

Are you the author? Sign in to claim
xLAM: A Family of Large Action Models to Empower AI Agent Systems

![]()
![]()
Paper | Model Instruction | Framework | Installation | Train | Benchmarks | Acknowledgement
Note: This repository is provided for research purposes only.
Any data related to xLAM is partially released due to internal regulations to support the advancement of the agent research community.
Autonomous agents powered by large language models (LLMs) have garnered significant research attention. However, fully harnessing the potential of LLMs for agent-based tasks presents inherent challenges due to the heterogeneous nature of diverse data sources featuring multi-turn trajectories.
This repo introduces xLAM that aggregates agent trajectories from distinct environments, spanning a wide array of scenarios. It standardizes and unifies these trajectories into a consistent format, streamlining the creation of a generic data loader optimized for agent training. Leveraging the data unification, our training pipeline maintains equilibrium across different data sources and preserves independent randomness across devices during dataset partitioning and model training.
| Model | # Total Params | Context Length | Release Date | Category | Download Model | Download GGUF files |
|---|---|---|---|---|---|---|
| Llama-xLAM-2-70b-fc-r | 70B | 128k | Mar. 26, 2025 | Multi-turn Conversation, Function-calling | 🤗 Link | NA |
| Llama-xLAM-2-8b-fc-r | 8B | 128k | Mar. 26, 2025 | Multi-turn Conversation, Function-calling | 🤗 Link | 🤗 Link |
| xLAM-2-32b-fc-r | 32B | 32k (max 128k)* | Mar. 26, 2025 | Multi-turn Conversation, Function-calling | 🤗 Link | NA |
| xLAM-2-3b-fc-r | 3B | 32k (max 128k)* | Mar. 26, 2025 | Multi-turn Conversation, Function-calling | 🤗 Link | 🤗 Link |
| xLAM-2-1b-fc-r | 1B | 32k (max 128k)* | Mar. 26, 2025 | Multi-turn Conversation, Function-calling | 🤗 Link | 🤗 Link |
| xLAM-7b-r | 7.24B | 32k | Sep. 5, 2024 | General, Function-calling | 🤗 Link | -- |
| xLAM-8x7b-r | 46.7B | 32k | Sep. 5, 2024 | General, Function-calling | 🤗 Link | -- |
| xLAM-8x22b-r | 141B | 64k | Sep. 5, 2024 | General, Function-calling | 🤗 Link | -- |
| xLAM-1b-fc-r | 1.35B | 16k | July 17, 2024 | Function-calling | 🤗 Link | 🤗 Link |
| xLAM-7b-fc-r | 6.91B | 4k | July 17, 2024 | Function-calling | 🤗 Link | 🤗 Link |
| xLAM-v0.1-r | 46.7B | 32k | Mar. 18, 2024 | General, Function-calling | 🤗 Link | -- |
xLAM series are significant better at many things including general tasks and function calling. For the same number of parameters, the model have been fine-tuned across a wide range of agent tasks and scenarios, all while preserving the capabilities of the original model.
xLAM-7b-r: A general-purpose v1.0 or v2.0 release of the Large Action Model, fine-tuned for broad agentic capabilities. The -r suffix indicates it is a research release.xLAM-7b-fc-r: A specialized variant where -fc denotes fine-tuning for function calling tasks, also marked for research use.Below is one example on how to use the latest models:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r")
model = AutoModelForCausalLM.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r", torch_dtype=torch.bfloat16, device_map="auto")
# Example conversation with a tool call
messages = [
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "Thanks. I am doing well. How can I help you?"},
{"role": "user", "content": "What's the weather like in London?"},
]
tools = [
{
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit of temperature to return"}
},
"required": ["location"]
}
}
]
print("====== prompt after applying chat template ======")
print(tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, tokenize=False))
inputs = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
input_ids_len = inputs["input_ids"].shape[-1] # Get the length of the input tokens
inputs = {k: v.to(model.device) for k, v in inputs.items()}
print("====== model response ======")
outputs = model.generate(**inputs, max_new_tokens=256)
generated_tokens = outputs[:, input_ids_len:] # Slice the output to get only the newly generated tokens
print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True))
Note: You may need to tune the Temperature setting for different applications. Typically, a lower Temperature is helpful for tasks that require deterministic outcomes. Additionally, for tasks demanding adherence to specific formats or function calls, explicitly including formatting instructions is advisable and important.
The xLAM models can also be efficiently served using vLLM for high-throughput inference. Please use vllm>=0.6.5 since earlier versions will cause degraded performance for Qwen-based models.
pip install "vllm>=0.6.5"
wget https://huggingface.co/Salesforce/xLAM-2-1b-fc-r/raw/main/xlam_tool_call_parser.py
MODEL_NAME_OR_PATH="Salesforce/xLAM-2-1b-fc-r"
ASSIGNED_MODEL_NAME="xlam-2-1b-fc-r" # vLLM uses the assigned model name for reference
NUM_ASSIGNED_GPUS=1 # a 70b model would need 4 GPUs, each with 80GB memory
PORT=8000
vllm serve $MODEL_NAME_OR_PATH \
--tensor-parallel-size $NUM_ASSIGNED_GPUS \
--served-model-name $ASSIGNED_MODEL_NAME \
--port $PORT \
--gpu-memory-utilization 0.9 \
--enable-auto-tool-choice \
--tool-parser-plugin ./xlam_tool_call_parser.py \
--tool-call-parser xlam
Note: Ensure that the tool parser plugin file is downloaded and that the path specified in --tool-parser-plugin correctly points to your local copy of the file. The xLAM series models all utilize the same tool call parser, so you only need to download it once for all models.
Here's a minimal example to test tool usage with the served endpoint:
import openai
import json
# Configure the client to use your local vLLM endpoint
client = openai.OpenAI(
base_url="http://localhost:8000/v1", # Default vLLM server PORT
api_key="empty" # Can be any string
)
# Define a tool/function
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return"
}
},
"required": ["location"]
}
}
}
]
messages = [
{"role": "system", "content": "You are a helpful assistant that can use tools."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
]
# Create a chat completion
if tools is None or tools==[]: # chitchat
response = client.chat.completions.create(
model="xlam-2-1b-fc-r", # ASSIGNED_MODEL_NAME
messages=messages
)
else: # function calling
response = client.chat.completions.create(
model="xlam-2-1b-fc-r", # ASSIGNED_MODEL_NAME
messages=messages,
tools=tools,
tool_choice="auto"
)
# Print the response
print("Assistant's response:")
print(json.dumps(response.model_dump(), indent=2))
For more advanced configurations and deployment options, please refer to the vLLM documentation.
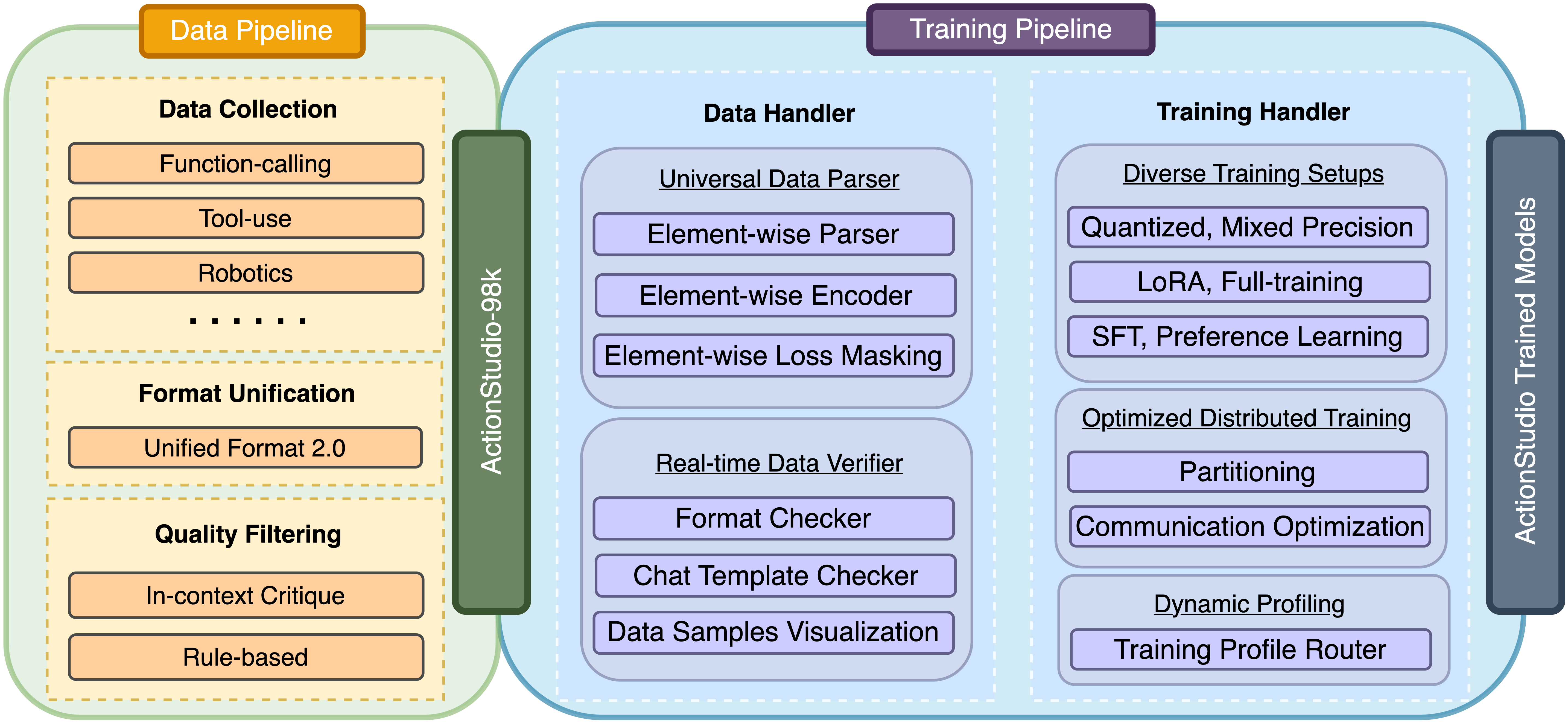
❤️ Please refer ActionStudio.md for more details.
Install dependencies from the root xLAM directory (where setup.py is located) with:
conda create --name actionstudio python=3.10
bash requirements.sh
Development Version (Latest):
To use the latest code under active development, install ActionStudio in editable mode from the root xLAM directory (where setup.py is located):
pip install -e .
actionstudio/
├── datasets/ # Open-source **`unified trajectory datasets`**
├── examples/ # Usage examples and configurations
│ ├── data_configs/ # YAML configs for data mixtures
│ ├── deepspeed_configs/ # DeepSpeed training configuration files
│ └── trainings/ # Bash scripts for various training methods (**`README.md`**)
├── src/ # Source code
│ ├── data_conversion/ # Converting trajectories into training data (**`README.md`**)
│ └── criticLAM/ # Critic Large Action Model implementation (**`README.md`**)
└── foundation_modeling/ # Core modeling components
├── data_handlers/
├── train/
├── trainers/
└── utils/
🔍 Most top-level folders include a README.md with detailed instructions and explanations.
The code is licensed under Apache 2.0, and the datasets are under the CC-BY-NC-4.0 License. The data provided are intended for research purposes only.
Unified config tracking Every run now writes its full training configuration to a single JSON file—keyed by a unique model ID—in model_config_files for easy reference and reproducibility.
HF ⇄ DeepSpeed parity Resolved inconsistencies between Hugging Face and DeepSpeed hyper-parameter settings to ensure they stay perfectly in sync.
Learning-rate scheduler tuning Refined default scheduler parameters for smoother warm-up and steadier convergence.
General code cleanup Streamlined modules, removed dead paths, and added inline docs for easier maintenance.

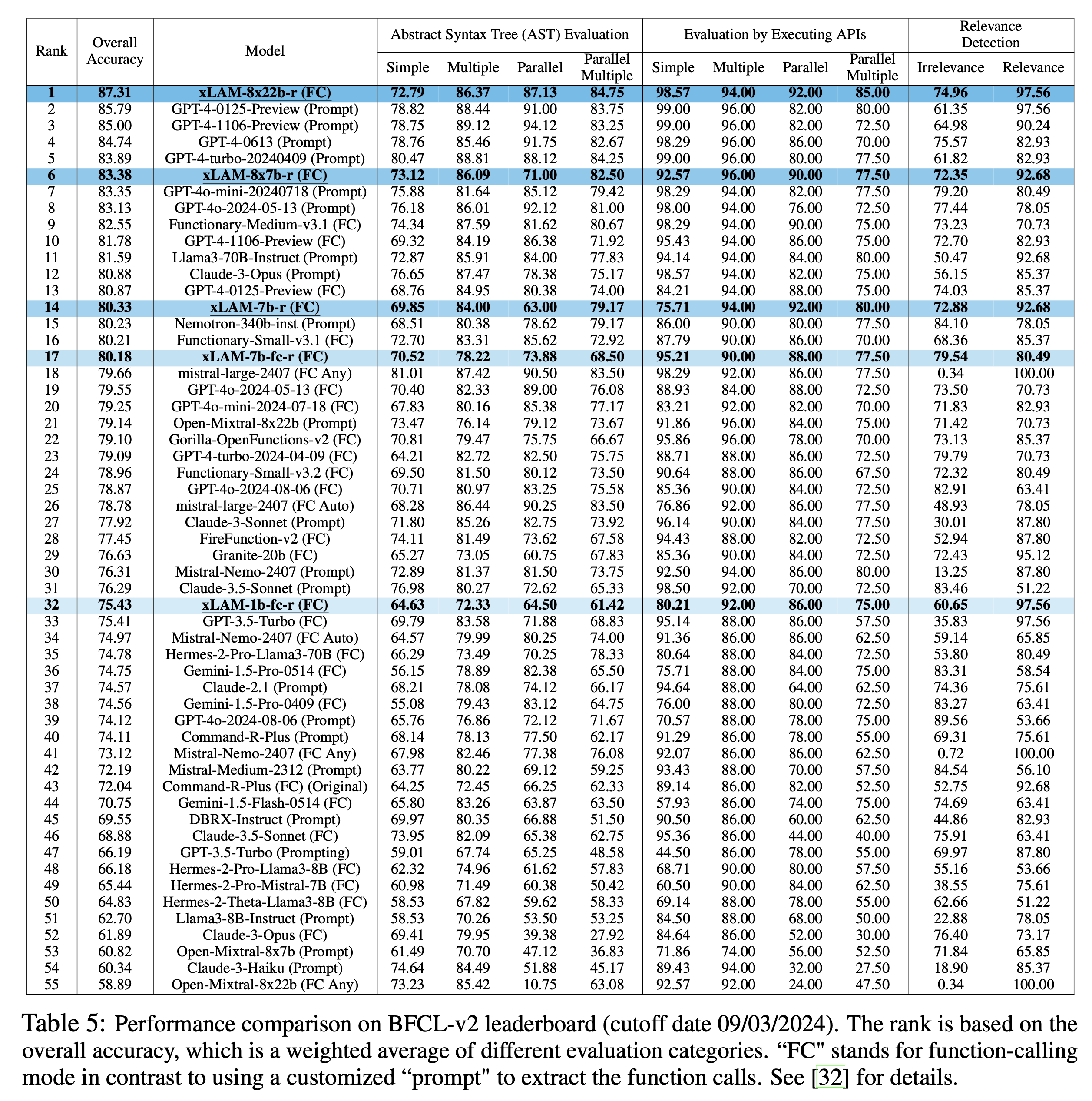
Performance comparison of different models on BFCL leaderboard. The rank is based on the overall accuracy, which is a weighted average of different evaluation categories. "FC" stands for function-calling mode in contrast to using a customized "prompt" to extract the function calls.

Success Rate (pass@1) on τ-bench benchmark averaged across at least 5 trials. Our xLAM-2-70b-fc-r model achieves an overall success rate of 56.2% on τ-bench, significantly outperforming the base Llama 3.1 70B Instruct model (38.2%) and other open-source models like DeepSeek v3 (40.6%). Notably, our best model even outperforms proprietary models such as GPT-4o (52.9%) and approaches the performance of more recent models like Claude 3.5 Sonnet (new) (60.1%).

