Comprehensive SEO check |
link_audit | Analyze internal/external links |
research_topic | Multi-source research |
fact_check | Verify claims across sources |
See API Reference for complete documentation.
For SPAs (React, Vue, Angular) and pages with dynamic content, enable JavaScript rendering:
# Enable JS rendering with render_js=True
scrape_url(["https://spa-example.com"], render_js=True)
# Combine with CSS selector for targeted extraction
scrape_url(["https://react-app.com"], render_js=True, css_selector=".main-content")
When to use render_js=True:
When NOT needed:
How it works:
Memory considerations:
Testing JS rendering:
Use the dashboard playground at http://localhost:8000/ to test JavaScript rendering interactively with the toggle switch.
# Using GitHub Container Registry (recommended)
docker run -d -p 8000:8000 --name scraper-mcp ghcr.io/cotdp/scraper-mcp:latest
# With JavaScript rendering (requires more memory)
docker run -d -p 8000:8000 --memory=1g --name scraper-mcp ghcr.io/cotdp/scraper-mcp:latest
# With Perplexity AI
docker run -d -p 8000:8000 -e PERPLEXITY_API_KEY=your_key ghcr.io/cotdp/scraper-mcp:latest
For persistent storage and custom configuration:
# docker-compose.yml
services:
scraper-mcp:
image: ghcr.io/cotdp/scraper-mcp:latest
ports:
- "8000:8000"
volumes:
- cache:/app/cache
environment:
- PERPLEXITY_API_KEY=${PERPLEXITY_API_KEY:-}
- PLAYWRIGHT_MAX_CONTEXTS=5
deploy:
resources:
limits:
memory: 1G # Recommended for JS rendering
restart: unless-stopped
volumes:
cache:
docker-compose up -d
Production deployment (pre-built image from GHCR):
docker-compose -f docker-compose.prod.yml up -d
To upgrade an existing deployment to the latest version:
# Pull the latest image
docker pull ghcr.io/cotdp/scraper-mcp:latest
# Restart with new image (docker-compose)
docker-compose down && docker-compose up -d
# Or for production deployments
docker-compose -f docker-compose.prod.yml pull
docker-compose -f docker-compose.prod.yml up -d
# Or restart a standalone container
docker stop scraper-mcp && docker rm scraper-mcp
docker run -d -p 8000:8000 --name scraper-mcp ghcr.io/cotdp/scraper-mcp:latest
Your cache data persists in the named volume across upgrades.
| Tag | Description |
|---|---|
latest | Latest stable release |
main | Latest build from main branch |
v0.4.0 | Specific version |
Create a .env file for custom settings:
# Perplexity AI (optional)
PERPLEXITY_API_KEY=your_key_here
# JavaScript rendering (optional, requires Playwright)
PLAYWRIGHT_MAX_CONTEXTS=5 # Max concurrent browser contexts
PLAYWRIGHT_TIMEOUT=30000 # Page load timeout in ms
PLAYWRIGHT_DISABLE_GPU=true # Reduce memory in containers
# MCP features (disabled by default to reduce context overhead)
ENABLE_RESOURCES=true # Enable MCP resources
ENABLE_PROMPTS=true # Enable MCP prompts
# Proxy (optional)
HTTP_PROXY=http://proxy.example.com:8080
HTTPS_PROXY=http://proxy.example.com:8080
# ScrapeOps proxy service (optional)
SCRAPEOPS_API_KEY=your_key_here
SCRAPEOPS_RENDER_JS=true
See Configuration Guide for all options.
Add to your MCP settings:
{
"mcpServers": {
"scraper": {
"url": "http://localhost:8000/mcp"
}
}
}
This project includes Agent Skills that provide Claude Code with specialized knowledge for using the scraper tools effectively.
| Skill | Description |
|---|---|
| web-scraping | CSS selectors, batch operations, retry configuration |
| perplexity | AI search, reasoning tasks, conversation patterns |
Copy the skills to your Claude Code skills directory:
# Clone or download this repo, then:
cp -r .claude/skills/web-scraping ~/.claude/skills/
cp -r .claude/skills/perplexity ~/.claude/skills/
Or install directly:
# web-scraping skill
mkdir -p ~/.claude/skills/web-scraping
curl -o ~/.claude/skills/web-scraping/SKILL.md \
https://raw.githubusercontent.com/cotdp/scraper-mcp/main/.claude/skills/web-scraping/SKILL.md
# perplexity skill
mkdir -p ~/.claude/skills/perplexity
curl -o ~/.claude/skills/perplexity/SKILL.md \
https://raw.githubusercontent.com/cotdp/scraper-mcp/main/.claude/skills/perplexity/SKILL.md
Once installed, Claude Code will automatically use these skills when performing web scraping or Perplexity AI tasks.
| Document | Description |
|---|---|
| API Reference | Complete tool documentation, parameters, CSS selectors |
| Configuration | Environment variables, proxy setup, ScrapeOps |
| Dashboard | Monitoring UI, playground, runtime config |
| Development | Local setup, architecture, contributing |
| Testing | Test suite, coverage, adding tests |
# Install
uv pip install -e ".[dev]"
# Run
python -m scraper_mcp
# Test
pytest
# Lint
ruff check . && mypy src/
See Development Guide for details.
MIT License
Last updated: December 23, 2025
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows