

Are you the author? Sign in to claim
AI semantic search for Zotero, with a built-in MCP server for AI agents (Claude Code, Codex). Find papers by meaning. 10
Find similar papers by meaning, not just keywords. 100% local, no data leaves your machine. Now with a built-in MCP server for AI agents.
Status: ✅ Stable release · Zotero 8 & 9 · Transformers.js running locally
New: 🤖 MCP server built in — Claude Code, Codex, and any MCP client can search your library and cite papers with links that open straight to the matched PDF page. Fully local, read-only, opt-in. Set it up in one line →
zotseek-exclude to skip them during indexingZotSeek is designed with privacy as a core principle:
| Aspect | Guarantee |
|---|---|
| AI Model | Bundled with the plugin (131MB) — no downloads, no API calls |
| Processing | All AI inference runs locally on your CPU/GPU |
| Your Papers | Only indexes items from your local Zotero library |
| Network | Zero network requests for search or indexing |
| Storage | Embeddings saved locally in zotseek.sqlite in your Zotero data folder |
| Offline | Works completely offline after installation |
What this means:
flowchart TD
subgraph INDEX["1️⃣ INDEX"]
A[📄 Paper] --> B[🤖 AI Model] --> C[768 numbers]
end
subgraph SEARCH["2️⃣ SEARCH"]
D[🔍 Query] --> E[Query → 768 numbers]
E --> F{Compare all papers}
F --> G[📊 Ranked results]
end
C -.->|stored| F
How it works: Each paper becomes 768 numbers capturing its meaning. To search, we convert your query to numbers and find papers with similar numbers.
When you use "Index Current Collection" or "Update Library Index":
For each paper:
1. Extract title + abstract (Abstract mode)
— OR —
Extract PDF text page-by-page with exact page numbers (Full Document mode)
2. Split into paragraphs, filter out References/Bibliography
3. Send to local AI model (nomic-embed-text-v1.5)
4. Model outputs 768 numbers per chunk (the "embedding")
5. Save embeddings + location metadata to local database (zotseek.sqlite)
Time: ~3 seconds per chunk
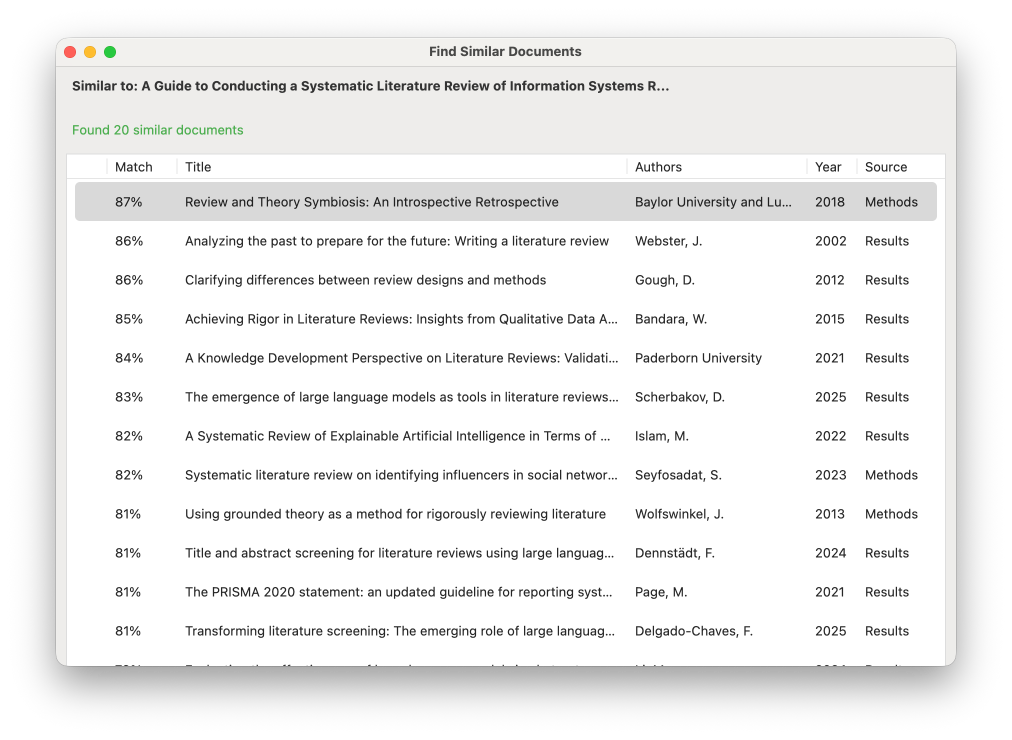
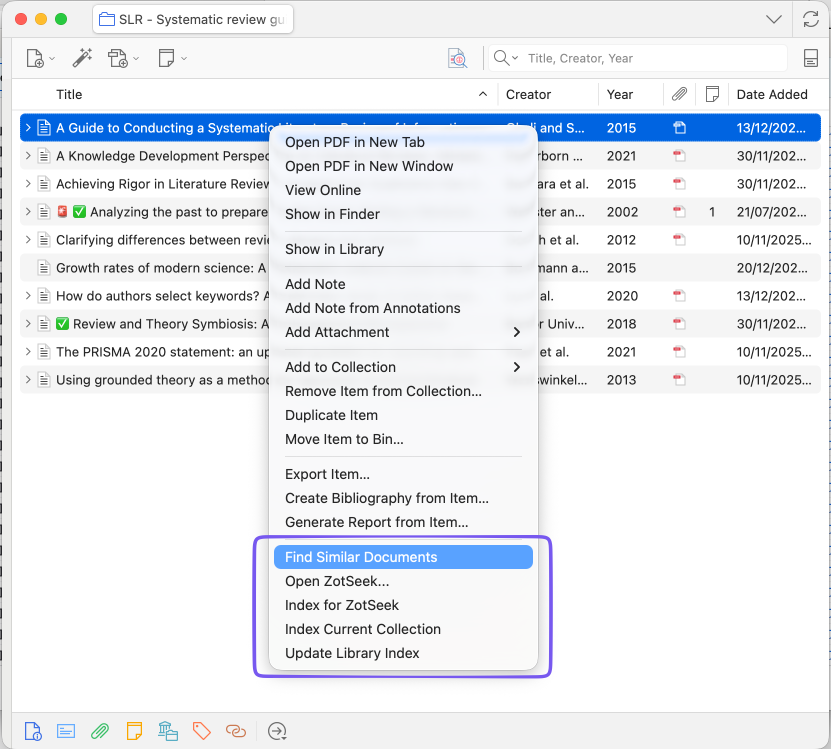
When you right-click → "Find Similar Documents":
1. Load the selected paper's embedding
2. Compare against all indexed papers (cached in memory)
3. Rank by semantic similarity
4. Show top results
Time: ~70ms (with cache)
The plugin combines semantic search (AI embeddings) with Zotero's keyword search using Reciprocal Rank Fusion (RRF) for optimal results.
| Mode | Best For | How It Works |
|---|---|---|
| 🔗 Hybrid (Recommended) | Most searches | Combines semantic + keyword results |
| 🧠 Semantic Only | Conceptual queries | Finds related papers by meaning |
| 🔤 Keyword Only | Author/year searches | Exact title, author, year matching |
| Query Type | Pure Semantic | Pure Keyword | Hybrid |
|---|---|---|---|
| "trust in AI" | ✅ Great | ❌ Poor | ✅ Great |
| "Smith 2023" | ❌ Poor | ✅ Great | ✅ Great |
| "RLHF" | ⚠️ Maybe | ✅ Exact only | ✅ Both |
| Icon | Meaning |
|---|---|
| 🔗 | Found by BOTH semantic and keyword (high confidence) |
| 🧠 | Found by semantic search only (conceptually related) |
| 🔤 | Found by keyword search only (exact match) |
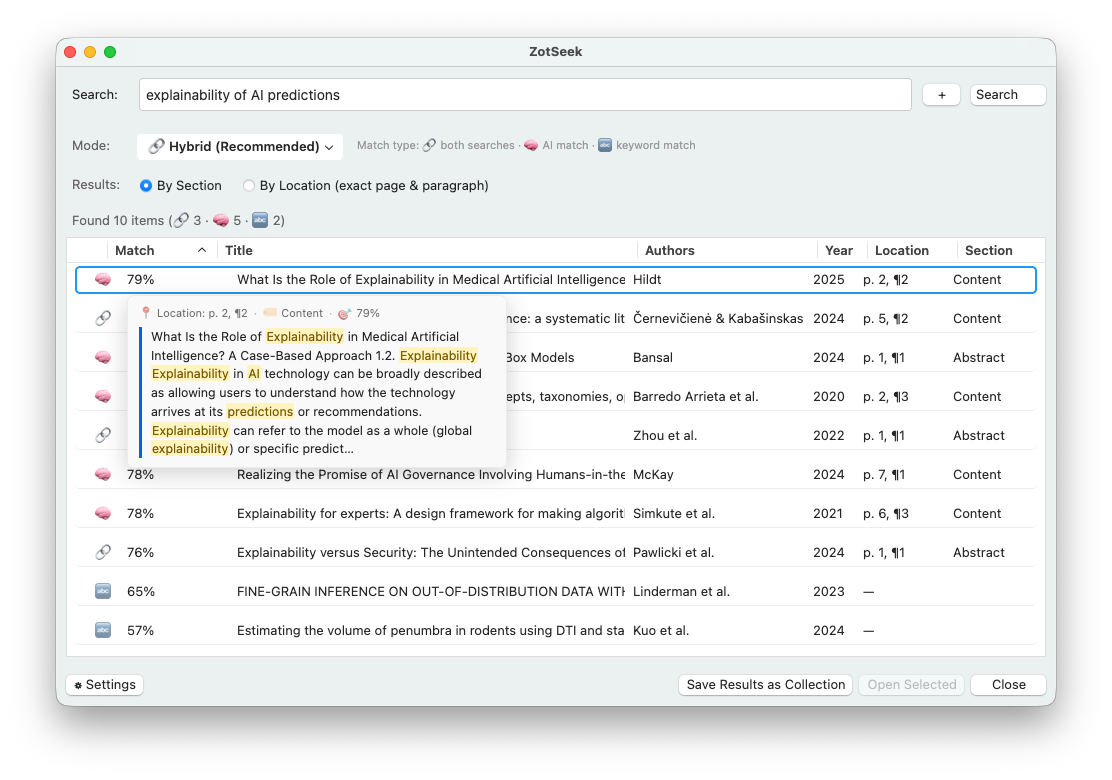
The Source column shows which section of the paper matched your query:
| Source | Section Type |
|---|---|
| Abstract | Title + Abstract |
| Methods | Introduction, Background, Methods |
| Results | Results, Discussion, Conclusions |
| Content | Generic (sections not detected) |
Hover any result row to see a tooltip with the exact passage that matched your query, along with its location (page & paragraph), section type, and match score. This lets you judge whether a result is relevant without opening the paper. In Keyword and Hybrid searches the query terms are highlighted inside the passage, and the preview is centered on the first match so the relevant text is always in view. (Pure semantic search has no literal terms to highlight, so the passage is shown without highlighting.)
When using Full Document indexing mode, you can toggle between two result views:
| Mode | Results | Best For |
|---|---|---|
| By Section (default) | 1 result per paper, best matching section, with the location of that match | Overview of matching papers |
| By Location | Every matching paragraph with exact page & paragraph | Finding specific passages |
By Section - Aggregates all chunks per paper and shows the highest-scoring match. The Location column shows where that best match was found (page & paragraph), so you get one diverse result per paper without losing the exact location:
By Location - Returns every matching paragraph individually with its own score:
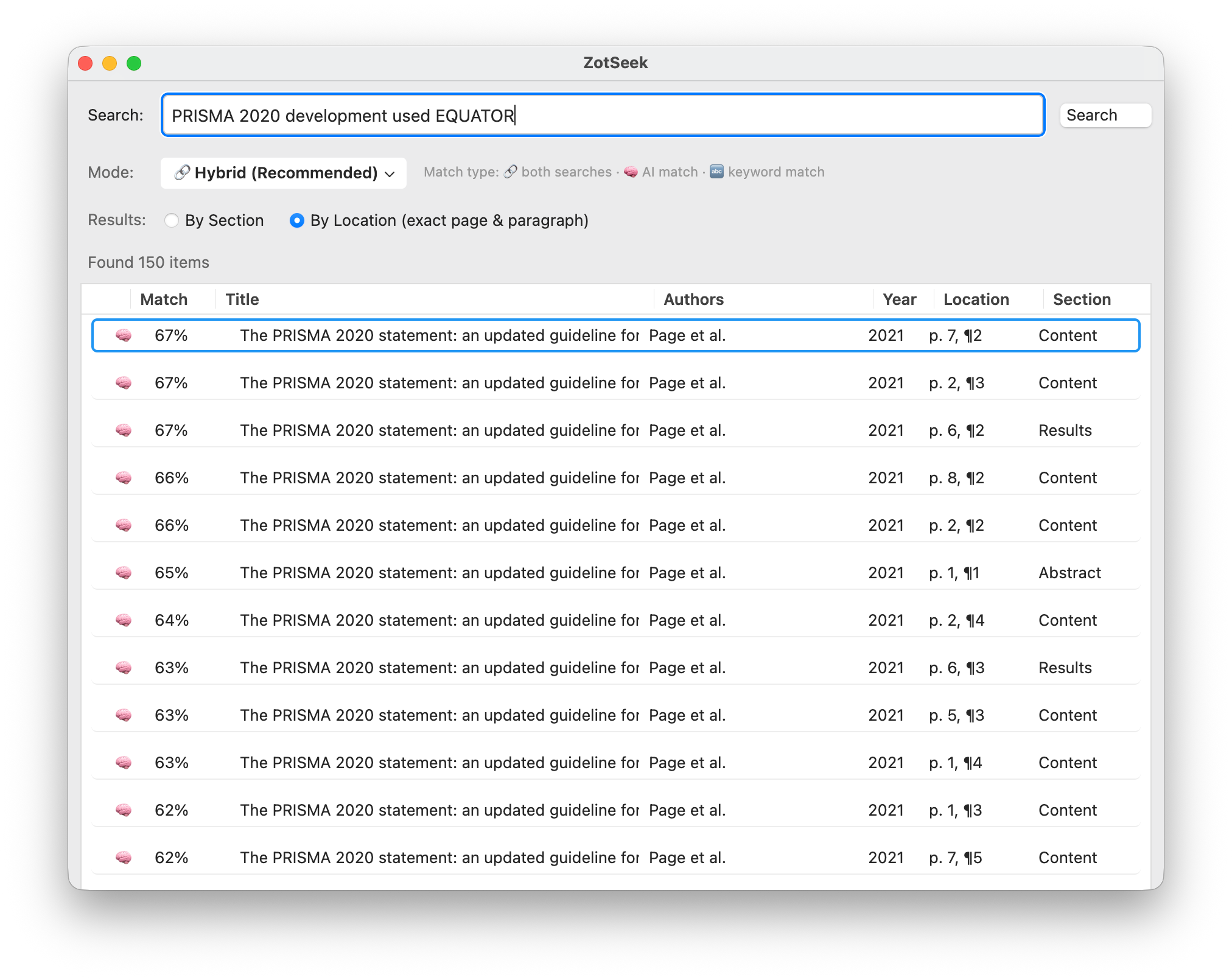
In By Location mode, clicking a result opens the PDF to the exact page where the match was found.
Combine up to 4 search queries to find papers at the intersection of multiple topics:
| Operator | Behavior | Best For |
|---|---|---|
| AND | Papers must match ALL queries | Finding topic intersections |
| OR | Papers can match ANY query | Broadening search with synonyms |
| AND Formula | How It Works | Use When |
|---|---|---|
| Minimum (default) | Uses lowest score across queries | You want strict intersection |
| Product | Geometric mean of scores | Balanced relevance across all queries |
| Average | Arithmetic mean of scores | More lenient matching |
Example: Search for papers about "machine learning" AND "healthcare" AND "ethics" to find AI ethics papers specifically in the medical domain.
Match column with multiple queries: Shows combined score plus individual per-query scores:
73% (77|73|68) = 73% combined, with 77% for Q1, 73% for Q2, 68% for Q3For technical details, see docs/SEARCH_ARCHITECTURE.md.
| Mode | What Gets Indexed | Best For |
|---|---|---|
| Abstract | Title + Abstract | Fast indexing, quick setup |
| Full Document (default) | PDF content split by sections | Deep content search, better results |
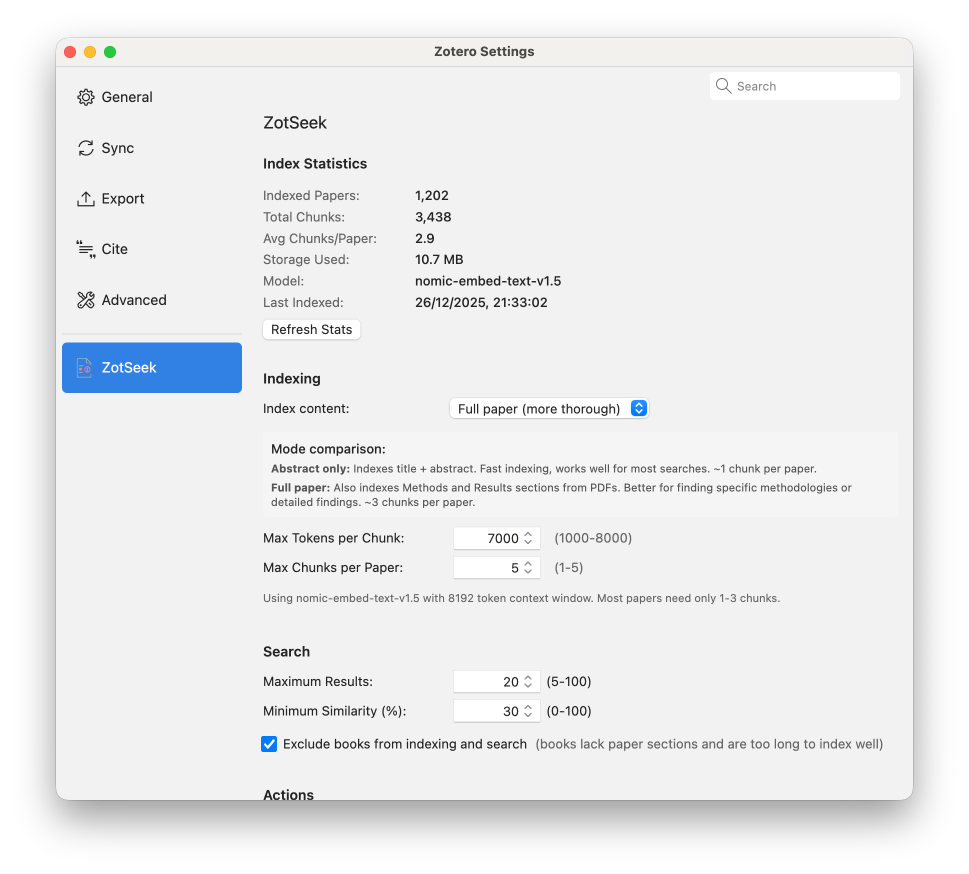
Configure via Zotero → Settings → ZotSeek.
For papers with PDFs, the chunker:
When searching, if any chunk matches your query, the paper ranks highly (MaxSim aggregation in "By Section" mode).
The chunker automatically detects and excludes bibliography sections:
[1], Smith, J. (2021)., DOI linksThis keeps your search results focused on the actual content of papers.
The maxTokens setting controls how text is split for embedding. It's a ceiling, not a target — chunks are split at paragraph boundaries and may be smaller.
| Chunk Size | Speed | Search Behavior |
|---|---|---|
| 500-800 | Fast (~0.5s/chunk) | Higher precision, finds specific passages |
| 2000 | Moderate (~3s/chunk) | Balanced (default) |
| 4000+ | Slow | Higher recall, finds broad topics |
Default: 2000 tokens. Firefox 140+ handles larger chunks efficiently.
Recommendations:
For detailed chunking documentation, see docs/SEARCH_ARCHITECTURE.md.
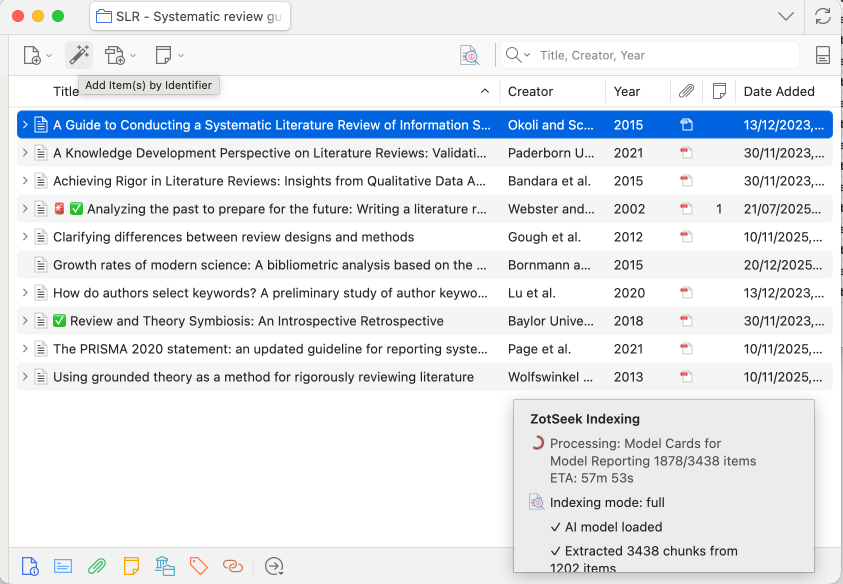
ZotSeek adds a "ZotSeek" column to the Zotero item list so you can see at a glance how each paper has been indexed. The first time you install this version the column appears automatically; you can hide or reorder it from the column-header menu like any other Zotero column.
| Glyph | Meaning |
|---|---|
✓ | Fully indexed |
◐ | Partial — the paper hit the Max Chunks per Paper limit and only part of its content is in the index. Raise the limit or switch to Abstract mode to capture the full text. |
↻ | Out of date — the item was modified after it was indexed. Re-index to refresh. |
⊘ | Excluded — the item carries the zotseek-exclude tag. |
| (empty) | Not indexed. |
After indexing, a one-line summary in the progress window also warns when any paper hit the chunk limit, and the same warning is written to the debug log per affected paper.
| Property | Value |
|---|---|
| Name | nomic-ai/nomic-embed-text-v1.5 |
| Size | 131 MB (quantized) |
| Dimensions | 768 (Matryoshka - can truncate to 256/128) |
| Context Window | 8192 tokens |
| Speed | ~3 seconds per chunk |
| Quality | Outperforms OpenAI text-embedding-3-small on MTEB |
| Special Feature | Instruction-aware prefixes for queries vs documents |
search_document: for indexing and search_query: for queriesThe model converts text into 768 numbers that capture semantic meaning:
"Machine learning for medical diagnosis" → [0.023, -0.045, 0.012, ...]
"AI in healthcare applications" → [0.021, -0.048, 0.015, ...] ← Similar!
"Organic chemistry synthesis" → [-0.089, 0.034, 0.067, ...] ← Different!
Papers with similar meanings have similar numbers, even if they use different words.
flowchart LR
subgraph Main["Main Thread"]
A[Plugin] <--> B[(SQLite)]
A <--> C[Search]
end
subgraph Worker["ChromeWorker"]
D[Transformers.js]
E[nomic-embed-v1.5]
end
A -->|text| Worker
Worker -->|embeddings| A
Transformers.js can't run directly in Zotero's main thread because:
self, navigator, indexedDB)Solution: Run in a separate ChromeWorker thread with special configuration.
Embeddings are stored in a separate SQLite database (zotseek.sqlite) attached to Zotero's connection:
<Zotero Data Directory>/zotseek.sqliteThe SQLite backend uses the ATTACH DATABASE pattern (inspired by Better BibTeX):
columnQueryAsync() and valueQueryAsync() for robust data retrievalZotSeek stores its embeddings in zotseek.sqlite inside your Zotero data directory. The file is local and is not synced by Zotero's built-in sync.
If you use Zotero on multiple machines and want to avoid re-indexing your library on each one, you can copy the file manually:
zotseek.sqlite from one machine to the other.The plugin identifies items by Zotero's stable item keys (the same identifiers visible in the Zotero web API), so the database works correctly regardless of which machine indexed the items.
Notes:
The math behind "how similar are two papers":
$$\text{similarity} = \frac{A \cdot B}{|A| \times |B|}$$
Where:
Result: 0.0 (completely different) to 1.0 (identical)
Interpretation:
ZotSeek can let Claude Code and other MCP clients search your library semantically, so an agent can find relevant papers and cite them with links that open straight to the right page in Zotero. Each result carries zotero:// deep links: one opens the item, one opens its PDF at the exact page that matched your query.
What this enables — real workflows from a thesis-writing session:
[citation needed] → the agent hunts your library for sources that actually support each claim and flags the ones nothing supports.It runs entirely on your machine and is opt-in (off by default). Enable it in Settings → ZotSeek → AI Agent Access, make sure Zotero's local HTTP server is allowed (Settings → Advanced), then connect Claude Code with:
claude mcp add --transport http --scope user zotseek http://localhost:23119/zotseek/mcp
The same searches are also available as plain REST endpoints for scripts. Everything is read-only — nothing can modify your library or index. See docs/MCP.md for the full setup, tool reference, REST API, and security notes.
Requirements: Zotero 8.0 or newer (Zotero 9.0 supported).
zotseek-X.Y.Z.xpi from the Releases page..xpi file.After installation, ZotSeek is ready to use — open Zotero → Settings → ZotSeek to configure it, then right-click a collection and choose "Update Library Index" to build your index.
Updating: ZotSeek checks for updates automatically. New releases are delivered through Zotero's built-in plugin update mechanism, so you'll be notified when a new version is available.