Pass^k curves measuring the probability that all 5 independent trials succeed for a given task, averaged across all tasks for τ-retail (left) and τ-airline (right) domains. Higher values indicate better consistency of the models.
| LLM Name | ZS | ZST | ReaAct | PlanAct | PlanReAct | BOLAA |
|---|---|---|---|---|---|---|
| Llama-2-70B-chat | 0.0089 | 0.0102 | 0.4273 | 0.2809 | 0.3966 | 0.4986 |
| Vicuna-33B | 0.1527 | 0.2122 | 0.1971 | 0.3766 | 0.4032 | 0.5618 |
| Mixtral-8x7B-Instruct-v0.1 | 0.4634 | 0.4592 | 0.5638 | 0.4738 | 0.3339 | 0.5342 |
| GPT-3.5-Turbo | 0.4851 | 0.5058 | 0.5047 | 0.4930 | 0.5436 | 0.6354 |
| GPT-3.5-Turbo-Instruct | 0.3785 | 0.4195 | 0.4377 | 0.3604 | 0.4851 | 0.5811 |
| GPT-4-0613 | 0.5002 | 0.4783 | 0.4616 | 0.7950 | 0.4635 | 0.6129 |
| xLAM-v0.1-r | 0.5201 | 0.5268 | 0.6486 | 0.6573 | 0.6611 | 0.6556 |
| LLM Name | ZS | ZST | ReaAct | PlanAct | PlanReAct |
|---|---|---|---|---|---|
| Mixtral-8x7B-Instruct-v0.1 | 0.3912 | 0.3971 | 0.3714 | 0.3195 | 0.3039 |
| GPT-3.5-Turbo | 0.4196 | 0.3937 | 0.3868 | 0.4182 | 0.3960 |
| GPT-4-0613 | 0.5801 | 0.5709 | 0.6129 | 0.5778 | 0.5716 |
| xLAM-v0.1-r | 0.5492 | 0.4776 | 0.5020 | 0.5583 | 0.5030 |
Please note: All prompts provided by AgentLite are considered "unseen prompts" for xLAM-v0.1-r, meaning the model has not been trained with data related to these prompts.
| LLM Name | Act | ReAct | BOLAA |
|---|---|---|---|
| GPT-3.5-Turbo-16k | 0.6158 | 0.6005 | 0.6652 |
| GPT-4-0613 | 0.6989 | 0.6732 | 0.7154 |
| xLAM-v0.1-r | 0.6563 | 0.6640 | 0.6854 |
| Easy | Medium | Hard | ||||
|---|---|---|---|---|---|---|
| LLM Name | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | Accuracy |
| GPT-3.5-Turbo-16k-0613 | 0.410 | 0.350 | 0.330 | 0.25 | 0.283 | 0.20 |
| GPT-4-0613 | 0.611 | 0.47 | 0.610 | 0.480 | 0.527 | 0.38 |
| xLAM-v0.1-r | 0.532 | 0.45 | 0.547 | 0.46 | 0.455 | 0.36 |
| LLM Name | Unseen Insts & Same Set | Unseen Tools & Seen Cat | Unseen Tools & Unseen Cat |
|---|---|---|---|
| TooLlama V2 | 0.4385 | 0.4300 | 0.4350 |
| GPT-3.5-Turbo-0125 | 0.5000 | 0.5150 | 0.4900 |
| GPT-4-0125-preview | 0.5462 | 0.5450 | 0.5050 |
| xLAM-v0.1-r | 0.5077 | 0.5650 | 0.5200 |
| LLM Name | 1-step | 2-step | 3-step | 4-step | 5-step |
|---|---|---|---|---|---|
| GPT-4-0613 | - | - | - | - | 69.45 |
| Claude-Instant-1 | 12.12 | 32.25 | 39.25 | 44.37 | 45.90 |
| xLAM-v0.1-r | 4.10 | 28.50 | 36.01 | 42.66 | 43.96 |
| Claude-2 | 26.45 | 35.49 | 36.01 | 39.76 | 39.93 |
| Lemur-70b-Chat-v1 | 3.75 | 26.96 | 35.67 | 37.54 | 37.03 |
| GPT-3.5-Turbo-0613 | 2.73 | 16.89 | 24.06 | 31.74 | 36.18 |
| AgentLM-70b | 6.48 | 17.75 | 24.91 | 28.16 | 28.67 |
| CodeLlama-34b | 0.17 | 16.21 | 23.04 | 25.94 | 28.16 |
| Llama-2-70b-chat | 4.27 | 14.33 | 15.70 | 16.55 | 17.92 |
| LLM Name | Success Rate | Progress Rate |
|---|---|---|
| xLAM-v0.1-r | 0.533 | 0.766 |
| DeepSeek-67B | 0.400 | 0.714 |
| GPT-3.5-Turbo-0613 | 0.367 | 0.627 |
