

Are you the author? Sign in to claim
Official Implementation of UA^{2}-Agent and other baseline algorithms of "Towards Unified Alignment Between Agents, Huma
🚀 This repo implements the preliminary version of agents designed under Unified Alignment for Agents (UA$^2$) framework with results benchmarked on UA$^2$-Webshop.
🚀 The project is a practice of LLM-powered agent framework design under the guidance of Towards Unified Alignment Between Agents, Humans, and Environment.
If you find this repo useful, please cite our project:
@article{yang2024towards,
title = {Towards Unified Alignment Between Agents, Humans, and Environment},
author = {Yang, Zonghan and Liu, An and Liu, Zijun and Liu, Kaiming and Xiong, Fangzhou and Wang, Yile and Yang, Zeyuan and Hu, Qingyuan and Chen, Xinrui and Zhang, Zhenhe and Luo, Fuwen and Guo, Zhicheng and Li, Peng and Liu, Yang},
journal={arXiv preprint arXiv:2402.07744},
year = {2024}
}
$$$$
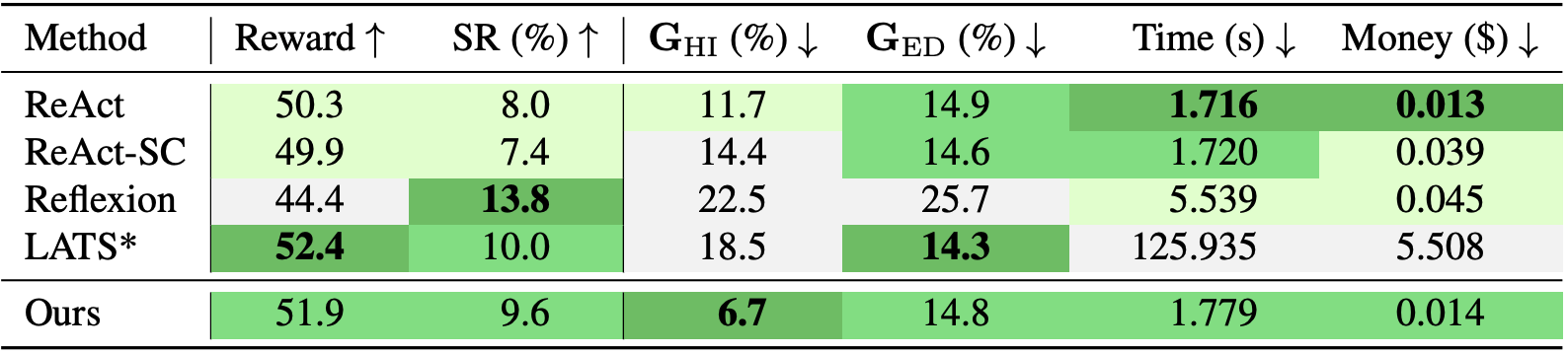
🎡 Methods used for comparison:
To be specific, the key contribution of our UA$^2$ principles to the LLM-powered agent research community is the concept of alignment rooted in the agent-assisting process. In UA$^2$-Webshop, the requirements of alignment originates from different sources. To name a few:
Kindly refer to the online article for detailed depiction on how we introduce those requirements. The live site demo can be found here, as well as the environment repo for local deployment purpose.
These requirements are already reflected by the task and the website design of UA$^2$-Webshop. In this repo, we wrap the environment with runtime information (time and money) to compute the resource consumptions of an LLM-powered agent.
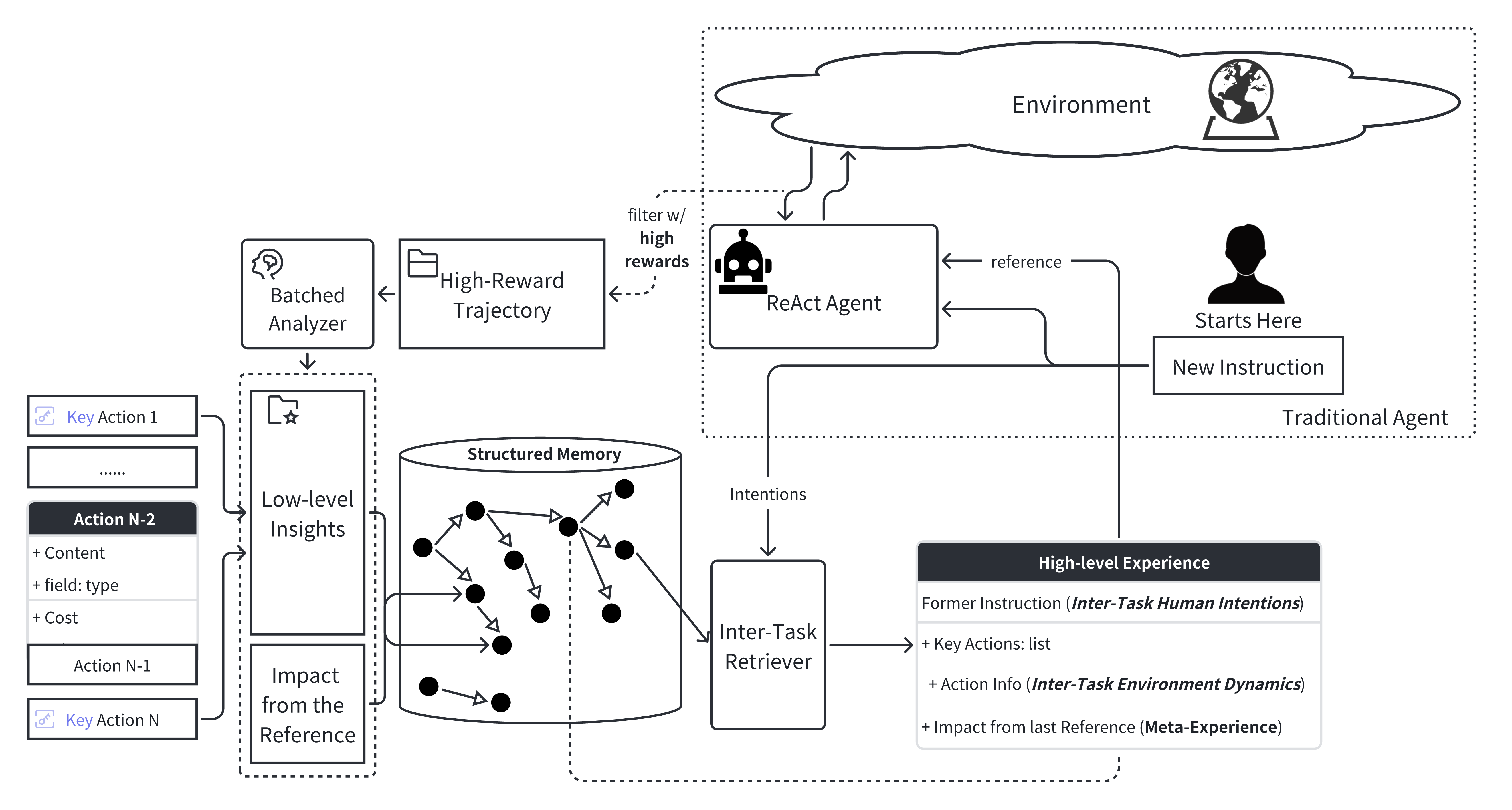
The key challenge is to build an agent framework that manages to assist the decision process in a realistic environment, in consideration of different principles of alignment. We leverage a structured memory with low-level insights to make better decisions upon ReACT agents.
$$$$
Low-level action insights are a list of key actions solicited from different runs in the environment under the same task instruction. The key actions are extracted from the high-reward trajectories with an analyzer, with which the contributions of actions are computed in the task-solving process.
💡 Here are the ways we follow the UA$^2$ principles:
Two major modules:
Analyzer part:
Memory part:
Experimence accumulation with a specific user
Structured representation for instruction relations: references points to the actual trajectory of a task
Using semantic similarities for inter-task retrieval
Direct action extrapolation from the key action list
(For better efficiency, we only utilize the best matched profile as a reference in decision making)
./ua2-agent: the core of our UA$^2$-Agent framework
Insight.py: the implementation of Analyzer partProfiler.py: the implementation of Memory partreact_w_insights_w_profiler_v1benchmark.py: the implementation of our UA$^2$-Agent algorithm on UA$^2$-Webshop benchmark./environments: running environment of our UA$^2$-Webshop benchmark (the encapsulation of our core environment)
env_instr_list_ua2webshop_runtime_session.py: the capsule of run-time environment leveraging cost information for UA$^2$-Webshop benchmark./baselines: source code of baselines
README.md: the instruction of how to run baselines and implementation detailsPrepare for the conda environment:
conda create -n ua2
pip install -r requirements.txt
conda activate ua2
Add your OpenAI API key to your environment:
# on Linux/Mac
export OPENAI_API_KEY=<YOUR_API_KEY>
# on Windows
set OPENAI_API_KEY=<YOUR_API_KEY>
For Reflexion, ReAct-series and CoT-series baselines, change your working directory and run the corresponding script directly:
cd baselines
python cot_least_to_most.py
python cot_sc.py
python react.py
python react_sc.py
For LATS baselines:
cd baselines/lats
mkdir runtime_logs
./lats.sh
For Reflexion:
cd baselines/reflexion
./reflexion.sh
To test our method:
cd code
python react_w_insights_w_profiler_v1benchmark.py
After running the script, the results can be found in the directory ./runtime_logs. More details can be found in ./baselines/README.md.
This project is advised by Peng Li (lipeng@air.tsinghua.edu.cn) and Yang Liu (liuyang2011@tsinghua.edu.cn).
We look forward to all kinds of suggestions from anyone interested in our project with whatever backgrounds! Either PRs, issues, or leaving a message is welcomed. We'll be sure to follow up shortly!
⚠️ Experimentelle Skill-Sammlung für deutsches Recht (Arbeits-, Gesellschafts-, Insolvenz-, Datenschutz-, Prozessrecht u
Manage multiple Claude Code agents from TUI or Web with tmux and git worktrees
Project management using GitHub Issues + Git worktrees for parallel agent execution
Core skills library for Claude Code with 20+ battle-tested skills including TDD, debugging, and brainstorming