# Clone the repository
git clone https://github.com/introfini/ZotSeek
cd zotseek
# Install dependencies (includes zotero-plugin-toolkit for stable progress windows)
npm install
# Build the plugin
npm run build
# Create extension proxy file (macOS)
echo "$(pwd)/build" > ~/Library/Application\ Support/Zotero/Profiles/*.default/extensions/zotseek@zotero.org
# Restart Zotero with debug console
open -a Zotero --args -purgecaches -ZoteroDebugText -jsconsole
npm run release
The interactive release script bumps the version, syncs manifest.json and update.json, rebuilds, and packages zotseek-X.Y.Z.xpi at the project root.
Crash-Resilient Indexing:
Progress Window Features:
Every ZotSeek search result set can be saved into a Zotero collection so you can come back to the same list later without re-running the search:
The modal pre-fills a sensible name (your query + today's date, e.g. ZotSeek: "machine learning" · 2026-04-21) that you can edit. A live status line shows N items → My Library so you know where the collection will land.
New collections are created at the target library's root. If you want them in a specific subfolder, drag them from Zotero's sidebar after the export — faster and more flexible than a dropdown.
When search results span multiple libraries (for example, your personal library and a group library), a Library dropdown appears so you can pick which library receives the new collection. Items in other libraries are reported as skipped in the confirmation status.
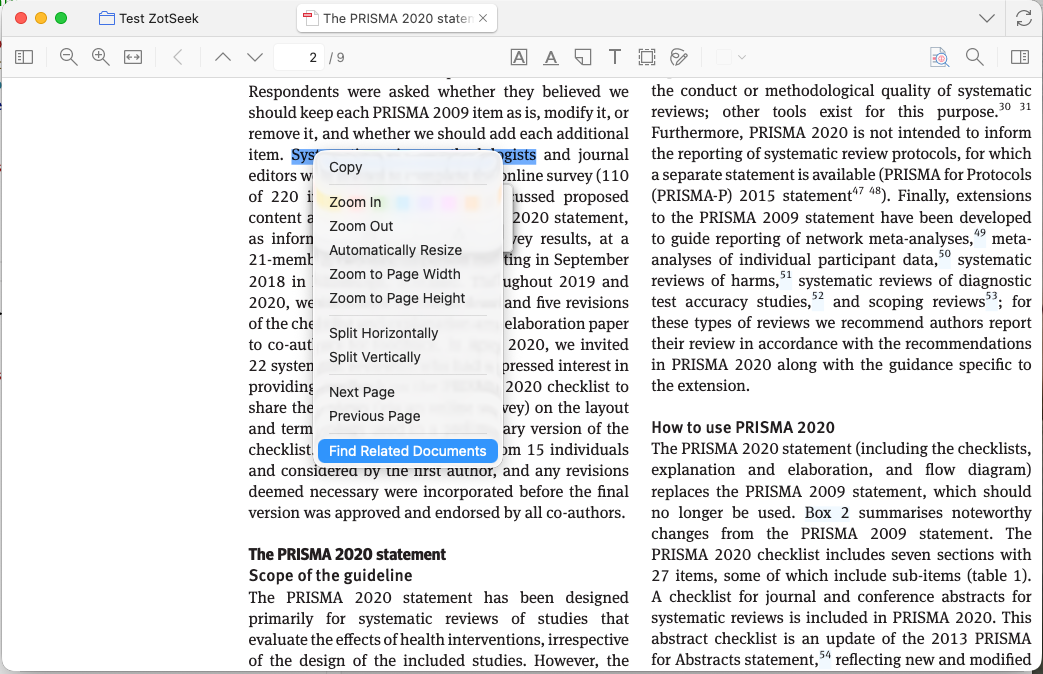
While reading a PDF, you can search for related documents based on selected text:
This is useful for:
ZotSeek can automatically index papers as you add them to your library:
How it works:
Configuring the delay: Go to Zotero Settings > ZotSeek and adjust the Auto-index delay slider (1-300 seconds). Longer delays are useful when importing large batches via browser connector or RSS feeds.
Automatic cleanup: When you delete or trash items in Zotero, their embeddings are automatically removed from the ZotSeek index. This prevents ghost search results and keeps the index clean — no action needed on your part.
Manual removal: To remove specific items from the index without deleting them:
This is useful when you want to re-index specific items (e.g., after updating a PDF), or to exclude items from search results without deleting them from your library.