| GPT-3.5-Turbo-16k | 0.317 | 0.591 |
| Lemur-70B | 0.283 | 0.720 |
| CodeLlama-13B | 0.250 | 0.525 |
| CodeLlama-34B | 0.133 | 0.600 |
| Mistral-7B | 0.033 | 0.510 |
| Vicuna-13B-16K | 0.033 | 0.343 |
| Llama-2-70B | 0.000 | 0.483 |
This code is licensed under Apache 2.0. For models based on the deepseek model, which require you to follow the use based restrictions in the linked deepseek license. This is a research only project.
We want to acknowledge the work which have made contributions to our paper and the agent research community! If you find our work useful, please consider to cite
@article{zhang2024xlamfamilylargeaction,
title={xLAM: A Family of Large Action Models to Empower AI Agent Systems},
author={Zhang, Jianguo and Lan, Tian and Zhu, Ming and Liu, Zuxin and Hoang, Thai and Kokane, Shirley and Yao, Weiran and Tan, Juntao and Prabhakar, Akshara and Chen, Haolin and Liu, Zhiwei and Feng, Yihao and Awalgaonkar, Tulika and Murthy, Rithesh and Hu, Eric and Chen, Zeyuan and Xu, Ran and Niebles, Juan Carlos and Heinecke, Shelby and Wang, Huan and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2409.03215}
year={2024}
}
@article{zhang2025actionstudio,
title={ActionStudio: A Lightweight Framework for Data and Training of Action Models},
author={Zhang, Jianguo and Hoang, Thai and Zhu, Ming and Liu, Zuxin and Wang, Shiyu and Awalgaonkar, Tulika and Prabhakar, Akshara and Chen, Haolin and Yao, Weiran and Liu, Zhiwei and others},
journal={arXiv preprint arXiv:2503.22673},
year={2025}
}
@article{prabhakar2025apigen,
title={APIGen-MT: Agentic PIpeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay},
author={Prabhakar, Akshara and Liu, Zuxin and Zhu, Ming and Zhang, Jianguo and Awalgaonkar, Tulika and Wang, Shiyu and Liu, Zhiwei and Chen, Haolin and Hoang, Thai and others},
journal={arXiv preprint arXiv:2504.03601},
year={2025}
}
@article{liu2024apigen,
title={APIGen: Automated PIpeline for Generating Verifiable and Diverse Function-Calling Datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Kokane, Shirley and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and others},
journal={arXiv preprint arXiv:2406.18518},
year={2024}
}
@article{zhang2024agentohana,
title={AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning},
author={Zhang, Jianguo and Lan, Tian and Murthy, Rithesh and Liu, Zhiwei and Yao, Weiran and Tan, Juntao and Hoang, Thai and Yang, Liangwei and Feng, Yihao and Liu, Zuxin and others},
journal={arXiv preprint arXiv:2402.15506},
year={2024}
}
191 agents, 155 skills, and 82 plugins cross-compatible with Claude Code, Cursor, and Codex
⚠️ Experimentelle Skill-Sammlung für deutsches Recht (Arbeits-, Gesellschafts-, Insolvenz-, Datenschutz-, Prozessrecht u
Manage multiple Claude Code agents from TUI or Web with tmux and git worktrees
Project management using GitHub Issues + Git worktrees for parallel agent execution
