

Are you the author? Sign in to claim
Cognitive memory database for AI agents — consolidates duplicates, detects contradictions, fades stale memories via temp
⚠ Correction notice (2026-04-19): Phase 3 benchmark writeups committed earlier today (
docs/phase3a/,docs/phase3b/,docs/phase3c/,docs/phase3d/) used a Python simulator for the "structured memory" condition — NOT the actual yantrikdb engine. Rerun with real yantrikdb is indocs/phase3e/. Full audit trail inCORRECTIONS.md. Full corrected findings post coming 2026-04-20.
A memory database that forgets, consolidates, and detects contradictions.
Vector databases store memories. They don't manage them. After 10,000 memories, recall quality degrades because there's no consolidation, no forgetting, no conflict resolution. Your AI agent just gets noisier.
YantrikDB is different. It's a cognitive memory engine — embed it, run it as a server, or connect via MCP. It thinks about what it stores.
Shortest path to try it: MCP setup for Claude Code / Cursor / Windsurf → (one pip install, one config block).
The bigger picture: YantrikDB is the memory layer being built on the road to YantrikOS — an AI-native operating system where agents are first-class primitives, not apps on top. Memory was the bottleneck, so we're shipping it first.


![]()
📄 New paper (May 2026): Skill as Memory, Not Document — measuring three failure modes when agent skill catalogs scale to 5,000 skills. Code + raw CSVs reproducible in
benchmarks/skill_recall/.
| Memories | File-Based (CLAUDE.md) | YantrikDB | Token Savings | Recall Precision |
|---|---|---|---|---|
| 100 | 1,770 tokens | 69 tokens | 96% | 66% |
| 500 | 9,807 tokens | 72 tokens | 99.3% | 77% |
| 1,000 | 19,988 tokens | 72 tokens | 99.6% | 84% |
| 5,000 | 101,739 tokens | 53 tokens | 99.9% | 88% |
At 500 memories, file-based memory exceeds 32K context. At 5,000, it doesn't fit in any model — not even 200K. YantrikDB stays at ~70 tokens per query. Precision improves with more data — the opposite of context stuffing.
Reproduce: python benchmarks/bench_token_savings.py
db.record("read the SLA doc by Friday", importance=0.4, half_life=86400) # 1 day
# 24 hours later, this memory's relevance score has decayed
# 7 days later, recall stops surfacing it unless explicitly queried
# 20 similar memories about the same meeting
for note in meeting_notes:
db.record(note, namespace="standup-2026-04-12")
db.think()
# → {"consolidation_count": 5} # collapsed 20 fragments into 5 canonical memories
db.record("CEO is Alice")
db.record("CEO is Bob") # added later in another conversation
db.think()
# → {"conflicts_found": 1, "conflicts": [{"memory_a": "CEO is Alice",
# "memory_b": "CEO is Bob",
# "type": "factual_contradiction"}]}
Plus: temporal decay with configurable half-life, entity graph with relationship edges, personality derivation from memory patterns, session-aware context surfacing, multi-signal scoring (recency × importance × similarity × graph proximity).
YantrikDB isn't just storage with operations. The engine has a layer that makes agents feel less reactive:
stale surfaces important memories that haven't been touched recently. upcoming surfaces memories with approaching deadlines.Full cognitive architecture lives in the standalone engine repo. This server repo focuses on deployment, HTTP API, and cluster operations.
The fastest adoption path. One pip install, one config block, and your agent gets persistent memory that auto-recalls on conversation start, auto-remembers decisions, and flags contradictions — without you prompting it.
pip install yantrikdb-mcp
Add this to your MCP client config — typically ~/.claude.json or .mcp.json in your project for Claude Code, and the equivalent mcp block in settings for Cursor/Windsurf (Claude Code · Cursor · Windsurf):
{
"mcpServers": {
"yantrikdb": {
"command": "yantrikdb-mcp"
}
}
}
That's it. No env vars. Uses a local SQLite memory file at ~/.yantrikdb/memory.db. First call auto-initializes the schema. Restart your client — the yantrikdb MCP server will show up with 15 memory tools (see below).
Want a shared memory across machines or teammates? Point at a YantrikDB cluster instead of local SQLite:
{
"mcpServers": {
"yantrikdb": {
"command": "yantrikdb-mcp",
"env": {
"YANTRIKDB_SERVER_URL": "http://node1:7438,http://node2:7438",
"YANTRIKDB_TOKEN": "ydb_your_database_token"
}
}
}
}
Want it over HTTP/SSE instead of stdio? (For IDE integrations that don't support stdio MCP servers.)
{
"mcpServers": {
"yantrikdb": {
"type": "sse",
"url": "http://your-server:8420/sse",
"headers": { "Authorization": "Bearer YOUR_API_KEY" }
}
}
}
Then start: yantrikdb-mcp --transport sse --port 8420.
| Tools | |
|---|---|
| Core memory | remember · recall · forget · correct |
| Cognition | think (consolidate + conflict-detect) · memory · trigger (proactive insights) |
| Knowledge graph | graph (entities + relations) · category |
| Conflicts & corrections | conflict (list + resolve contradictions) |
| Time | session · temporal (stale/upcoming queries) |
| Behavior | procedure (strategies) · personality (derived traits) |
| Ops | stats (engine health + diagnostics) |
Full tool reference and agent-integration patterns: yantrikdb-mcp → · docs
docker run -p 7438:7438 ghcr.io/yantrikos/yantrikdb:latest
curl -X POST http://localhost:7438/v1/remember -d '{"text":"hello"}'
Single Rust binary. HTTP + binary wire protocol. 2-voter + 1-witness HA cluster via Docker Compose or Kubernetes. Per-tenant quotas, Prometheus metrics, AES-256-GCM at-rest encryption, runtime deadlock detection. See docker-compose.cluster.yml and k8s manifests.
pip install yantrikdb
# or
cargo add yantrikdb
import yantrikdb
db = yantrikdb.YantrikDB("memory.db", embedding_dim=384)
db.set_embedder(SentenceTransformer("all-MiniLM-L6-v2"))
db.record("Alice leads engineering", importance=0.8)
db.recall("who leads the team?", top_k=3)
db.think() # consolidate, detect conflicts, derive personality
Live numbers from a 2-core LXC cluster with 1689 memories:
| Operation | Latency |
|---|---|
| Recall p50 | 112ms (most is query embedding ~100ms) |
| Recall p99 | 190ms |
| Batch write | 76 writes/sec |
| Engine lock acquire | <0.1ms |
| Deep health probe | <1ms |
For pre-computed embeddings (skip query-time embedding), recall p50 drops to ~5ms.
v0.5.13 — hardened alpha + RFC 006 Phase 0 observability telemetry shipped. The embeddable engine has been used in production by the YantrikOS ecosystem since early 2026. The network server runs live on a 3-node Proxmox cluster with multiple tenants.
A 42-task hardening sprint just completed across 8 epics:
parking_lot mutexes everywhere with runtime deadlock detection (caught a self-deadlock that would have taken hours to find with std::sync)Read the maturity notes: https://yantrikdb.com/server/quickstart/#maturity
Current AI memory is:
Store everything → Embed → Retrieve top-k → Inject into context → Hope it helps.
That's not memory. That's a search engine with extra steps.
Real memory is hierarchical, compressed, contextual, self-updating, emotionally weighted, time-aware, and predictive. YantrikDB is built for that.
| Solution | What it does | What it lacks |
|---|---|---|
| Vector DBs (Pinecone, Weaviate) | Nearest-neighbor lookup | No decay, no causality, no self-organization |
| Knowledge Graphs (Neo4j) | Structured relations | Poor for fuzzy memory, not adaptive |
| Memory Frameworks (LangChain, Mem0) | Retrieval wrappers | Not a memory architecture — just middleware |
| File-based (CLAUDE.md, memory files) | Dump everything into context | O(n) token cost, no relevance filtering |
| Memories | File-Based | YantrikDB | Token Savings | Precision |
|---|---|---|---|---|
| 100 | 1,770 tokens | 69 tokens | 96% | 66% |
| 500 | 9,807 tokens | 72 tokens | 99.3% | 77% |
| 1,000 | 19,988 tokens | 72 tokens | 99.6% | 84% |
| 5,000 | 101,739 tokens | 53 tokens | 99.9% | 88% |
At 500 memories, file-based exceeds 32K context windows. At 5,000, it doesn't fit in any context window — not even 200K. YantrikDB stays at ~70 tokens per query. Precision improves with more data — the opposite of context stuffing.
record(), recall(), relate(), not SELECTSend + Sync with internal Mutex/RwLock, safe for concurrent access┌──────────────────────────────────────────────────────┐
│ YantrikDB Engine │
│ │
│ ┌──────────┬──────────┬──────────┬──────────┐ │
│ │ Vector │ Graph │ Temporal │ Decay │ │
│ │ (HNSW) │(Entities)│ (Events) │ (Heap) │ │
│ └──────────┴──────────┴──────────┴──────────┘ │
│ ┌──────────┐ │
│ │ Key-Value│ WAL + Replication Log (CRDT) │
│ └──────────┘ │
└──────────────────────────────────────────────────────┘
| Type | What it stores | Example |
|---|---|---|
| Semantic | Facts, knowledge | "User is a software engineer at Meta" |
| Episodic | Events with context | "Had a rough day at work on Feb 20" |
| Procedural | Strategies, what worked | "Deploy with blue-green, not rolling update" |
All memories carry importance, valence (emotional tone), domain, source, certainty, and timestamps — used in a multi-signal scoring function that goes far beyond cosine similarity.
Not just vector similarity. Every recall combines:
Weights are tuned automatically from usage patterns.
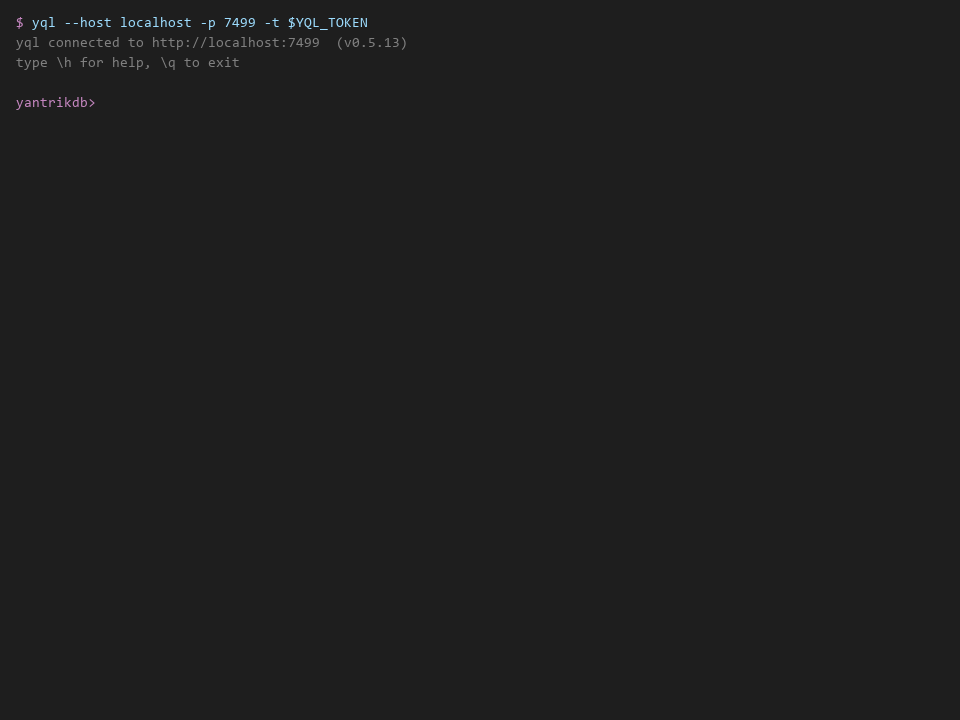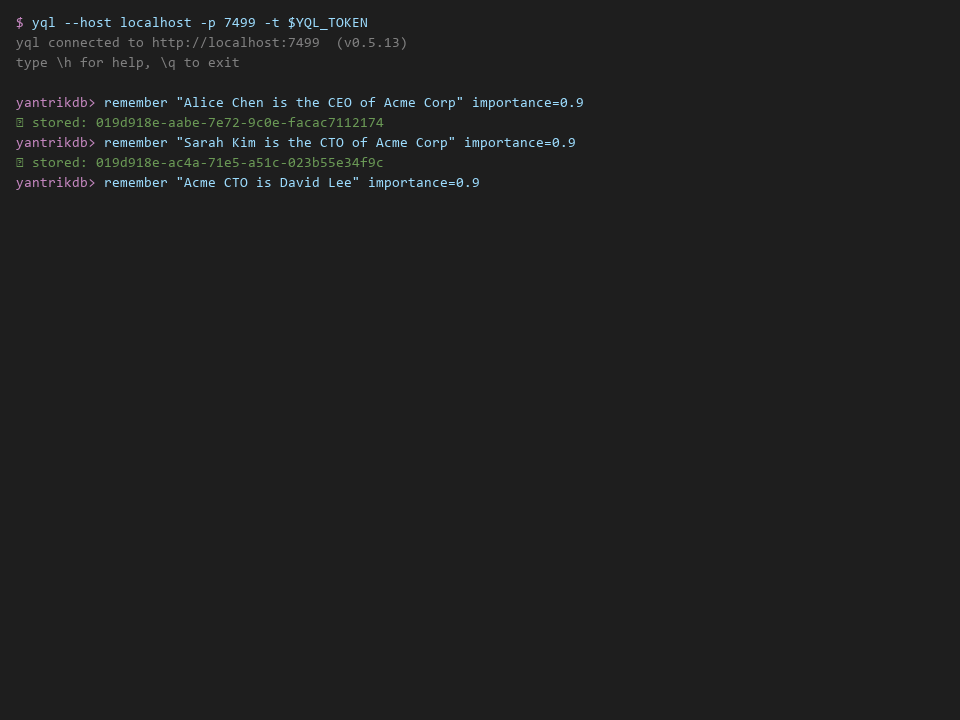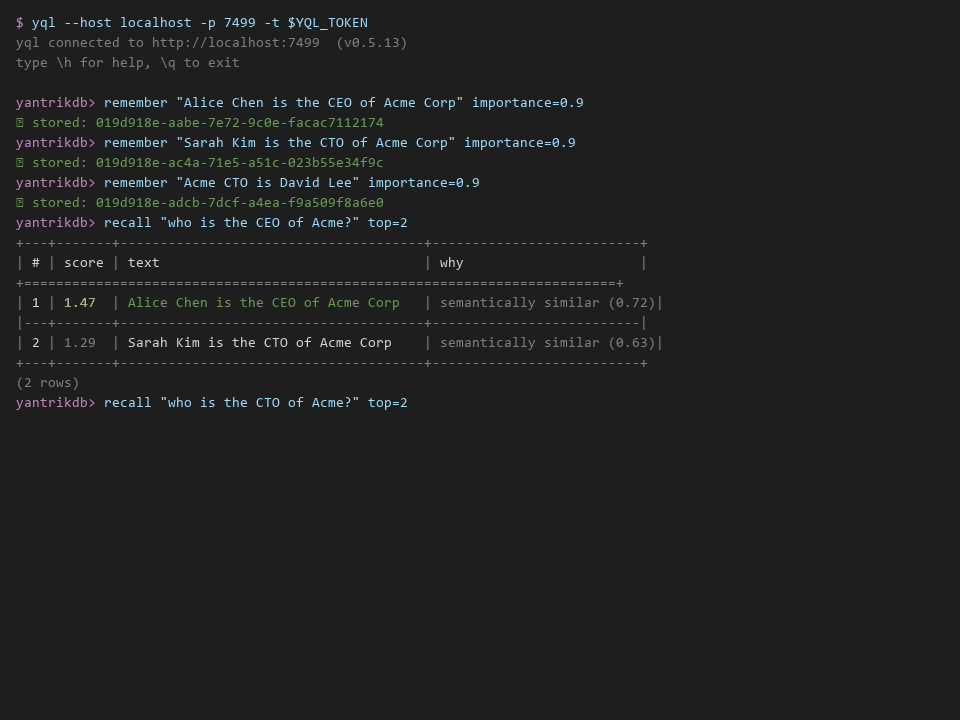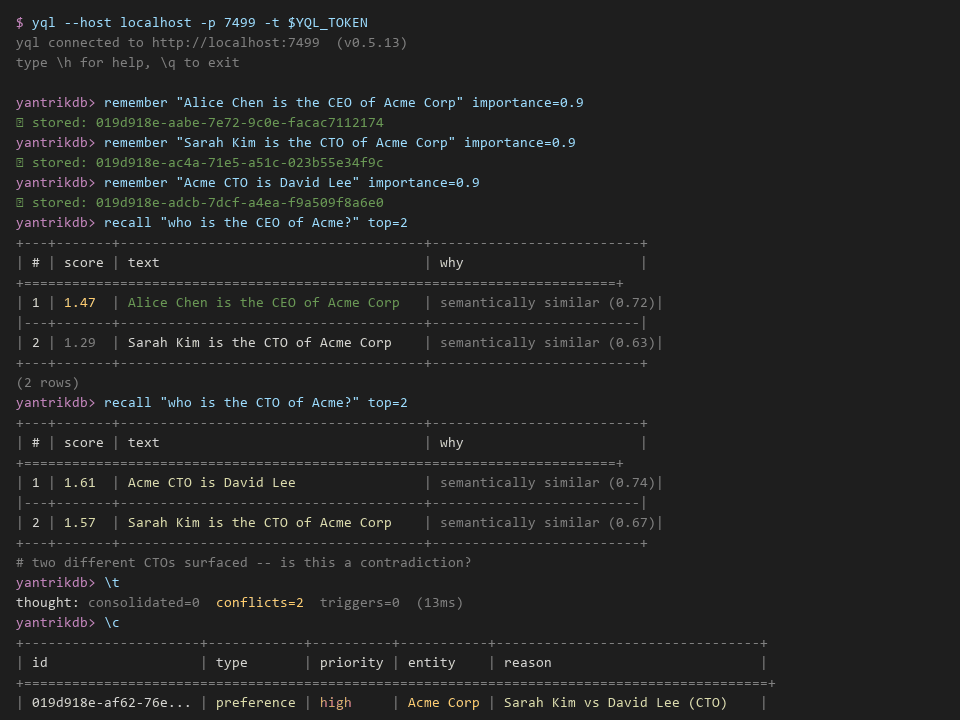
When memories contradict, YantrikDB doesn't guess — it creates a conflict segment:
"works at Google" (recorded Jan 15) vs. "works at Meta" (recorded Mar 1)
→ Conflict: identity_fact, priority: high, strategy: ask_user
Resolution is conversational: the AI asks naturally, not programmatically.
After many conversations, memories pile up. think() runs:
The engine generates triggers when it detects something worth reaching out about:
Every trigger is grounded in real memory data — not engagement farming.
Local-first with append-only replication log:
sid = db.session_start("default", "claude-code")
db.record("decided to use PostgreSQL") # auto-linked to session
db.record("Alice suggested Redis for caching")
db.session_end(sid)
# → computes: memory_count, avg_valence, topics, duration
db.stale(days=14) # high-importance memories not accessed recently
db.upcoming(days=7) # memories with approaching deadlines
| Operation | Methods |
|---|---|
| Core | record, record_batch, recall, recall_with_response, recall_refine, forget, correct |
| Knowledge Graph | relate, get_edges, search_entities, entity_profile, relationship_depth, link_memory_entity |
| Cognition | think, get_patterns, scan_conflicts, resolve_conflict, derive_personality |
| Triggers | get_pending_triggers, acknowledge_trigger, deliver_trigger, act_on_trigger, dismiss_trigger |
| Sessions | session_start, session_end, session_history, active_session, session_abandon_stale |
| Temporal | stale, upcoming |
| Procedural | record_procedural, surface_procedural, reinforce_procedural |
| Lifecycle | archive, hydrate, decay, evict, list_memories, stats |
| Sync | extract_ops_since, apply_ops, get_peer_watermark, set_peer_watermark |
| Maintenance | rebuild_vec_index, rebuild_graph_index, learned_weights |
| Decision | Choice | Rationale |
|---|---|---|
| Core language | Rust | Memory safety, no GC, ideal for embedded engines |
| Architecture | Embedded (like SQLite) | No server overhead, sub-ms reads, single-tenant |
| Bindings | Python (PyO3), TypeScript | Agent/AI layer integration |
| Storage | Single file per user | Portable, backupable, no infrastructure |
| Sync | CRDTs + append-only log | Conflict-free for most operations, deterministic |
| Thread safety | Mutex/RwLock, Send+Sync | Safe concurrent access from multiple threads |
| Query interface | Cognitive operations API | Not SQL — designed for how agents think |
| Package | What | Install | Source |
|---|---|---|---|
| yantrikdb-mcp | MCP server for Claude Code / Cursor / Windsurf — start here | pip install yantrikdb-mcp | GitHub · PyPI |
| yantrikdb-client | Python client SDK for the HTTP server (typed memory, reflect, character primitives) | pip install yantrikdb-client | GitHub · PyPI |