You can prevent specific items from being indexed by tagging them:
zotseek-exclude (or your custom tag name)Customizing the tag name: Go to Zotero → Settings → ZotSeek → Advanced Settings and change the Exclude tag field. Leave it empty to disable tag-based exclusion.
Tip: Use Zotero's advanced search (Edit → Advanced Search) to find items by title, type, collection, etc., then bulk-tag them. This is more flexible than regex-based filtering since it leverages Zotero's native search capabilities.
Select multiple items in the ZotSeek search results:
Help → Debug Output Logging → View Output
Look for [ZotSeek] entries.
Access settings via Zotero → Settings → ZotSeek (or Zotero → Preferences on macOS).
The settings panel allows you to configure:
Preferences are stored in Zotero's preferences system:
Search Settings:
| Preference | Default | Description |
|---|---|---|
zotseek.minSimilarityPercent | 30 | Minimum similarity % to show in results |
zotseek.topK | 20 | Maximum number of results |
zotseek.autoIndex | false | Automatically index new papers when added |
zotseek.autoIndexDelay | 10 | Seconds to wait after last item before auto-indexing (1-300) |
Indexing Settings:
| Preference | Default | Description |
|---|---|---|
zotseek.indexingMode | "full" | "abstract" or "full" |
zotseek.maxTokens | 2000 | Max tokens per chunk |
zotseek.maxChunksPerPaper | 100 | Max chunks per paper |
zotseek.excludeBooks | true | Skip books during indexing |
zotseek.excludeTag | "zotseek-exclude" | Tag name to skip items during indexing (empty to disable) |
Hybrid Search Settings:
| Preference | Default | Description |
|---|---|---|
zotseek.hybridSearch.enabled | true | Enable hybrid search |
zotseek.hybridSearch.mode | "hybrid" | "hybrid", "semantic", or "keyword" |
zotseek.hybridSearch.semanticWeightPercent | 50 | Semantic weight (0-100) |
zotseek.hybridSearch.rrfK | 60 | RRF constant |
zotseek.hybridSearch.autoAdjustWeights | true | Auto-adjust based on query |
You can also access preferences via about:config (Help → Debug Output Logging → View Output, then navigate to about:config).
Tested on MacBook Pro M3:
| Operation | Time |
|---|---|
| Model loading | ~1.5 seconds (bundled, 131MB) |
| Index 1 chunk | ~3 seconds (optimized from ~45s) |
| Index 10 papers (40 chunks) | ~2 minutes |
| First search | ~130ms (loads cache) |
| Subsequent searches | ~70ms (uses cache) |
| Hybrid search | ~70ms (with cache) |
| Storage size | ~130 KB per 10 papers (full mode) |
| Memory usage (cached) | +75MB for 1,000 papers |
The plugin includes several performance optimizations:
columnQueryAsync() and valueQueryAsync()ZotSeek automatically detects and uses WebGPU for GPU-accelerated embeddings when available:
| Backend | When Used | Speed |
|---|---|---|
| WebGPU (GPU) | If browser/Zotero supports WebGPU | Up to 10-20x faster |
| WASM (CPU) | Fallback when WebGPU unavailable | ~3 seconds per chunk |
Current status (April 2026):
When will GPU work? Once Zotero upgrades to a Firefox ESR with WebGPU support for your platform, GPU acceleration will automatically activate — no plugin update needed.
Check if GPU is being used: Look for "Model loaded on GPU" or "Model loaded on CPU" in Zotero's debug console (Help → Debug Output Logging → View Output).
Note: If WebGPU is unavailable or fails, the plugin automatically falls back to CPU without interruption.
| Feature | This Plugin (Local) | OpenAI API |
|---|---|---|
| Cost | Free | ~$0.02 per 1K papers |
| Privacy | 100% local | Data sent to OpenAI |
| Offline | Yes (after model loads) | No |
| Quality | Excellent (outperforms text-embedding-3-small) | Good |
| Speed | ~70-130ms | ~100ms |
| Context | 8192 tokens | 8191 tokens |
See the docs/ folder for detailed documentation:
See CHANGELOG.md for version history.
MIT License - see LICENSE
ZotSeek: AI-Powered Semantic Search for Zotero — Built by José Fernandes
Run Claude Code as an MCP server so any agent can delegate coding tasks to it
Browser automation using accessibility snapshots instead of screenshots
Google's universal MCP server supporting PostgreSQL, MySQL, MongoDB, Redis, and 10+ databases
Official GitHub integration for repos, issues, PRs, and CI/CD workflows