| yantrikdb-server | HTTP + wire-protocol server, HA cluster | docker run ghcr.io/yantrikos/yantrikdb | GitHub |
| yantrikdb (Rust) | Embedded Rust engine | cargo add yantrikdb | GitHub |
| yantrikdb (Python) | Python bindings via PyO3 | pip install yantrikdb | GitHub |
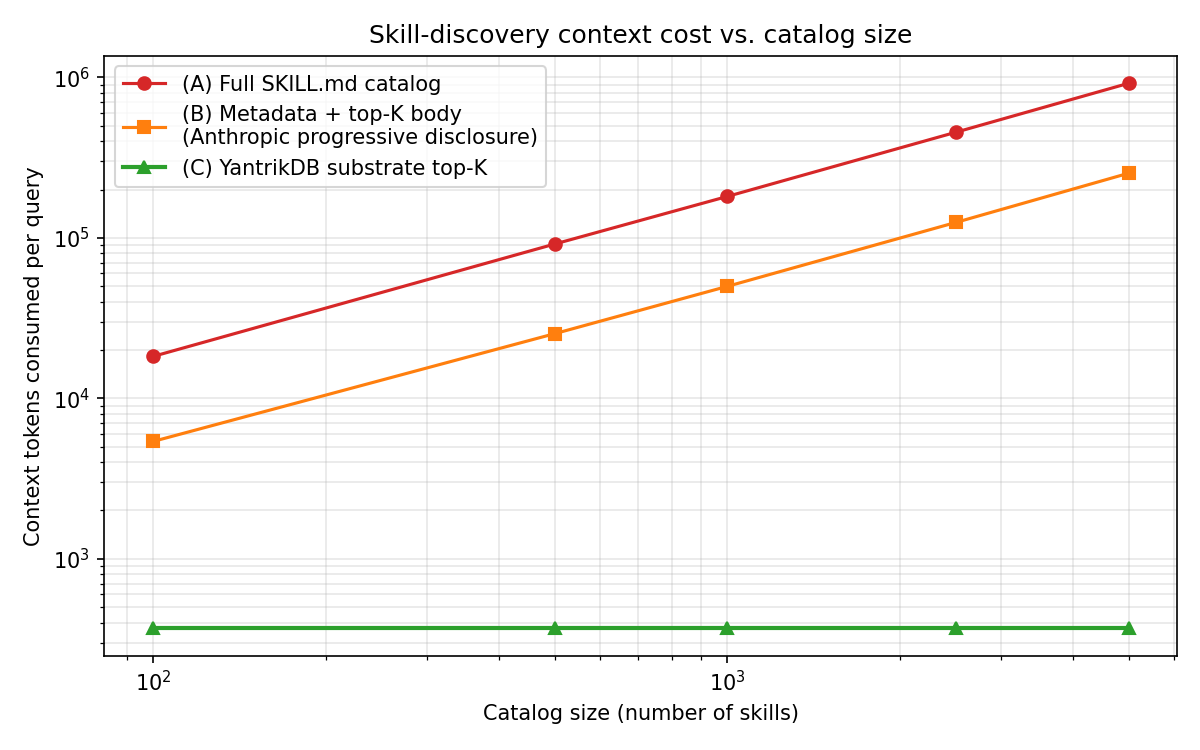
A measurement paper on what happens when LLM agent skill catalogs scale. On a 5,000-skill corpus:
Three failure modes for filesystem-shaped skill catalogs (token burn, slowdown, invalid-skill admission). One unifying framing: skill catalogs for autonomous learning aren't documents; they're memory.
Code + scripts + raw CSVs are reproducible at benchmarks/skill_recall/. Full deposit (PDF + source + data + scripts) on Zenodo. Companion blog post: yantrikdb.com/papers/skill-substrate.
Pranab Sarkar — ORCID · LinkedIn · developer@pranab.co.in
AGPL-3.0. See LICENSE for the full text.
The MCP server is MIT-licensed — using the engine via the MCP server does not trigger AGPL obligations on your code.
Official MongoDB integration — query collections, run aggregations, inspect schemas
Secure MCP server for MySQL database interaction, queries, and schema management
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Run Claude Code as an MCP server so any agent can delegate coding tasks to it